
SparkStreaming通過Kafka獲取資料(Receiver方式)
1、通過O(1)的磁碟資料結構提供訊息的持久化,這種結構對於即使數以TB的訊息儲存也能夠保持長時間的穩定效能。
2、高吞吐量:即使是非常普通的硬體Kafka也可以支援每秒數百萬的訊息。
3、支援通過Kafka伺服器和消費機叢集來分割槽訊息。
4、支援Hadoop並行資料載入。相關術語介紹:
Broker
Kafka叢集包含一個或多個伺服器,這種伺服器被稱為broker[5]
Topic
每條釋出到Kafka叢集的訊息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的訊息分開儲存,邏輯上一個Topic的訊息雖然保存於一個或多個broker上但使用者只需指定訊息的Topic即可生產或消費資料而不必關心資料存於何處)
Partition
Partition是物理上的概念,每個Topic包含一個或多個Partition.
Producer
負責釋出訊息到Kafka broker
Consumer
訊息消費者,向Kafka broker讀取訊息的客戶端。
Consumer Group
每個Consumer屬於一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬於預設的group)。執行環境準備
JDK1.8
3臺伺服器:(CentOS 7.3)
192.168.119.51 hadoop001
192.168.119.52 hadoop002
192.168.119.53 hadoop003
1、安裝zookeeper3.4.10
下載zookeeper,
wget http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.10.tar.gz
解壓,tar -zxvf zookeeper-3.4.10.tar.gz
mv命令重新命名資料夾,改名為zookeeper。
修改配置檔案
進入到解壓好的目錄裡面的conf目錄中,cd /home/hadoop/app/zookeeper/conf
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/data/zookeeper/zkdata dataLogDir=/home/hadoop/data/zookeeper/zkdatalog clientPort=2181 server.1=192.168.119.51:2888:3888 server.2=192.168.119.52:2888:3888 server.3=192.168.119.53:2888:3888
建立myid檔案
#hadoop001
echo "1" > /home/hadoop/data/zookeeper/zkdata/myid
#hadoop002
echo "2" > /home/hadoop/data/zookeeper/zkdata/myid
#hadoop003
echo "3" > /home/hadoop/data/zookeeper/zkdata/myid
重要配置說明
1、myid檔案和server.myid 在快照目錄下存放的標識本臺伺服器的檔案,他是整個zk叢集用來發現彼此的一個重要標識。
2、zoo.cfg 檔案是zookeeper配置檔案 在conf目錄裡。
3、log4j.properties檔案是zk的日誌輸出檔案 在conf目錄裡用java寫的程式基本上有個共同點日誌都用log4j,來進行管理。
4、zkEnv.sh和zkServer.sh檔案
zkServer.sh 主的管理程式檔案
zkEnv.sh 是主要配置,zookeeper叢集啟動時配置環境變數的檔案
5、還有一個需要注意
ZooKeeper server will not remove old snapshots and log files when using the default configuration (see autopurge below), this is the responsibility of the operator
zookeeper不會主動的清除舊的快照和日誌檔案,這個是操作者的責任。
啟動zookeeper服務並檢視
1、啟動服務
#進入到Zookeeper的bin目錄下
/zookeeper/bin
#啟動服務(3臺都需要操作)
./zkServer.sh start
2、檢查服務狀態
#檢查伺服器狀態
./zkServer.sh status
啟動成功後jps檢視程序
[[email protected] conf]$ jps
1988 Jps
1287 QuorumPeerMain
說明zookeeper啟動成功。
2、安裝kafka0.11
下載壓縮包,解壓,重新命名資料夾,進入資料夾的config目錄
修改server.properties配置檔案,三臺機器配置相應修改。
broker.id分別修改為 broker.id=0,broker.id=1,broker.id=2,
host.name 為各機器的IP地址,分別改為192.168.119.51,192.168.119.52,192.168.119.53
分別在後臺啟動kafka的三個節點:
/home/hadoop/app/kafka/bin/kafka-server-start.sh /home/hadoop/app/kafka/config/server.properties >/dev/null 2>&1 &
jps檢視程序啟動情況:
[[email protected] conf]$ jps
1360 Kafka
1988 Jps
1287 QuorumPeerMain
有kafka程序,說明啟動成功。
3、編寫程式,從kafka採集資料
pom.xml檔案中新增依賴
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.1</version>
</dependency>編寫程式:
package cn.allengao.stream
import org.apache.log4j.{Logger, Level}
import org.apache.spark.Logging
object LoggerLevels extends Logging {
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}package cn.allengao.stream
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* class_name:
* package:
* describe: sparkstreaming從kafka讀取資料
* creat_user: Allen Gao
* creat_date: 2018/2/12
* creat_time: 17:20
**/
object KafkaWordCount {
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(i => (x, i)) }
}
def main(args: Array[String]) {
LoggerLevels.setStreamingLogLevels()
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
ssc.checkpoint("j://ck2")
//"alog-2018-02-10,alog-2016-02-11,alog-2018-02-12"
//"Array((alog-2018-02-10, 2), (alog-2016-02-11, 2), (alog-2018-02-12, 2))"
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val data = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap, StorageLevel.MEMORY_AND_DISK_SER)
val words = data.map(_._2).flatMap(_.split(" "))
val wordCounts = words.map((_, 1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}配置執行引數:
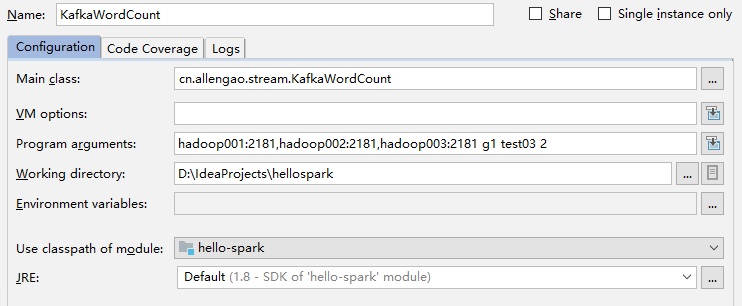
這樣,就建立了一個名為test03的topic。
在任一臺機器執行命令:
bin/kafka-console-producer.sh --broker-list 192.168.119.51:9092 --topic test03
生產者開始生產資料
>hello tom hello jerry hello java hello
在idea中可以看到如下結果:
-------------------------------------------
Time: 1518424550000 ms
-------------------------------------------
(tom,1)
(hello,4)
(java,1)
(jerry,1)
說明SparkStreaming和kafka的連線通訊成功。