
windows下執行spark程式
阿新 • • 發佈:2018-12-25
linux普通使用者開發spark程式時,由於無法使用IDEA的圖形化操作介面,所以只能大包圍jar,用spark-submit提交,不是很方便, spark的local模式可以方便開發者在本地除錯程式碼,而不用打包為jar用spark-submit提交執行,或是在spark-shell中逐行執行,下面是在windows上執行sparkPi的程式碼及結果
package com
import scala.math.random
import org.apache.spark._
object localSpark {
def main(args: Array[String]) {
val conf=new SparkConf().setMaster 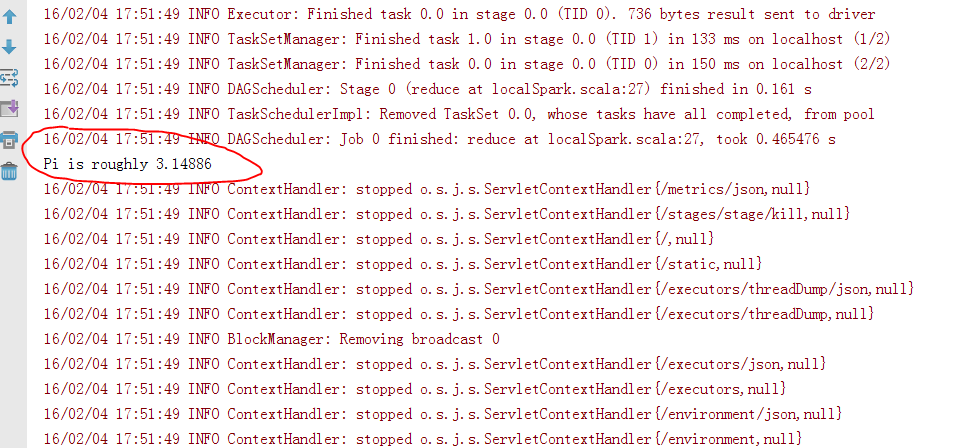
sbt檔案的配置為
name := "SparkLocal"
version := "1.0"
scalaVersion := "2.10.4"
libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.3.0"注意點:
1.設定setMaster(“local[3]”),local的引數必須大於2,一個用作drive,剩下的作為worker
2.windows上沒有安裝hadoop,所以spark的依賴包採用的spark-core,即只有spark的核心程式碼,不包含hadoop的配置,所以程式碼中不能讀取hdfs的資料
3.spark-core的版本採用1.5或更高的版本的時候,相關的依賴包下載總是報錯,建議採用1.3版本