
spark相關面試題總結
(根據部落格總結並不斷增加自己的內容)
1.spark中的RDD是什麼,有哪些特性?
答:RDD(Resilient Distributed Dataset)叫做分散式資料集,是spark中最基本的資料抽象,它代表一個不可變,可分割槽,裡面的元素可以平行計算的集合
Dataset:就是一個集合,用於存放資料的
Destributed:分散式,可以並行在叢集計算
Resilient:表示彈性的,彈性表示
1.RDD中的資料可以儲存在記憶體或者磁碟中;
2.RDD中的分割槽是可以改變的;
五大特性:
1.A list of partitions:一個分割槽列表,RDD中的資料都儲存在一個分割槽列表中
2.A function for computing each split:作用在每一個分割槽中的函式
3.A list of dependencies on other RDDs:一個RDD依賴於其他多個RDD,這個點很重要,RDD的容錯機制就是依據這個特性而來的
4.Optionally,a Partitioner for key-value RDDs(eg:to say that the RDD is hash-partitioned):可選的,針對於kv型別的RDD才有這個特性,作用是決定了資料的來源以及資料處理後的去向
5.可選項,資料本地性,資料位置最優
2.概述一下spark中的常用運算元區別(map,mapPartitions,foreach,foreachPatition)?
答:map:用於遍歷RDD,將函式應用於每一個元素,返回新的RDD(transformation運算元)
foreach:用於遍歷RDD,將函式應用於每一個元素,無返回值(action運算元)
mapPatitions:用於遍歷操作RDD中的每一個分割槽,返回生成一個新的RDD(transformation運算元)
foreachPatition:用於遍歷操作RDD中的每一個分割槽,無返回值(action運算元)
總結:一般使用mapPatitions和foreachPatition運算元比map和foreach更加高效,推薦使用
3.談談spark中的寬窄依賴?

答:RDD和它的父RDD的關係有兩種型別:窄依賴和寬依賴
寬依賴:指的是多個子RDD的Partition會依賴同一個父RDD的Partition,關係是一對多,父RDD的一個分割槽的資料去到子RDD的不同分割槽裡面,會有shuffle的產生
窄依賴:指的是每一個父RDD的Partition最多被子RDD的一個partition使用,是一對一的,也就是父RDD的一個分割槽去到了子RDD的一個分割槽中,這個過程沒有shuffle產生
區分的標準就是看父RDD的一個分割槽的資料的流向,要是流向一個partition的話就是窄依賴,否則就是寬依賴,如圖所示:
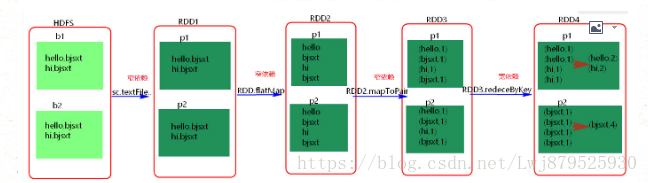
4.spark中如何劃分stage?
答:概念:Spark任務會根據RDD之間的依賴關係,形成一個DAG有向無環圖,DAG會提交給DAGScheduler,DAGScheduler會把DAG劃分相互依賴的多個stage,劃分依據就是寬窄依賴,遇到寬依賴就劃分stage,每個stage包含一個或多個task,然後將這些task以taskSet的形式提交給TaskScheduler執行,stage是由一組並行的task組成
1.spark程式中可以因為不同的action觸發眾多的job,一個程式中可以有很多的job,每一個job是由一個或者多個stage構成的,後面的stage依賴於前面的stage,也就是說只有前面依賴的stage計算完畢後,後面的stage才會執行;
2.stage 的劃分標準就是寬依賴:何時產生寬依賴就會產生一個新的stage,例如reduceByKey,groupByKey,join的運算元,會導致寬依賴的產生;
3.切割規則:從後往前,遇到寬依賴就切割stage;
4.圖解:

5.計算格式:pipeline管道計算模式,piepeline只是一種計算思想,一種模式
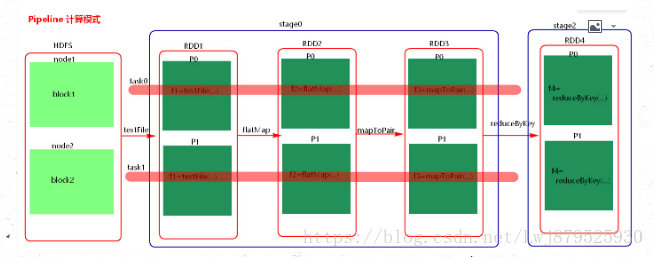
6.spark的pipeline管道計算模式相當於執行了一個高階函式,也就是說來一條資料然後計算一條資料,會把所有的邏輯走完,然後落地,而MapReduce是1+1=2,2+1=3這樣的計算模式,也就是計算完落地,然後再計算,然後再落地到磁碟或者記憶體,最後資料是落在計算節點上,按reduce的hash分割槽落地。管道計算模式完全基於記憶體計算,所以比MapReduce快的原因。
7.管道中的RDD何時落地shuffle write的時候,對RDD進行持久化的時候。
8.stage的task的並行度是由stage的最後一個RDD的分割槽數來決定的,一般來說,一個partition對應一個task,但最後reduce的時候可以手動改變reduce的個數,也就是改變最後一個RDD的分割槽數,也就改變了並行度。例如:reduceByKey(_+_,3)
9.優化 提高stage的並行度:reduceByKey(_+_,patition的個數) ,join(_+_,patition的個數)
10.DAGScheduler分析:
答:概述:是一個面向stage 的排程器;
主要入參有:dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, allowLocal,resultHandler, localProperties.get)
rdd: final RDD;
cleanedFunc: 計算每個分割槽的函式;
resultHander: 結果偵聽器;
主要功能:1.接受使用者提交的job;
2.將job根據型別劃分為不同的stage,記錄那些RDD,stage被物化,並在每一個stage內產生一系列的task,並封裝成taskset;
3.決定每個task的最佳位置,任務在資料所在節點上執行,並結合當前的快取情況,將taskSet提交給TaskScheduler;
4.重新提交shuffle輸出丟失的stage給taskScheduler;
注:一個stage內部的錯誤不是由shuffle輸出丟失造成的,DAGScheduler是不管的,由TaskScheduler負責嘗試重新提交task執行。
5.Job的生成:
答:一旦driver程式中出現action,就會生成一個job,比如count等,向DAGScheduler提交job,如果driver程式後面還有action,那麼其他action也會對應生成相應的job,所以,driver端有多少action就會提交多少job,這可能就是為什麼spark將driver程式稱為application而不是job 的原因。每一個job可能會包含一個或者多個stage,最後一個stage生成result,在提交job 的過程中,DAGScheduler會首先從後往前劃分stage,劃分的標準就是寬依賴,一旦遇到寬依賴就劃分,然後先提交沒有父階段的stage們,並在提交過程中,計算該stage的task數目以及型別,並提交具體的task,在這些無父階段的stage提交完之後,依賴該stage 的stage才會提交。
6.有向無環圖:
答:DAG,有向無環圖,簡單的來說,就是一個由頂點和有方向性的邊構成的圖中,從任意一個頂點出發,沒有任意一條路徑會將其帶回到出發點的頂點位置,為每個spark job計算具有依賴關係的多個stage任務階段,通常根據shuffle來劃分stage,如reduceByKey,groupByKey等涉及到shuffle的transformation就會產生新的stage ,然後將每個stage劃分為具體的一組任務,以TaskSets的形式提交給底層的任務排程模組來執行,其中不同stage之前的RDD為寬依賴關係,TaskScheduler任務排程模組負責具體啟動任務,監控和彙報任務執行情況。
7.RDD是什麼以及它的分類?

8.RDD的操作?










9.RDD快取?
Spark可以使用 persist 和 cache 方法將任意 RDD 快取到記憶體、磁碟檔案系統中。快取是容錯的,如果一個 RDD 分片丟失,可以通過構建它的 transformation自動重構。被快取的 RDD 被使用的時,存取速度會被大大加速。一般的executor記憶體60%做 cache, 剩下的40%做task。
Spark中,RDD類可以使用cache() 和 persist() 方法來快取。cache()是persist()的特例,將該RDD快取到記憶體中。而persist可以指定一個StorageLevel。StorageLevel的列表可以在StorageLevel 伴生單例物件中找到。
Spark的不同StorageLevel ,目的滿足記憶體使用和CPU效率權衡上的不同需求。我們建議通過以下的步驟來進行選擇:
·如果你的RDDs可以很好的與預設的儲存級別(MEMORY_ONLY)契合,就不需要做任何修改了。這已經是CPU使用效率最高的選項,它使得RDDs的操作儘可能的快。
·如果不行,試著使用MEMORY_ONLY_SER並且選擇一個快速序列化的庫使得物件在有比較高的空間使用率的情況下,依然可以較快被訪問。
·儘可能不要儲存到硬碟上,除非計算資料集的函式,計算量特別大,或者它們過濾了大量的資料。否則,重新計算一個分割槽的速度,和與從硬碟中讀取基本差不多快。
·如果你想有快速故障恢復能力,使用複製儲存級別(例如:用Spark來響應web應用的請求)。所有的儲存級別都有通過重新計算丟失資料恢復錯誤的容錯機制,但是複製儲存級別可以讓你在RDD上持續的執行任務,而不需要等待丟失的分割槽被重新計算。
·如果你想要定義你自己的儲存級別(比如複製因子為3而不是2),可以使用StorageLevel 單例物件的apply()方法。
在不會使用cached RDD的時候,及時使用unpersist方法來釋放它。
10.RDD共享變數?
在應用開發中,一個函式被傳遞給Spark操作(例如map和reduce),在一個遠端叢集上執行,它實際上操作的是這個函式用到的所有變數的獨立拷貝。這些變數會被拷貝到每一臺機器。通常看來,在任務之間中,讀寫共享變數顯然不夠高效。然而,Spark還是為兩種常見的使用模式,提供了兩種有限的共享變數:廣播變數和累加器。
(1). 廣播變數(Broadcast Variables)
– 廣播變數快取到各個節點的記憶體中,而不是每個 Task
– 廣播變數被建立後,能在叢集中執行的任何函式呼叫
– 廣播變數是隻讀的,不能在被廣播後修改
– 對於大資料集的廣播, Spark 嘗試使用高效的廣播演算法來降低通訊成本
- val broadcastVar = sc.broadcast(Array(1, 2, 3))方法引數中是要廣播的變數
(2). 累加器
累加器只支援加法操作,可以高效地並行,用於實現計數器和變數求和。Spark 原生支援數值型別和標準可變集合的計數器,但使用者可以新增新的型別。只有驅動程式才能獲取累加器的值
11.spark-submit的時候如何引入外部jar包:
在通過spark-submit提交任務時,可以通過新增配置引數來指定
- –driver-class-path 外部jar包
- –jars 外部jar包
12.spark如何防止記憶體溢位?
- driver端的記憶體溢位
-
- 可以增大driver的記憶體引數:spark.driver.memory (default 1g)
- 這個引數用來設定Driver的記憶體。在Spark程式中,SparkContext,DAGScheduler都是執行在Driver端的。對應rdd的Stage切分也是在Driver端執行,如果使用者自己寫的程式有過多的步驟,切分出過多的Stage,這部分資訊消耗的是Driver的記憶體,這個時候就需要調大Driver的記憶體。
- map過程產生大量物件導致記憶體溢位
-
- 這種溢位的原因是在單個map中產生了大量的物件導致的,例如:rdd.map(x=>for(i <- 1 to 10000) yield i.toString),這個操作在rdd中,每個物件都產生了10000個物件,這肯定很容易產生記憶體溢位的問題。針對這種問題,在不增加記憶體的情況下,可以通過減少每個Task的大小,以便達到每個Task即使產生大量的物件Executor的記憶體也能夠裝得下。具體做法可以在會產生大量物件的map操作之前呼叫repartition方法,分割槽成更小的塊傳入map。例如:rdd.repartition(10000).map(x=>for(i <- 1 to 10000) yield i.toString)。
面對這種問題注意,不能使用rdd.coalesce方法,這個方法只能減少分割槽,不能增加分割槽, 不會有shuffle的過程。
- 資料不平衡導致記憶體溢位
-
- 資料不平衡除了有可能導致記憶體溢位外,也有可能導致效能的問題,解決方法和上面說的類似,就是呼叫repartition重新分割槽。這裡就不再累贅了。
- shuffle後記憶體溢位
-
- shuffle記憶體溢位的情況可以說都是shuffle後,單個檔案過大導致的。在Spark中,join,reduceByKey這一型別的過程,都會有shuffle的過程,在shuffle的使用,需要傳入一個partitioner,大部分Spark中的shuffle操作,預設的partitioner都是HashPatitioner,預設值是父RDD中最大的分割槽數,這個引數通過spark.default.parallelism控制(在spark-sql中用spark.sql.shuffle.partitions) , spark.default.parallelism引數只對HashPartitioner有效,所以如果是別的Partitioner或者自己實現的Partitioner就不能使用spark.default.parallelism這個引數來控制shuffle的併發量了。如果是別的partitioner導致的shuffle記憶體溢位,就需要從partitioner的程式碼增加partitions的數量。
- standalone模式下資源分配不均勻導致記憶體溢位
-
- 在standalone的模式下如果配置了–total-executor-cores 和 –executor-memory 這兩個引數,但是沒有配置–executor-cores這個引數的話,就有可能導致,每個Executor的memory是一樣的,但是cores的數量不同,那麼在cores數量多的Executor中,由於能夠同時執行多個Task,就容易導致記憶體溢位的情況。這種情況的解決方法就是同時配置–executor-cores或者spark.executor.cores引數,確保Executor資源分配均勻。
- 使用rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)代替rdd.cache()
-
- rdd.cache()和rdd.persist(Storage.MEMORY_ONLY)是等價的,在記憶體不足的時候rdd.cache()的資料會丟失,再次使用的時候會重算,而rdd.persist(StorageLevel.MEMORY_AND_DISK_SER)在記憶體不足的時候會儲存在磁碟,避免重算,只是消耗點IO時間。
13.spark中cache和persist的區別?
- cache:快取資料,預設是快取在記憶體中,其本質還是呼叫persist
- persist:快取資料,有豐富的資料快取策略。資料可以儲存在記憶體也可以儲存在磁碟中,使用的時候指定對應的快取級別就可以了。
14.spark分散式叢集搭建的步驟?
地球人都知道
- 這裡可以概述下如何搭建高可用的spark叢集(HA)
-
- 主要是引入了zookeeper
15.spark中的資料傾斜的現象,原因,後果?
- (1)、資料傾斜的現象
-
- 多數task執行速度較快,少數task執行時間非常長,或者等待很長時間後提示你記憶體不足,執行失敗。
- (2)、資料傾斜的原因
-
- 資料問題
-
-
- 1、key本身分佈不均衡(包括大量的key為空)
- 2、key的設定不合理
-
-
- spark使用問題
-
-
- 1、shuffle時的併發度不夠
- 2、計算方式有誤
-
- (3)、資料傾斜的後果
-
- 1、spark中的stage的執行時間受限於最後那個執行完成的task,因此執行緩慢的任務會拖垮整個程式的執行速度(分散式程式執行的速度是由最慢的那個task決定的)。
- 2、過多的資料在同一個task中執行,將會把executor撐爆。
16.spark資料傾斜的處理?
發現數據傾斜的時候,不要急於提高executor的資源,修改引數或是修改程式,首先要檢查資料本身,是否存在異常資料。
- 1、資料問題造成的資料傾斜
-
- 找出異常的key
-
-
- 如果任務長時間卡在最後最後1個(幾個)任務,首先要對key進行抽樣分析,判斷是哪些key造成的。 選取key,對資料進行抽樣,統計出現的次數,根據出現次數大小排序取出前幾個。
- 比如: df.select(“key”).sample(false,0.1).(k=>(k,1)).reduceBykey(+).map(k=>(k._2,k._1)).sortByKey(false).take(10)
- 如果發現多數資料分佈都較為平均,而個別資料比其他資料大上若干個數量級,則說明發生了資料傾斜。
-
-
- 經過分析,傾斜的資料主要有以下三種情況:
-
-
- 1、null(空值)或是一些無意義的資訊()之類的,大多是這個原因引起。
- 2、無效資料,大量重複的測試資料或是對結果影響不大的有效資料。
- 3、有效資料,業務導致的正常資料分佈。
-
-
- 解決辦法
-
-
- 第1,2種情況,直接對資料進行過濾即可(因為該資料對當前業務不會產生影響)。
- 第3種情況則需要進行一些特殊操作,常見的有以下幾種做法
-
-
-
-
- (1) 隔離執行,將異常的key過濾出來單獨處理,最後與正常資料的處理結果進行union操作。
- (2) 對key先新增隨機值,進行操作後,去掉隨機值,再進行一次操作。
- (3) 使用reduceByKey 代替 groupByKey(reduceByKey用於對每個key對應的多個value進行merge操作,最重要的是它能夠在本地先進行merge操作,並且merge操作可以通過函式自定義.)
- (4) 使用map join。
-
-
-
- 案例
-
-
- 如果使用reduceByKey因為資料傾斜造成執行失敗的問題。具體操作流程如下:
-
-
-
-
- (1) 將原始的 key 轉化為 key + 隨機值(例如Random.nextInt)
- (2) 對資料進行 reduceByKey(func)
- (3) 將 key + 隨機值 轉成 key
- (4) 再對資料進行 reduceByKey(func)
-
-
-
- 案例操作流程分析:
-
-
- 假設說有傾斜的Key,我們給所有的Key加上一個隨機數,然後進行reduceByKey操作;此時同一個Key會有不同的隨機數字首,在進行reduceByKey操作的時候原來的一個非常大的傾斜的Key就分而治之變成若干個更小的Key,不過此時結果和原來不一樣,怎麼破?進行map操作,目的是把隨機數字首去掉,然後再次進行reduceByKey操作。(當然,如果你很無聊,可以再次做隨機數字首),這樣我們就可以把原本傾斜的Key通過分而治之方案分散開來,最後又進行了全域性聚合
- 注意1: 如果此時依舊存在問題,建議篩選出傾斜的資料單獨處理。最後將這份資料與正常的資料進行union即可。
- 注意2: 單獨處理異常資料時,可以配合使用Map Join解決。
-
- 2、spark使用不當造成的資料傾斜
-
- 提高shuffle並行度
-
-
- dataFrame和sparkSql可以設定spark.sql.shuffle.partitions引數控制shuffle的併發度,預設為200。
- rdd操作可以設定spark.default.parallelism控制併發度,預設引數由不同的Cluster Manager控制。
- 侷限性: 只是讓每個task執行更少的不同的key。無法解決個別key特別大的情況造成的傾斜,如果某些key的大小非常大,即使一個task單獨執行它,也會受到資料傾斜的困擾。
-
-
- 使用map join 代替reduce join
17.spark中map-side-join關聯優化?
將多份資料進行關聯是資料處理過程中非常普遍的用法,不過在分散式計算系統中,這個問題往往會變的非常麻煩,因為框架提供的 join 操作一般會將所有資料根據 key 傳送到所有的 reduce 分割槽中去,也就是 shuffle 的過程。造成大量的網路以及磁碟IO消耗,執行效率極其低下,這個過程一般被稱為 reduce-side-join。
如果其中有張表較小的話,我們則可以自己實現在 map 端實現資料關聯,跳過大量資料進行 shuffle 的過程,執行時間得到大量縮短,根據不同資料可能會有幾倍到數十倍的效能提升。
何時使用:在海量資料中匹配少量特定資料
原理:reduce-side-join 的缺陷在於會將key相同的資料傳送到同一個partition中進行運算,大資料集的傳輸需要長時間的IO,同時任務併發度收到限制,還可能造成資料傾斜。
reduce-side-join 執行圖如下

map-side-join 執行圖如下:
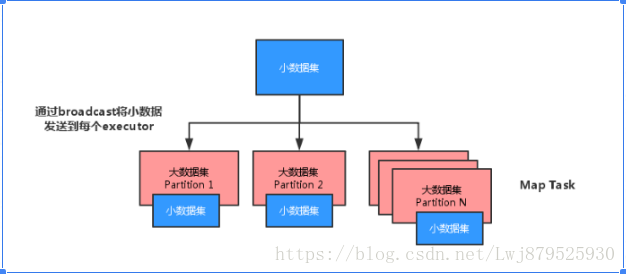
將少量的資料轉化為Map進行廣播,廣播會將此 Map 傳送到每個節點中,如果不進行廣播,每個task執行時都會去獲取該Map資料,造成了效能浪費。對大資料進行遍歷,使用mapPartition而不是map,因為mapPartition是在每個partition中進行操作,因此可以減少遍歷時新建broadCastMap.value物件的空間消耗,同時匹配不到的資料也不會返回。
18.kafka整合sparkStreaming問題?
- (1)、如何實現sparkStreaming讀取kafka中的資料
-
-
- 可以這樣說:在kafka0.10版本之前有二種方式與sparkStreaming整合,一種是基於receiver,一種是direct,然後分別闡述這2種方式分別是什麼
-
-
-
- receiver:是採用了kafka高階api,利用receiver接收器來接受kafka topic中的資料,從kafka接收來的資料會儲存在spark的executor中,之後spark streaming提交的job會處理這些資料,kafka中topic的偏移量是儲存在zk中的。
-
-
-
- 基本使用:
-

-
-
- 還有幾個需要注意的點:
-
-
-
- 在Receiver的方式中,Spark中的partition和kafka中的partition並不是相關的,所以如果我們加大每個topic的partition數量,僅僅是增加執行緒來處理由單一Receiver消費的主題。但是這並沒有增加Spark在處理資料上的並行度.
- 對於不同的Group和topic我們可以使用多個Receiver建立不同的Dstream來並行接收資料,之後可以利用union來統一成一個Dstream。
- 在預設配置下,這種方式可能會因為底層的失敗而丟失資料. 因為receiver一直在接收資料,在其已經通知zookeeper資料接收完成但是還沒有處理的時候,executor突然掛掉(或是driver掛掉通知executor關閉),快取在其中的資料就會丟失. 如果希望做到高可靠, 讓資料零丟失,如果我們啟用了Write Ahead Logs(spark.streaming.receiver.writeAheadLog.enable=true)該機制會同步地將接收到的Kafka資料寫入分散式檔案系統(比如HDFS)上的預寫日誌中. 所以, 即使底層節點出現了失敗, 也可以使用預寫日誌中的資料進行恢復. 複製到檔案系統如HDFS,那麼storage level需要設定成 StorageLevel.MEMORY_AND_DISK_SER,也就是KafkaUtils.createStream(…, StorageLevel.MEMORY_AND_DISK_SER)
-
-
-
- direct:在spark1.3之後,引入了Direct方式。不同於Receiver的方式,Direct方式沒有receiver這一層,其會週期性的獲取Kafka中每個topic的每個partition中的最新offsets,之後根據設定的maxRatePerPartition來處理每個batch。(設定spark.streaming.kafka.maxRatePerPartition=10000。限制每秒鐘從topic的每個partition最多消費的訊息條數)。
-
- (2) 對比這2中方式的優缺點:
-
- 採用receiver方式:這種方式可以保證資料不丟失,但是無法保證資料只被處理一次,WAL實現的是At-least-once語義(至少被處理一次),如果在寫入到外部儲存的資料還沒有將offset更新到zookeeper就掛掉,這些資料將會被反覆消費. 同時,降低了程式的吞吐量。
- 採用direct方式:相比Receiver模式而言能夠確保機制更加健壯. 區別於使用Receiver來被動接收資料, Direct模式會週期性地主動查詢Kafka, 來獲得每個topic+partition的最新的offset, 從而定義每個batch的offset的範圍. 當處理資料的job啟動時, 就會使用Kafka的簡單consumer api來獲取Kafka指定offset範圍的資料。
-
-
- 優點:
-
-
-
- 1、簡化並行讀取
-
-
-
-
- 如果要讀取多個partition, 不需要建立多個輸入DStream然後對它們進行union操作. Spark會建立跟Kafka partition一樣多的RDD partition, 並且會並行從Kafka中讀取資料. 所以在Kafka partition和RDD partition之間, 有一個一對一的對映關係.
-
-
-
-
- 2、高效能
-
-
-
-
- 如果要保證零資料丟失, 在基於receiver的方式中, 需要開啟WAL機制. 這種方式其實效率低下, 因為資料實際上被複制了兩份, Kafka自己本身就有高可靠的機制, 會對資料複製一份, 而這裡又會複製一份到WAL中. 而基於direct的方式, 不依賴Receiver, 不需要開啟WAL機制, 只要Kafka中作了資料的複製, 那麼就可以通過Kafka的副本進行恢復.
-
-
-
-
- 3、一次且僅一次的事務機制
-
-
-
-
- 基於receiver的方式, 是使用Kafka的高階API來在ZooKeeper中儲存消費過的offset的. 這是消費Kafka資料的傳統方式. 這種方式配合著WAL機制可以保證資料零丟失的高可靠性, 但是卻無法保證資料被處理一次且僅一次, 可能會處理兩次. 因為Spark和ZooKeeper之間可能是不同步的. 基於direct的方式, 使用kafka的簡單api, Spark Streaming自己就負責追蹤消費的offset, 並儲存在checkpoint中. Spark自己一定是同步的, 因此可以保證資料是消費一次且僅消費一次。不過需要自己完成將offset寫入zk的過程,在官方文件中都有相應介紹.
-
-
*簡單程式碼例項:
* messages.foreachRDD(rdd=>{
val message = rdd.map(_._2)//對資料進行一些操作
message.map(method)//更新zk上的offset (自己實現)
updateZKOffsets(rdd)
})
* sparkStreaming程式自己消費完成後,自己主動去更新zk上面的偏移量。也可以將zk中的偏移量儲存在mysql或者redis資料庫中,下次重啟的時候,直接讀取mysql或者redis中的偏移量,獲取到上次消費的偏移量,接著讀取資料。
20.spark master在使用zookeeper進行HA時,有哪些元資料儲存在zookeeper?
答:spark通過這個引數spark.deploy.zookeeper.dir指定master元資料在zookeeper中儲存的位置,包括worker,master,application,executors.standby節點要從zk中獲得元資料資訊,恢復叢集執行狀態,才能對外繼續提供服務,作業提交資源申請等,在恢復前是不能接受請求的,另外,master切換需要注意兩點:
1.在master切換的過程中,所有的已經在執行的程式皆正常執行,因為spark application在執行前就已經通過cluster manager獲得了計算資源,所以在執行時job本身的排程和處理master是沒有任何關係的;
2.在master的切換過程中唯一的影響是不能提交新的job,一方面不能提交新的應用程式給叢集,因為只有Active master才能接受新的程式的提交請求,另外一方面,已經執行的程式也不能action操作觸發新的job提交請求。
21.spark master HA主從切換過程不會影響叢集已有的作業執行,為什麼?
答:因為程式在執行之前,已經向叢集申請過資源,這些資源已經提交給driver了,也就是說已經分配好資源了,這是粗粒度分配,一次性分配好資源後不需要再關心資源分配,在執行時讓driver和executor自動互動,弊端是如果資源分配太多,任務執行完不會很快釋放,造成資源浪費,這裡不適用細粒度分配的原因是因為任務提交太慢。
22.什麼是粗粒度,什麼是細粒度,各自的優缺點是什麼?
答:1.粗粒度:啟動時就分配好資源,程式啟動,後續具體使用就使用分配好的資源,不需要再分配資源。好處:作業特別多時,資源複用率較高,使用粗粒度。缺點:容易資源浪費,如果一個job有1000個task,完成了999個,還有一個沒完成,那麼使用粗粒度。如果有999個資源閒置在那裡,會造成資源大量浪費。
2.細粒度:用資源的時候分配,用完了就立即回收資源,啟動會麻煩一點,啟動一次分配一次,會比較麻煩。
23.driver的功能是什麼?
答:1.一個spark作業執行時包括一個driver程序,也就是作業的主程序,具有main函式,並且有sparkContext的例項,是程式的入口;
2.功能:負責向叢集申請資源,向master註冊資訊,負責了作業的排程,負責了作業的解析,生成stage並排程task到executor上,包括DAGScheduler,TaskScheduler。
24.spark的有幾種部署模式,每種模式特點?
1)本地模式
Spark不一定非要跑在hadoop叢集,可以在本地,起多個執行緒的方式來指定。將Spark應用以多執行緒的方式直接執行在本地,一般都是為了方便除錯,本地模式分三類
· local:只啟動一個executor
· local[k]:啟動k個executor
· local:啟動跟cpu數目相同的 executor
2)standalone模式
分散式部署叢集, 自帶完整的服務,資源管理和任務監控是Spark自己監控,這個模式也是其他模式的基礎,
3)Spark on yarn模式
分散式部署叢集,資源和任務監控交給yarn管理,但是目前僅支援粗粒度資源分配方式,包含cluster和client執行模式,cluster適合生產,driver執行在叢集子節點,具有容錯功能,client適合除錯,dirver執行在客戶端
4)Spark On Mesos模式。官方推薦這種模式(當然,原因之一是血緣關係)。正是由於Spark開發之初就考慮到支援Mesos,因此,目前而言,Spark執行在Mesos上會比執行在YARN上更加靈活,更加自然。使用者可選擇兩種排程模式之一執行自己的應用程式:
1) 粗粒度模式(Coarse-grained Mode):每個應用程式的執行環境由一個Dirver和若干個Executor組成,其中,每個Executor佔用若干資源,內部可執行多個Task(對應多少個“slot”)。應用程式的各個任務正式執行之前,需要將執行環境中的資源全部申請好,且執行過程中要一直佔用這些資源,即使不用,最後程式執行結束後,回收這些資源。
2) 細粒度模式(Fine-grained Mode):鑑於粗粒度模式會造成大量資源浪費,Spark On Mesos還提供了另外一種排程模式:細粒度模式,這種模式類似於現在的雲端計算,思想是按需分配。
25.Spark技術棧有哪些元件,每個元件都有什麼功能,適合什麼應用場景?
1)Spark core:是其它元件的基礎,spark的核心,主要包含:有向迴圈圖、RDD、Lingage、Cache、broadcast等,並封裝了底層通訊框架,是Spark的基礎。
2)SparkStreaming是一個對實時資料流進行高通量、容錯處理的流式處理系統,可以對多種資料來源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)進行類似Map、Reduce和Join等複雜操作,將流式計算分解成一系列短小的批處理作業。
3)Spark sql:Shark是SparkSQL的前身,Spark SQL的一個重要特點是其能夠統一處理關係表和RDD,使得開發人員可以輕鬆地使用SQL命令進行外部查詢,同時進行更復雜的資料分析
4)BlinkDB :是一個用於在海量資料上執行互動式 SQL 查詢的大規模並行查詢引擎,它允許使用者通過權衡資料精度來提升查詢響應時間,其資料的精度被控制在允許的誤差範圍內。
5)MLBase是Spark生態圈的一部分專注於機器學習,讓機器學習的門檻更低,讓一些可能並不瞭解機器學習的使用者也能方便地使用MLbase。MLBase分為四部分:MLlib,MLI、ML Optimizer和MLRuntime。
6)GraphX是Spark中用於圖和圖平行計算
26.spark中worker 的主要工作是什麼?
主要功能:管理當前節點記憶體,CPU的使用情況,接受master傳送過來的資源指令,通過executorRunner啟動程式分配任務,worker就類似於包工頭,管理分配新程序,做計算的服務,相當於process服務,需要注意的是:
1.worker會不會彙報當前資訊給master?worker心跳給master主要只有workid,不會以心跳的方式傳送資源資訊給master,這樣master就知道worker是否存活,只有故障的時候才會傳送資源資訊;
2.worker不會執行程式碼,具體執行的是executor,可以執行具體application斜的業務邏輯程式碼,操作程式碼的節點,不會去執行程式碼。
27.簡單說一下hadoop和spark的shuffle相同和差異?
答:1)從 high-level 的角度來看,兩者並沒有大的差別。 都是將 mapper(Spark 裡是 ShuffleMapTask)的輸出進行 partition,不同的 partition 送到不同的 reducer(Spark 裡 reducer 可能是下一個 stage 裡的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以記憶體作緩衝區,邊 shuffle 邊 aggregate 資料,等到資料 aggregate 好以後進行 reduce() (Spark 裡可能是後續的一系列操作)。
2)從 low-level 的角度來看,兩者差別不小。 Hadoop MapReduce 是 sort-based,進入 combine() 和 reduce() 的 records 必須先 sort。這樣的好處在於 combine/reduce() 可以處理大規模的資料,因為其輸入資料可以通過外排得到(mapper 對每段資料先做排序,reducer 的 shuffle 對排好序的每段資料做歸併)。目前的 Spark 預設選擇的是 hash-based,通常使用 HashMap 來對 shuffle 來的資料進行 aggregate,不會對資料進行提前排序。如果使用者需要經過排序的資料,那麼需要自己呼叫類似 sortByKey() 的操作;如果你是Spark 1.1的使用者,可以將spark.shuffle.manager設定為sort,則會對資料進行排序。在Spark 1.2中,sort將作為預設的Shuffle實現。
3)從實現角度來看,兩者也有不少差別。 Hadoop MapReduce 將處理流程劃分出明顯的幾個階段:map(), spill, merge, shuffle, sort, reduce() 等。每個階段各司其職,可以按照過程式的程式設計思想來逐一實現每個階段的功能。在 Spark 中,沒有這樣功能明確的階段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蘊含在 transformation() 中。
如果我們將 map 端劃分資料、持久化資料的過程稱為 shuffle write,而將 reducer 讀入資料、aggregate 資料的過程稱為 shuffle read。那麼在 Spark 中,問題就變為怎麼在 job 的邏輯或者物理執行圖中加入 shuffle write 和 shuffle read 的處理邏輯?以及兩個處理邏輯應該怎麼高效實現?
Shuffle write由於不要求資料有序,shuffle write 的任務很簡單:將資料 partition 好,並持久化。之所以要持久化,一方面是要減少記憶體儲存空間壓力,另一方面也是為了 fault-tolerance。
28.Mapreduce和Spark的都是平行計算,那麼他們有什麼相同和區別?
答:兩者都是用mr模型來進行平行計算:
1)hadoop的一個作業稱為job,job裡面分為map task和reduce task,每個task都是在自己的程序中執行的,當task結束時,程序也會結束。
2)spark使用者提交的任務成為application,一個application對應一個sparkcontext,app中存在多個job,每觸發一次action操作就會產生一個job。這些job可以並行或序列執行,每個job中有多個stage,stage是shuffle過程中DAGSchaduler通過RDD之間的依賴關係劃分job而來的,每個stage裡面有多個task,組成taskset有TaskSchaduler分發到各個executor中執行,executor的生命週期是和app一樣的,即使沒有job執行也是存在的,所以task可以快速啟動讀取記憶體進行計算。
3)hadoop的job只有map和reduce操作,表達能力比較欠缺而且在mr過程中會重複的讀寫hdfs,造成大量的io操作,多個job需要自己管理關係。
spark的迭代計算都是在記憶體中進行的,API中提供了大量的RDD操作如join,groupby等,而且通過DAG圖可以實現良好的容錯。
29.RDD機制?
答:rdd分散式彈性資料集,簡單的理解成一種資料結構,是spark框架上的通用貨幣。
所有運算元都是基於rdd來執行的,不同的場景會有不同的rdd實現類,但是都可以進行互相轉換。
rdd執行過程中會形成dag圖,然後形成lineage保證容錯性等。 從物理的角度來看rdd儲存的是block和node之間的對映。
30、spark有哪些元件?
答:主要有如下元件:
1)master:管理叢集和節點,不參與計算。
2)worker:計算節點,程序本身不參與計算,和master彙報。
3)Driver:執行程式的main方法,建立spark context物件。
4)spark context:控制整個application的生命週期,包括dagsheduler和task scheduler等元件。
5)client:使用者提交程式的入口。
31、spark工作機制?
答:使用者在client端提交作業後,會由Driver執行main方法並建立spark context上下文。
執行add運算元,形成dag圖輸入dagscheduler,按照add之間的依賴關係劃分stage輸入task scheduler。 task scheduler會將stage劃分為task set分發到各個節點的executor中執行。
32、spark的優化怎麼做?
答: spark調優比較複雜,但是大體可以分為三個方面來進行,
1)平臺層面的調優:防止不必要的jar包分發,提高資料的本地性,選擇高效的儲存格式如parquet,
2)應用程式層面的調優:過濾操作符的優化降低過多小任務,降低單條記錄的資源開銷,處理資料傾斜,複用RDD進行快取,作業並行化執行等等,
3)JVM層面的調優:設定合適的資源量,設定合理的JVM,啟用高效的序列化方法如kyro,增大off head記憶體等等
- 序列化在分散式系統中扮演著重要的角色,優化Spark程式時,首當其衝的就是對序列化方式的優化。Spark為使用者提供兩種序列化方式:
- Java serialization: 預設的序列化方式。
- Kryo serialization: 相較於 Java serialization 的方式,速度更快,空間佔用更小,但並不支援所有的序列化格式,同時使用的時候需要註冊class。spark-sql中預設使用的是kyro的序列化方式。
- 可以在spark-default.conf設定全域性引數,也可以程式碼中初始化時對SparkConf設定 conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") ,該引數會同時作用於機器之間資料的shuffle操作以及序列化rdd到磁碟,記憶體。
Spark不將Kyro設定成預設的序列化方式是因為它需要對類進行註冊,官方強烈建議在一些網路資料傳輸很大的應用中使用kyro序列化。

如果你要序列化的物件比較大,可以增加引數spark.kryoserializer.buffer所設定的值。
如果你沒有註冊需要序列化的class,Kyro依然可以照常工作,但會儲存每個物件的全類名(full class name),這樣的使用方式往往比預設的 Java serialization 還要浪費更多的空間。
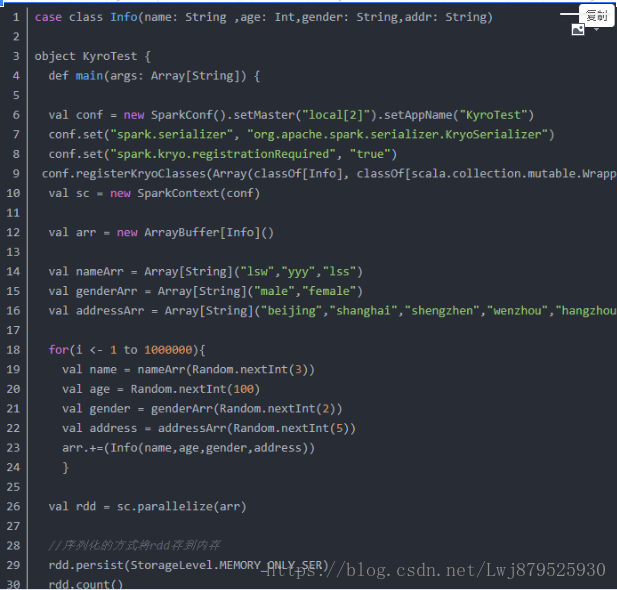
可以設定 spark.kryo.registrationRequired 引數為 true,使用kyro時如果在應用中有類沒有進行註冊則會報錯:
如上這個錯誤需要新增

33.選擇題
二、選擇題
1. Spark 的四大元件下面哪個不是 (D )
A.Spark Streaming B. Mlib
C Graphx D.Spark R
2.下面哪個埠不是 spark 自帶服務的埠 (C )
A.8080 B.4040 C.8090 D.18080
備註:8080:spark叢集web ui埠,4040:sparkjob監控埠,18080:jobhistory埠
3.spark 1.4 版本的最大變化 (B )
A spark sql Release 版本 B .引入 Spark R
C DataFrame D.支援動態資源分配
4. Spark Job 預設的排程模式 (A )
A FIFO B FAIR
C 無 D 執行時指定
備註:Spark中的排程模式主要有兩種:FIFO和FAIR。預設情況下Spark的排程模式是FIFO(先進先出),誰先提交誰先執行,後面的任務需要等待前面的任務執行。而FAIR(公平排程)模式支援在排程池中為任務進行分組,不同的排程池權重不同,任務可以按照權重來決定執行順序。使用哪種排程器由引數spark.scheduler.mode來設定,可選的引數有FAIR和FIFO,預設是FIFO。
5.哪個不是本地模式執行的條件 ( D)
A spark.localExecution.enabled=true
B 顯式指定本地執行
C finalStage 無父 Stage
D partition預設值
備註:【問題】Spark在windows能跑叢集模式嗎?
我認為是可以的,但是需要詳細瞭解cmd命令列的寫法。目前win下跑spark的單機模式是沒有問題的。
【關鍵點】spark啟動機制容易被windows的命令列cmd坑
1、帶空格、奇怪字元的安裝路徑,cmd不能識別。最典型的坑就是安裝在Program Files資料夾下的程式,因為Program和Files之間有個空格,所以cmd竟不能識別。之前就把JDK安裝在了Program Files下面,然後啟動spark的時候,總是提示我找不到JDK。我明明配置了環境變量了啊?這就是所謂了《已經配置環境變數,spark 仍然找不到Java》的錯誤問題。至於奇怪的字元,如感嘆號!,我經常喜歡用來將重要的資料夾排在最前面,但cmd命令提示符不能識別。
2、是否需要配置hadoop的路徑的問題——答案是需要用HDFS或者yarn就配,不需要用則不需配置。目前大多數的應用場景裡面,Spark大規模叢集基本安裝在Linux伺服器上,而自己用windows跑spark的情景,則大多基於學習或者實驗性質,如果我們所要讀取的資料檔案從本地windows系統的硬碟讀取(比如說d:\data\ml.txt),基本上不需要配置hadoop路徑。我們都知道,在編spark程式的時候,可以指定spark的啟動模式,而啟動模式有這麼三中(以python程式碼舉例):
(2.1)本地情況,conf = SparkConf().setMaster("local[*]") ——>也就是拿本機的spark來跑程式
(2.2)遠端情況,conf = SparkConf().setMaster("spark://remotehost:7077") ——>遠端spark主機
(2.3)yarn情況,conf = SparkConf().setMaster("yarn-client") ——>遠端或本地 yarn叢集代理spark
針對這3種情況,配置hadoop安裝路徑都有什麼作用呢?(2.1)本地的情況,直接拿本機安裝的spark來執行spark程式(比如d:\spark-1.6.2),則配不配製hadoop路徑取決於是否需要使用hdfs。java程式的情況就更為簡單,只需要匯入相應的hadoop的jar包即可,是否配置hadoop路徑並不重要。(2.2)的情況大體跟(2.1)的情況相同,雖然使用的遠端spark,但如果使用本地資料,則運算的元資料也是從本地上傳到遠端spark叢集的,無需配置hdfs。而(2.3)的情況就大不相同,經過我搜遍baidu、google、bing引擎,均沒找到SparkConf直接配置遠端yarn地址的方法,唯一的一個帖子介紹可以使用yarn://remote:8032的形式,則會報錯“無法解析 地址”。檢視Spark的官方說明,Spark其實是通過hadoop路徑下的etc\hadoop資料夾中的配置檔案來尋找yarn叢集的。因此,需要使用yarn來執行spark的情況,在spark那配置好hadoop的目錄就尤為重要。後期經過虛擬機器的驗證,表明,只要windows本地配置的host地址等資訊與linux伺服器端相同(注意應更改hadoop-2/etc/hadoop 下各種資料夾的配置路徑,使其與windows本地一致),是可以直接在win下用yarn-client提交spark任務到遠端叢集的。
3、是否需要配置環境變數的問題,若初次配置,可以考慮在IDE裡面配置,或者在程式本身用setProperty函式進行配置。因為配置windows下的hadoop、spark環境是個非常頭疼的問題,有可能路徑不對而導致無法找到相應要呼叫的程式。待實驗多次成功率提高以後,再直接配置windows的全域性環境變數不遲。
4、使用Netbeans這個IDE的時候,有遇到Netbeans不能清理構建的問題。原因,極有可能是匯入了重複的庫,spark裡面含有hadoop包,記得檢查衝突。同時,在清理構建之前,記得重新編譯一遍程式,再進行清理並構建。
5、經常遇到WARN YarnClusterScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources資源不足無法執行的問題,新增conf.set("spark.executor.memory", "512m");語句進行資源限制。先前在虛擬機器跑spark,由於本身機子效能不高,給虛擬機器設定的記憶體僅僅2G,導致hadoop和spark雙開之後系統資源嚴重不足。因此可以縮小每個executor的運算規模。其他資源缺乏問題的解決方法參考http://blog.sina.com.cn/s/blog_4b1452dd0102wyzo.html
6.下面哪個不是 RDD 的特點 (C )
A. 可分割槽 B 可序列化 C 可修改 D 可持久化
7. 關於廣播變數,下面哪個是錯誤的 (D )
A 任何函式呼叫 B 是隻讀的
C 儲存在各個節點 D 儲存在磁碟或 HDFS
8. 關於累加器,下面哪個是錯誤的 (D )
A 支援加法 B 支援數值型別
C 可並行 D 不支援自定義型別
9.Spark 支援的分散式部署方式中哪個是錯誤的 (D )
A standalone B spark on mesos
C spark on YARN D Spark on local
10.Stage 的 Task 的數量由什麼決定 (A )
A Partition B Job C Stage D TaskScheduler
11.下面哪個操作是窄依賴 (B )
A join B filter
C group D sort
12.下面哪個操作肯定是寬依賴 (C )
A map B flatMap
C reduceByKey D sample
13.spark 的 master 和 worker 通過什麼方式進行通訊的? (D )
A http B nio C netty D Akka
備註:從spark1.3.1之後,netty完全代替 了akka
一直以來,基於Akka實現的RPC通訊框架是Spark引以為豪的主要特性,也是與Hadoop等分散式計算框架對比過程中一大亮點,但是時代和技術都在演化,從Spark1.3.1版本開始,為了解決大資料塊(如shuffle)的傳輸問題,Spark引入了Netty通訊框架,到了1.6.0版本,Netty居然完全取代了Akka,承擔Spark內部所有的RPC通訊以及資料流傳輸。
那麼Akka又是什麼東西?從Akka出現背景來說,它是基於Actor的RPC通訊系統,它的核心概念也是Message,它是基於協程的,效能不容置疑;基於scala的偏函式,易用性也沒有話說,但是它畢竟只是RPC通訊,無法適用大的package/stream的資料傳輸,這也是Spark早期引入Netty的原因。
那麼Netty為什麼可以取代Akka?首先不容置疑的是Akka可以做到的,Netty也可以做到,但是Netty可以做到,Akka卻無法做到,原因是啥?在軟體棧中,Akka相比Netty要Higher一點,它專門針對RPC做了很多事情,而Netty相比更加基礎一點,可以為不同的應用層通訊協議(RPC,FTP,HTTP等)提供支援,在早期的Akka版本,底層的NIO通訊就是用的Netty;其次一個優雅的工程師是不會允許一個系統中容納兩套通訊框架,噁心!最後,雖然Netty沒有Akka協程級的效能優勢,但是Netty內部高效的Reactor執行緒模型,無鎖化的序列設計,高效的序列化,零拷貝,記憶體池等特性也保證了Netty不會存在效能問題。
那麼Spark是怎麼用Netty來取代Akka呢?一句話,利用偏函式的特性,基於Netty“仿造”出一個簡約版本的Actor模型!!
14 預設的儲存級別 (A )
A MEMORY_ONLY B MEMORY_ONLY_SER
C MEMORY_AND_DISK D MEMORY_AND_DISK_SER
備註:
//不會儲存任務資料 val NONE = new StorageLevel(false, false, false, false) //直接將RDD的partition儲存在該節點的Disk上 val DISK_ONLY = new StorageLevel(true, false, false, false) //直接將RDD的partition儲存在該節點的Disk上,在其他節點上儲存一個相同的備份 val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) //將RDD的partition對應的原生的Java Object儲存在JVM中,如果RDD太大導致它的部分partition不能儲存在記憶體中 //那麼這些partition將不會快取,並且需要的時候被重新計算,預設快取的級別 val MEMORY_ONLY = new StorageLevel(false, true, false, true) //將RDD的partition對應的原生的Java Object儲存在JVM中,在其他節點上儲存一個相同的備份 val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) //將RDD的partition反序列化後的物件儲存在JVM中,如果RDD太大導致它的部分partition不能儲存在記憶體中 //超出的partition將被儲存在Disk上,並且在需要時讀取 val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) //在其他節點上儲存一個相同的備份 val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) //將RDD的partition序列化後儲存在Tachyon中 val OFF_HEAP = new StorageLevel(false, false, true, false)
15 spark.deploy.recoveryMode 不支援那種 (D )
A.ZooKeeper B. FileSystem
D NONE D Hadoop
16.下列哪個不是 RDD 的快取方法 (C )
A persist() B Cache()
C Memory()
17.Task 執行在下來哪裡個選項中 Executor 上的工作單元 (C )
A Driver program B. spark master
C.worker node D Cluster manager
18.hive 的元資料儲存在 derby 和 MySQL 中有什麼區別 (B )
A.沒區別 B.多會話
C.支援網路環境 D資料庫的區別
備註: Hive 將元資料儲存在 RDBMS 中,一般常用 MySQL 和 Derby。預設情況下,Hive 元資料儲存在內嵌的 Derby 資料庫中,只能允許一個會話連線,只適合簡單的測試。實際生產環境中不適用, 為了支援多使用者會話,則需要一個獨立的元資料庫,使用 MySQL 作為元資料庫,Hive 內部對 MySQL 提供了很好的支援。
內建的derby主要問題是併發效能很差,可以理解為單執行緒操作。
Derby還有一個特性。更換目錄執行操作,會找不到相關表等
19.DataFrame 和 RDD 最大的區別 (B )
A.科學統計支援 B.多了 schema
C.儲存方式不一樣 D.外部資料來源支援
備註:

上圖直觀體現了RDD與DataFrame的區別:左側的RDD[Person]雖然以Person為型別引數,但Spark框架本身不瞭解Person類的內部結構。而右側的DataFrame卻提供了詳細的結構資訊,使得Spark SQL可以清楚地知道該資料集中包含哪些列,每列的名稱和型別各是什麼。DataFrame多了資料的結構資訊,即schema。RDD是分散式的Java物件的集合。DataFrame是分散式的Row物件的集合。DataFrame除了提供了比RDD更豐富的運算元以外,更重要的特點是提升執行效率、減少資料讀取以及執行計劃的優化,比如filter下推、裁剪等。
提升執行效率: RDD API是函式式的,強調不變性,在大部分場景下傾向於建立新物件而不是修改老物件。這一特點雖然帶來了乾淨整潔的API,卻也使得Spark應用程式在執行期傾向於建立大量臨時物件,對GC造成壓力。在現有RDD API的基礎之上,我們固然可以利用mapPartitions方法來過載RDD單個分片內的資料建立方式,用複用可變物件的方式來減小物件分配和GC的開銷,但這犧牲了程式碼的可讀性,而且要求開發者對Spark執行時機制有一定的瞭解,門檻較高。另一方面,Spark SQL在框架內部已經在各種可能的情況下儘量重用物件,這樣做雖然在內部會打破了不變性,但在將資料返回給使用者時,還會重新轉為不可變資料。利用 DataFrame API進行開發,可以免費地享受到這些優化效果。
減少資料讀取:分析大資料,最快的方法就是 ——忽略它。這裡的“忽略”並不是熟視無睹,而是根據查詢條件進行恰當的剪枝。
上文討論分割槽表時提到的分割槽剪 枝便是其中一種——當查詢的過濾條件中涉及到分割槽列時,我們可以根據查詢條件剪掉肯定不包含目標資料的分割槽目錄,從而減少IO。
對於一些“智慧”資料格 式,Spark SQL還可以根據資料檔案中附帶的統計資訊來進行剪枝。簡單來說,在這類資料格式中,資料是分段儲存的,每段資料都帶有最大值、最小值、null值數量等 一些基本的統計資訊。當統計資訊表名某一資料段肯定不包括符合查詢條件的目標資料時,該資料段就可以直接跳過(例如某整數列a某段的最大值為100,而查詢條件要求a > 200)。
此外,Spark SQL也可以充分利用RCFile、ORC、Parquet等列式儲存格式的優勢,僅掃描查詢真正涉及的列,忽略其餘列的資料。

為了說明查詢優化,我們來看上圖展示的人口資料分析的示例。圖中構造了兩個DataFrame,將它們join之後又做了一次filter操作。如果原封不動地執行這個執行計劃,最終的執行效率是不高的。因為join是一個代價較大的操作,也可能會產生一個較大的資料集。如果我們能將filter下推到 join下方,先對DataFrame進行過濾,再join過濾後的較小的結果集,便可以有效縮短執行時間。而Spark SQL的查詢優化器正是這樣做的。簡而言之,邏輯查詢計劃優化就是一個利用基於關係代數的等價變換,將高成本的操作替換為低成本操作的過程。
得到的優化執行計劃在轉換成物 理執行計劃的過程中,還可以根據具體的資料來源的特性將過濾條件下推至資料來源內。最右側的物理執行計劃中Filter之所以消失不見,就是因為溶入了用於執行最終的讀取操作的表掃描節點內。
對於普通開發者而言,查詢優化 器的意義在於,即便是經驗並不豐富的程式設計師寫出的次優的查詢,也可以被儘量轉換為高效的形式予以執行。
RDD和Dataset
DataSet以Catalyst邏輯執行計劃表示,並且資料以編碼的二進位制形式被儲存,不需要反序列化就可以執行sorting、shuffle等操