
推薦系統入門
1. 推薦系統的意義
網際網路大爆炸時期的資訊過載的解決方案:
對使用者而言:找到好玩的東西,幫助決策,發現新鮮事物。
對商家而言:提供個性化服務,提高信任度和粘性,增加營收。
2. 推薦系統的構成
前臺的展示頁面,後臺的日誌系統,推薦演算法等部分組成,如下圖所示:
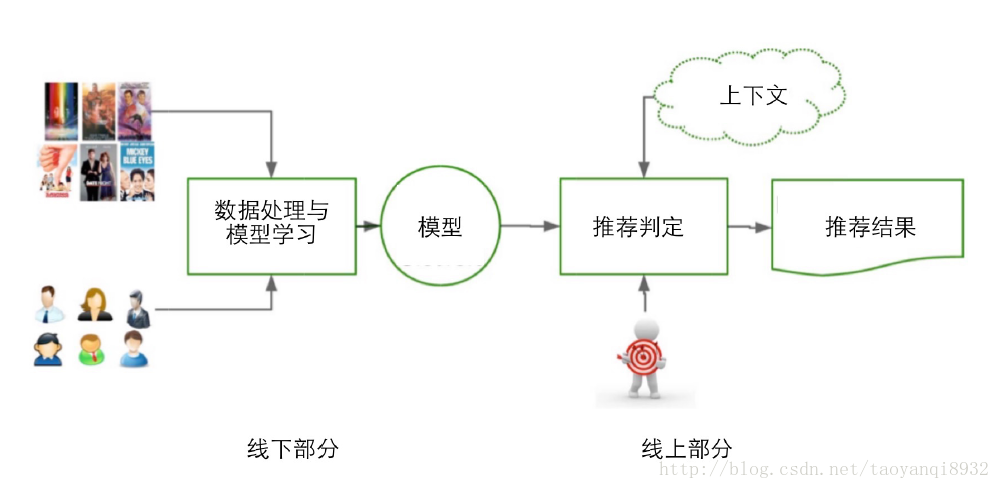
3. 推薦系統的評測
3.1 離線實驗
即線下的部分,用於訓練模型
優點:
不需要有對實際系統的控制權;
不需要使用者參與體驗;
速度快,可以測試大量演算法;
缺點:
無法計算商業上關心的指標;
離線實驗的指標和商業指標存在差距;
3.2 使用者調查
優點:
獲得很多體現使用者主觀感受的指標;
實驗風險很低,出現錯誤後很容易彌補;
缺點:
1.招募測試使用者代價較大;
2.設計雙盲實驗困難,在測試環境下收集的測試指標可能在真實環境下無法重現;
一般一個新的推薦演算法最終上線都需要經歷以上3個實驗:
1) 通過離線實驗證明它在很多離線指標上優於現有的演算法;
2) 通過使用者調查確定它的使用者滿意度不低於現有的演算法;
3) 通過線上的AB測試確定它在我們關心的指標上優於現有的演算法;
4 推薦系統的評估
4.1 準確度
RMSE(均方根誤差),MAE(平均絕對誤差)
Top N推薦
主要為:準確率precison,召回率recall指標
準確率說的是推薦的10條資訊中使用者真正感興趣的條數,召回率說的是使用者真正感興趣的你推薦條數佔比。
下圖中R(U)為推薦,T(U)為使用者選擇的:
4.2 覆蓋率
推薦出來的物品佔總物品集合的比例;
4.3 多樣性
推薦列表中物品兩兩之間的差異性;
4.4 新穎性,驚喜度,實時性,商業目標等
5. 推薦演算法
5.1 基於內容的推薦演算法
優點:
- 基於使用者喜歡的物品的屬性/內容進行推薦
- 需要分析內容,無需考慮使用者與使用者之間的關聯
缺點:
- 要求內容容易抽取成有意義的特徵,特徵內容具有良好的結構性;
- 不能很好的處理一詞多義和一義多詞帶來的語義問題;
步驟:
- 對於要推薦的物品建立一份特徵
- 對於使用者喜歡的物品建立一份特徵
- 計算相似度
比如說在文件中常用的餘弦相似度:
5.2 協同過濾
5.2.1 基於使用者的協同過濾(UserCF)
演算法步驟:
- 找到和目標使用者興趣相似的使用者集合,計算使用者的相似度;
- 找到“近鄰”,對近鄰在新物品的評價(打分)加權推薦
下圖一個非常直觀的例子:

兔子和米老鼠最相似,則給米老鼠推薦兔子喜歡的物品:
5.2.2 基於物品的協同過濾(ItemCF)
演算法步驟:
- 對於有相同使用者互動的物品,計算物品相似度;
- 找到物品“近鄰”,進行推薦
相似性的度量:

協同過濾的對比:
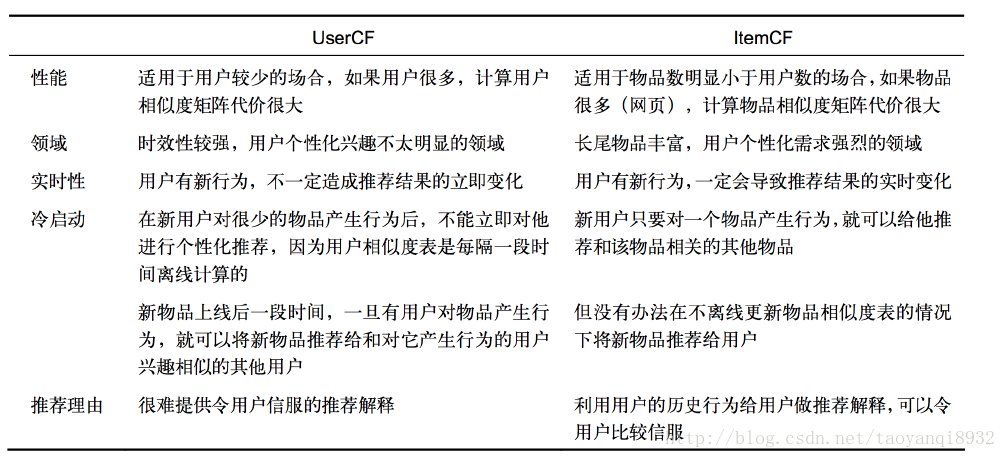
其中ItemCF一定情況下可以緩解冷啟動的現象,而且其更加穩定,而且其更有說服了。
協同過濾優點
- 基於使用者行為,因此對推薦內容無需先驗知識
- 只需要使用者和商品關聯矩陣即可,結構簡單
- 在使用者行為豐富的情況下,效果好
協同過濾缺點
- 需要大量的顯性/隱性使用者行為
- 需要通過完全相同的商品關聯,相似的不行
- 假定使用者的興趣完全取決於之前的行為,而和當前上下文環境無關
- 在資料稀疏的情況下受影響。可以考慮二度關聯。
冷啟動問題
對於新使用者
- 所有推薦系統對於新使用者都有這個問題
- 推薦非常熱門的商品
- 收集一些資訊 在使用者註冊的時候收集一些資訊
- 在使用者註冊完之後,用一些互動遊戲等確定喜歡與不喜歡
對於新商品
- 根據本身的屬性,求與原來商品的相似度。
- Item-based協同過濾可以推薦出去。
5.3 基於矩陣分解的推薦演算法
原理:根據已有的評分矩陣(非常稀疏),分解為低維的使用者特徵矩陣(評分者對各個因子的喜好程度)以及商品特徵矩陣(商品包含各個因子的程度),最後再反過來分析資料(使用者特徵矩陣與商品特徵矩陣相乘得到新的評分矩陣)得出預測結果;

SVD
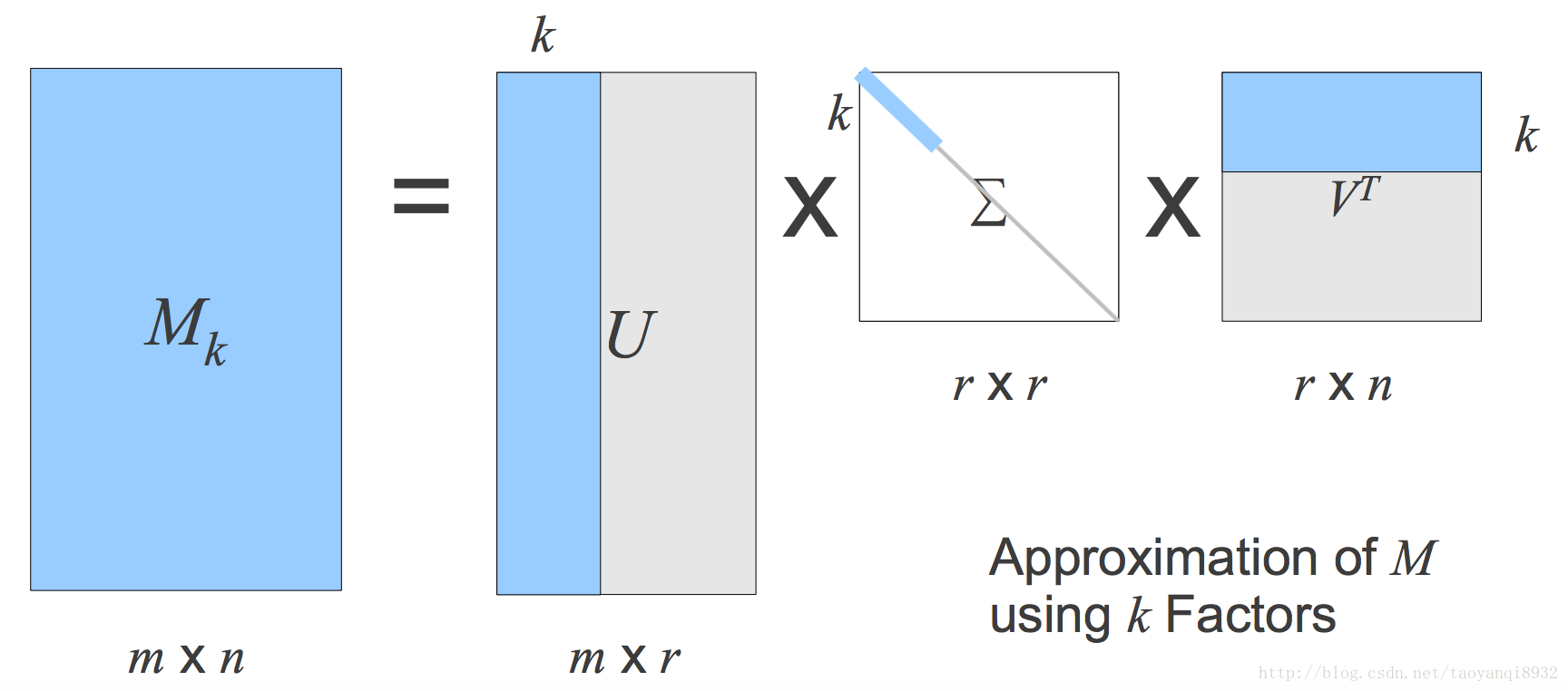
SVD的時間複雜度為O(m^3),M經常是稀疏且有空缺值的,簡單的做法是將空缺值補上隨機值,那麼就可以svd分解了,但是推薦效果一般,因此一般將該問題轉化為優化問題;同時原始矩陣中0很多,不宜用0填補。
矩陣分解

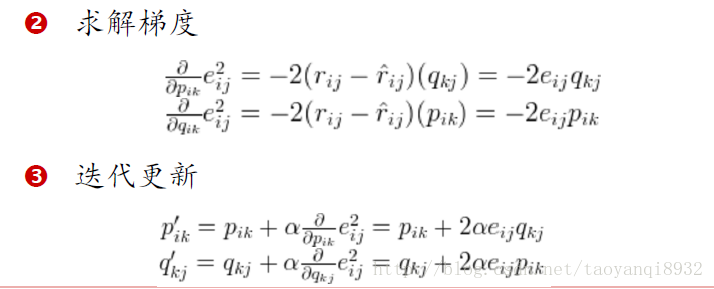
即給定一個損失函式然後最優化的過程
5.4 混合推薦
(1)加權的混合: 用線性公式將幾種不同的推薦按照一定權重組合起來,具體權重的值需要在測試資料集上反覆實驗,從而達到最好的推薦效果;
(2)切換的混合:對於不同的情況(資料量,系統執行狀況,使用者和物品的數目等),推薦策略可能有很大的不同,那麼切換的混合方式,就是允許在不同的情況下,選擇最為合適的推薦機制計算推薦;
(3)分割槽的混合:採用多種推薦機制,並將不同的推薦結果分不同的區顯示給使用者;其實,Amazon,噹噹網等很多電子商務網站都是採用這樣的方式,使用者可以得到很全面的推薦,也更容易找到他們想要的東西;
(4)分層的混合:採用多種推薦機制,並將一個推薦機制的結果作為另一個的輸入,從而綜合各個推薦機制的優缺點,得到更加準確的推薦;
參考資料:
1. 《推薦系統原理與應用》七月線上
2. 推薦系統