
推薦系統入門——初步理解
一、什麼是推薦系統?
推薦系統是啥?
如果你是個多年電商(剁手)黨,你會說是這個:
如果你是名充滿文藝細胞的音樂發燒友,你會答這個:
沒錯,猜你喜歡、個性歌單,這些都是推薦系統的輸出內容。從這些我們就可以總結出,推薦系統到底是做什麼的。
目的1. 幫助使用者找到想要的商品(新聞/音樂/……),發掘長尾
幫使用者找到想要的東西,談何容易。商品茫茫多,甚至是我們自己,也經常點開淘寶,面對眼花繚亂的打折活動不知道要買啥。在經濟學中,有一個著名理論叫長尾理論(The Long Tail)。
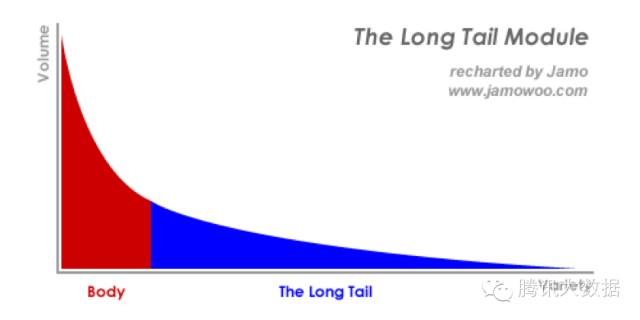
套用在網際網路領域中,指的就是最熱的那一小部分資源將得到絕大部分的關注,而剩下的很大一部分資源卻鮮少有人問津。這不僅造成了資源利用上的浪費,也讓很多口味偏小眾的使用者無法找到自己感興趣的內容。
目的2. 降低資訊過載
網際網路時代資訊量已然處於爆炸狀態,若是將所有內容都放在網站首頁上使用者是無從閱讀的,資訊的利用率將會十分低下。因此我們需要推薦系統來幫助使用者過濾掉低價值的資訊。
目的3. 提高站點的點選率/轉化率
好的推薦系統能讓使用者更頻繁地訪問一個站點,並且總是能為使用者找到他想要購買的商品或者閱讀的內容。
目的4. 加深對使用者的瞭解,為使用者提供定製化服務
可以想見,每當系統成功推薦了一個使用者感興趣的內容後,我們對該使用者的興趣愛好等維度上的形象是越來越清晰的。當我們能夠精確描繪出每個使用者的形象之後,就可以為他們定製一系列服務,讓擁有各種需求的使用者都能在我們的平臺上得到滿足。
推薦系統的定義
推薦系統有3個重要的模組:使用者建模模組、推薦物件建模模塊、推薦演算法模組。通用的推薦系統模型流程如圖。推薦系統把使用者模型中興趣需求資訊和推薦物件模型中的特徵資訊匹配,同時使用相應的推薦演算法進行計算篩選,找到使用者可能感興趣的推薦物件,然後推薦給使用者。

推薦系統存在的意義
隨著當今技術的飛速發展,資料量也與日俱增,人們越來越感覺在海量資料面前束手無策。正是為了解決資訊過載(Information overload)的問題,人們提出了推薦系統(與搜尋引擎對應,人們習慣叫推薦系統為推薦引擎)。當我們提到推薦引擎的時候,經常聯想到的技術也便是搜尋引擎。
搜尋引擎
而推薦引擎更傾向於人們沒有明確的目的,或者說他們的目的是模糊的,通俗來講,使用者連自己都不知道他想要什麼,這時候正是推薦引擎的使用者之地,推薦系統通過使用者的歷史行為或者使用者的興趣偏好或者使用者的人口統計學特徵來送給推薦演算法,然後推薦系統運用推薦演算法來產生使用者可能感興趣的專案列表,同時使用者對於搜尋引擎是被動的。其中長尾理論(人們只關注曝光率高的專案,而忽略曝光率低的專案)可以很好的解釋推薦系統的存在,試驗表明位於長尾位置的曝光率低的專案產生的利潤不低於只銷售曝光率高的專案的利潤。推薦系統正好可以給所有專案提供曝光的機會,以此來挖掘長尾專案的潛在利潤。
如果說搜尋引擎體現著馬太效應的話,那麼長尾理論則闡述了推薦系統所發揮的價值。
二、推薦系統的分類

三、主要的推薦演算法
推薦演算法大致可以分為以下幾類
- 基於流行度的演算法
- 協同過濾演算法(user-based CF and item-based CF)
- 基於內容的演算法(content-based)
- 基於模型的演算法
- 混合演算法
1. 基於流行度的演算法
可以按照一個專案的流行度進行排序,將最流行的專案推薦給使用者。比如在微博推薦中,將最為流行的大V使用者推薦給普通使用者。微博每日都有最熱門話題榜等等。
這種演算法的優點是簡單,適用於剛註冊的新使用者。缺點也很明顯,它無法針對使用者提供個性化的推薦。
2. 基於內容的演算法
基於內容的推薦(Content-based Recommendation)是 資訊過濾技術的延續與發展,它是建立在專案的內容資訊上作出推薦的,而不需要依據使用者對專案的評價意見,更多地需要用機 器學習的方法從關於內容的特徵描述的事例中得到使用者的興趣資料。在基於內容的推薦系統中,專案或物件是通過相關的特徵的屬性來定義,系統基於使用者評價物件 的特徵,學習使用者的興趣,考察使用者資料與待預測專案的相匹配程度。
基於內容的推薦演算法(Content-Based Recommendations CB)是最早被使用的推薦演算法,它的思想非常簡單:根據使用者過去喜歡的物品(本文統稱為 item),為使用者推薦和他過去喜歡的物品相似的物品。而關鍵就在於這裡的物品相似性的度量,這才是演算法運用過程中的核心。 CB最早主要是應用在資訊檢索系統當中,所以很多資訊檢索及資訊過濾裡的方法都能用於CB中。
3.協同過濾演算法
顧名思義,它是通過集體智慧的力量來進行工作,過濾掉那些使用者不感興趣的專案。協同過濾是基於這樣的假設:為特定使用者找到他真正感興趣的內容的好方法是首先找到與此使用者有相似興趣的其他使用者,然後將他們感興趣的內容推薦給此使用者。
它一般採用最近鄰技術,利用使用者的歷史喜好資訊計算使用者之間的距離,然後利用目標使用者的最近鄰居使用者對商品評價的加權評價值來預測目標使用者對特定商品的喜好程度,系統從而根據這一喜好程度來對目標使用者進行推薦,通常需要用到UI矩陣的資訊。協同過濾推薦又可以根據是否運用機器學習的思想進一步劃分為基於記憶體的協同過濾推薦(Memory-based CF)和基於模型的協同過濾推薦(Model-based CF)。
4. 基於模型的演算法
協同過濾演算法在大資料情況下,由於計算量較大,不能做到實時的對使用者進行推薦。基於模型的協同過濾演算法有效的解決了這一問題,矩陣分解(Matrix Factorization, MF)是基於模型的協同過濾演算法中的一種。在基於模型的協同過濾演算法中,利用歷史資料訓練得到模型,並利用該模型實現實時推薦
5. 混合演算法
現實應用中,其實很少有直接用某種演算法來做推薦的系統。在一些大的網站如Netflix,就是融合了數十種演算法的推薦系統。我們可以通過給不同演算法的結果加權重來綜合結果,或者是在不同的計算環節中運用不同的演算法來混合,達到更貼合自己業務的目的。