
【面試題】Netty相關
1.BIO、NIO和AIO的區別?
- BIO:一個連線一個執行緒,客戶端有連線請求時伺服器端就需要啟動一個執行緒進行處理。執行緒開銷大。
- 偽非同步IO:將請求連線放入執行緒池,一對多,但執行緒還是很寶貴的資源。
- NIO:一個請求一個執行緒,但客戶端傳送的連線請求都會註冊到多路複用器上,多路複用器輪詢到連線有I/O請求時才啟動一個執行緒進行處理。
AIO:一個有效請求一個執行緒,客戶端的I/O請求都是由OS先完成了再通知伺服器應用去啟動執行緒進行處理,
BIO是面向流的,NIO是面向緩衝區的;BIO的各種流是阻塞的。而NIO是非阻塞的;BIO的Stream是單向的,而NIO的channel是雙向的。
NIO的特點:事件驅動模型、單執行緒處理多工、非阻塞I/O,I/O讀寫不再阻塞,而是返回0、基於block的傳輸比基於流的傳輸更高效、更高階的IO函式zero-copy、IO多路複用大大提高了Java網路應用的可伸縮性和實用性。基於Reactor執行緒模型。
在Reactor模式中,事件分發器等待某個事件或者可應用或個操作的狀態發生,事件分發器就把這個事件傳給事先註冊的事件處理函式或者回調函式,由後者來做實際的讀寫操作。如在Reactor中實現讀:註冊讀就緒事件和相應的事件處理器、事件分發器等待事件、事件到來,啟用分發器,分發器呼叫事件對應的處理器、事件處理器完成實際的讀操作,處理讀到的資料,註冊新的事件,然後返還控制權。
2.NIO的組成?
Buffer:與Channel進行互動,資料是從Channel讀入緩衝區,從緩衝區寫入Channel中的
- flip方法 : 反轉此緩衝區,將position給limit,然後將position置為0,其實就是切換讀寫模式
- clear方法 :清除此緩衝區,將position置為0,把capacity的值給limit。
- rewind方法 : 重繞此緩衝區,將position置為0
DirectByteBuffer可減少一次系統空間到使用者空間的拷貝。但Buffer建立和銷燬的成本更高,不可控,通常會用記憶體池來提高效能。直接緩衝區主要分配給那些易受基礎系統的本機I/O 操作影響的大型、持久的緩衝區。如果資料量比較小的中小應用情況下,可以考慮使用heapBuffer,由JVM進行管理。
Channel:表示 IO 源與目標開啟的連線,是雙向的,但不能直接訪問資料,只能與Buffer 進行互動。通過原始碼可知,FileChannel的read方法和write方法都導致資料複製了兩次!
Selector可使一個單獨的執行緒管理多個Channel,open方法可建立Selector,register方法向多路複用器器註冊通道,可以監聽的事件型別:讀、寫、連線、accept。註冊事件後會產生一個SelectionKey:它表示SelectableChannel 和Selector 之間的註冊關係,wakeup方法:使尚未返回的第一個選擇操作立即返回,喚醒的原因是:註冊了新的channel或者事件;channel關閉,取消註冊;優先順序更高的事件觸發(如定時器事件),希望及時處理。
Selector在Linux的實現類是EPollSelectorImpl,委託給EPollArrayWrapper實現,其中三個native方法是對epoll的封裝,而EPollSelectorImpl. implRegister方法,通過呼叫epoll_ctl向epoll例項中註冊事件,還將註冊的檔案描述符(fd)與SelectionKey的對應關係新增到fdToKey中,這個map維護了檔案描述符與SelectionKey的對映。
fdToKey有時會變得非常大,因為註冊到Selector上的Channel非常多(百萬連線);過期或失效的Channel沒有及時關閉。fdToKey總是序列讀取的,而讀取是在select方法中進行的,該方法是非執行緒安全的。
Pipe:兩個執行緒之間的單向資料連線,資料會被寫到sink通道,從source通道讀取
NIO的服務端建立過程:Selector.open():開啟一個Selector;ServerSocketChannel.open():建立服務端的Channel;bind():繫結到某個埠上。並配置非阻塞模式;register():註冊Channel和關注的事件到Selector上;select()輪詢拿到已經就緒的事件
3.Netty的特點?
- 一個高效能、非同步事件驅動的NIO框架,它提供了對TCP、UDP和檔案傳輸的支援
- 使用更高效的socket底層,對epoll空輪詢引起的cpu佔用飆升在內部進行了處理,避免了直接使用NIO的陷阱,簡化了NIO的處理方式。
- 採用多種decoder/encoder 支援,對TCP粘包/分包進行自動化處理
- 可使用接受/處理執行緒池,提高連線效率,對重連、心跳檢測的簡單支援
- 可配置IO執行緒數、TCP引數, TCP接收和傳送緩衝區使用直接記憶體代替堆記憶體,通過記憶體池的方式迴圈利用ByteBuf
- 通過引用計數器及時申請釋放不再引用的物件,降低了GC頻率
- 使用單執行緒序列化的方式,高效的Reactor執行緒模型
- 大量使用了volitale、使用了CAS和原子類、執行緒安全類的使用、讀寫鎖的使用
4.Netty的執行緒模型?
Netty通過Reactor模型基於多路複用器接收並處理使用者請求,內部實現了兩個執行緒池,boss執行緒池和work執行緒池,其中boss執行緒池的執行緒負責處理請求的accept事件,當接收到accept事件的請求時,把對應的socket封裝到一個NioSocketChannel中,並交給work執行緒池,其中work執行緒池負責請求的read和write事件,由對應的Handler處理。
單執行緒模型:所有I/O操作都由一個執行緒完成,即多路複用、事件分發和處理都是在一個Reactor執行緒上完成的。既要接收客戶端的連線請求,向服務端發起連線,又要傳送/讀取請求或應答/響應訊息。一個NIO 執行緒同時處理成百上千的鏈路,效能上無法支撐,速度慢,若執行緒進入死迴圈,整個程式不可用,對於高負載、大併發的應用場景不合適。
多執行緒模型:有一個NIO 執行緒(Acceptor) 只負責監聽服務端,接收客戶端的TCP 連線請求;NIO 執行緒池負責網路IO 的操作,即訊息的讀取、解碼、編碼和傳送;1 個NIO 執行緒可以同時處理N 條鏈路,但是1 個鏈路只對應1 個NIO 執行緒,這是為了防止發生併發操作問題。但在併發百萬客戶端連線或需要安全認證時,一個Acceptor 執行緒可能會存在效能不足問題。
主從多執行緒模型:Acceptor 執行緒用於繫結監聽埠,接收客戶端連線,將SocketChannel 從主執行緒池的Reactor 執行緒的多路複用器上移除,重新註冊到Sub 執行緒池的執行緒上,用於處理I/O 的讀寫等操作,從而保證mainReactor只負責接入認證、握手等操作;
5.TCP 粘包/拆包的原因及解決方法?
TCP是以流的方式來處理資料,一個完整的包可能會被TCP拆分成多個包進行傳送,也可能把小的封裝成一個大的資料包傳送。
TCP粘包/分包的原因:
- 應用程式寫入的位元組大小大於套接字傳送緩衝區的大小,會發生拆包現象,而應用程式寫入資料小於套接字緩衝區大小,網絡卡將應用多次寫入的資料傳送到網路上,這將會發生粘包現象;
- 進行MSS大小的TCP分段,當TCP報文長度-TCP頭部長度>MSS的時候將發生拆包
- 乙太網幀的payload(淨荷)大於MTU(1500位元組)進行ip分片。
解決方法
- 訊息定長:FixedLengthFrameDecoder類
- 包尾增加特殊字元分割:行分隔符類:LineBasedFrameDecoder或自定義分隔符類 :DelimiterBasedFrameDecoder
- 將訊息分為訊息頭和訊息體:LengthFieldBasedFrameDecoder類。分為有頭部的拆包與粘包、長度欄位在前且有頭部的拆包與粘包、多擴充套件頭部的拆包與粘包。
6.瞭解哪幾種序列化協議?
序列化(編碼)是將物件序列化為二進位制形式(位元組陣列),主要用於網路傳輸、資料持久化等;而反序列化(解碼)則是將從網路、磁碟等讀取的位元組陣列還原成原始物件,主要用於網路傳輸物件的解碼,以便完成遠端呼叫。
影響序列化效能的關鍵因素:序列化後的碼流大小(網路頻寬的佔用)、序列化的效能(CPU資源佔用);是否支援跨語言(異構系統的對接和開發語言切換)。
Java預設提供的序列化:無法跨語言、序列化後的碼流太大、序列化的效能差
XML,優點:人機可讀性好,可指定元素或特性的名稱。缺點:序列化資料只包含資料本身以及類的結構,不包括型別標識和程式集資訊;只能序列化公共屬性和欄位;不能序列化方法;檔案龐大,檔案格式複雜,傳輸佔頻寬。適用場景:當做配置檔案儲存資料,實時資料轉換。
JSON,是一種輕量級的資料交換格式,優點:相容性高、資料格式比較簡單,易於讀寫、序列化後資料較小,可擴充套件性好,相容性好、與XML相比,其協議比較簡單,解析速度比較快。缺點:資料的描述性比XML差、不適合效能要求為ms級別的情況、額外空間開銷比較大。適用場景(可替代XML):跨防火牆訪問、可調式性要求高、基於Web browser的Ajax請求、傳輸資料量相對小,實時性要求相對低(例如秒級別)的服務。
Fastjson,採用一種“假定有序快速匹配”的演算法。優點:介面簡單易用、目前java語言中最快的json庫。缺點:過於注重快,而偏離了“標準”及功能性、程式碼質量不高,文件不全。適用場景:協議互動、Web輸出、Android客戶端
Thrift,不僅是序列化協議,還是一個RPC框架。優點:序列化後的體積小, 速度快、支援多種語言和豐富的資料型別、對於資料欄位的增刪具有較強的相容性、支援二進位制壓縮編碼。缺點:使用者較少、跨防火牆訪問時,不安全、不具有可讀性,除錯程式碼時相對困難、不能與其他傳輸層協議共同使用(例如HTTP)、無法支援向持久層直接讀寫資料,即不適合做資料持久化序列化協議。適用場景:分散式系統的RPC解決方案
Avro,Hadoop的一個子專案,解決了JSON的冗長和沒有IDL的問題。優點:支援豐富的資料型別、簡單的動態語言結合功能、具有自我描述屬性、提高了資料解析速度、快速可壓縮的二進位制資料形式、可以實現遠端過程呼叫RPC、支援跨程式語言實現。缺點:對於習慣於靜態型別語言的使用者不直觀。適用場景:在Hadoop中做Hive、Pig和MapReduce的持久化資料格式。
Protobuf,將資料結構以.proto檔案進行描述,通過程式碼生成工具可以生成對應資料結構的POJO物件和Protobuf相關的方法和屬性。優點:序列化後碼流小,效能高、結構化資料儲存格式(XML JSON等)、通過標識欄位的順序,可以實現協議的前向相容、結構化的文件更容易管理和維護。缺點:需要依賴於工具生成程式碼、支援的語言相對較少,官方只支援Java 、C++ 、python。適用場景:對效能要求高的RPC呼叫、具有良好的跨防火牆的訪問屬性、適合應用層物件的持久化
其它
- protostuff 基於protobuf協議,但不需要配置proto檔案,直接導包即可
- Jboss marshaling 可以直接序列化java類, 無須實java.io.Serializable介面
- Message pack 一個高效的二進位制序列化格式
- Hessian 採用二進位制協議的輕量級remoting onhttp工具
- kryo 基於protobuf協議,只支援java語言,需要註冊(Registration),然後序列化(Output),反序列化(Input)
7.如何選擇序列化協議?
具體場景
- 對於公司間的系統呼叫,如果效能要求在100ms以上的服務,基於XML的SOAP協議是一個值得考慮的方案。
- 基於Web browser的Ajax,以及Mobile app與服務端之間的通訊,JSON協議是首選。對於效能要求不太高,或者以動態型別語言為主,或者傳輸資料載荷很小的的運用場景,JSON也是非常不錯的選擇。
- 對於除錯環境比較惡劣的場景,採用JSON或XML能夠極大的提高除錯效率,降低系統開發成本。
- 當對效能和簡潔性有極高要求的場景,Protobuf,Thrift,Avro之間具有一定的競爭關係。
- 對於T級別的資料的持久化應用場景,Protobuf和Avro是首要選擇。如果持久化後的資料儲存在hadoop子專案裡,Avro會是更好的選擇。
- 對於持久層非Hadoop專案,以靜態型別語言為主的應用場景,Protobuf會更符合靜態型別語言工程師的開發習慣。由於Avro的設計理念偏向於動態型別語言,對於動態語言為主的應用場景,Avro是更好的選擇。
- 如果需要提供一個完整的RPC解決方案,Thrift是一個好的選擇。
- 如果序列化之後需要支援不同的傳輸層協議,或者需要跨防火牆訪問的高效能場景,Protobuf可以優先考慮。
protobuf的資料型別有多種:bool、double、float、int32、int64、string、bytes、enum、message。protobuf的限定符:required: 必須賦值,不能為空、optional:欄位可以賦值,也可以不賦值、repeated: 該欄位可以重複任意次數(包括0次)、列舉;只能用指定的常量集中的一個值作為其值;
protobuf的基本規則:每個訊息中必須至少留有一個required型別的欄位、包含0個或多個optional型別的欄位;repeated表示的欄位可以包含0個或多個數據;[1,15]之內的標識號在編碼的時候會佔用一個位元組(常用),[16,2047]之內的標識號則佔用2個位元組,標識號一定不能重複、使用訊息型別,也可以將訊息巢狀任意多層,可用巢狀訊息型別來代替組。
protobuf的訊息升級原則:不要更改任何已有的欄位的數值標識;不能移除已經存在的required欄位,optional和repeated型別的欄位可以被移除,但要保留標號不能被重用。新新增的欄位必須是optional或repeated。因為舊版本程式無法讀取或寫入新增的required限定符的欄位。
編譯器為每一個訊息型別生成了一個.java檔案,以及一個特殊的Builder類(該類是用來建立訊息類介面的)。如:UserProto.User.Builder builder = UserProto.User.newBuilder();builder.build();
Netty中的使用:ProtobufVarint32FrameDecoder 是用於處理半包訊息的解碼類;ProtobufDecoder(UserProto.User.getDefaultInstance())這是建立的UserProto.java檔案中的解碼類;ProtobufVarint32LengthFieldPrepender 對protobuf協議的訊息頭上加上一個長度為32的整形欄位,用於標誌這個訊息的長度的類;ProtobufEncoder 是編碼類
將StringBuilder轉換為ByteBuf型別:copiedBuffer()方法
8.Netty的零拷貝實現?
Netty的接收和傳送ByteBuffer採用DIRECT BUFFERS,使用堆外直接記憶體進行Socket讀寫,不需要進行位元組緩衝區的二次拷貝。堆記憶體多了一次記憶體拷貝,JVM會將堆記憶體Buffer拷貝一份到直接記憶體中,然後才寫入Socket中。ByteBuffer由ChannelConfig分配,而ChannelConfig建立ByteBufAllocator預設使用Direct Buffer
CompositeByteBuf 類可以將多個 ByteBuf 合併為一個邏輯上的 ByteBuf, 避免了傳統通過記憶體拷貝的方式將幾個小Buffer合併成一個大的Buffer。addComponents方法將 header 與 body 合併為一個邏輯上的 ByteBuf, 這兩個 ByteBuf 在CompositeByteBuf 內部都是單獨存在的, CompositeByteBuf 只是邏輯上是一個整體
通過 FileRegion 包裝的FileChannel.tranferTo方法 實現檔案傳輸, 可以直接將檔案緩衝區的資料傳送到目標 Channel,避免了傳統通過迴圈write方式導致的記憶體拷貝問題。
通過 wrap方法, 我們可以將 byte[] 陣列、ByteBuf、ByteBuffer等包裝成一個 Netty ByteBuf 物件, 進而避免了拷貝操作。
Selector BUG:若Selector的輪詢結果為空,也沒有wakeup或新訊息處理,則發生空輪詢,CPU使用率100%,
Netty的解決辦法:對Selector的select操作週期進行統計,每完成一次空的select操作進行一次計數,若在某個週期內連續發生N次空輪詢,則觸發了epoll死迴圈bug。重建Selector,判斷是否是其他執行緒發起的重建請求,若不是則將原SocketChannel從舊的Selector上去除註冊,重新註冊到新的Selector上,並將原來的Selector關閉。
9.Netty的高效能表現在哪些方面?
心跳,對服務端:會定時清除閒置會話inactive(netty5),對客戶端:用來檢測會話是否斷開,是否重來,檢測網路延遲,其中idleStateHandler類 用來檢測會話狀態
序列無鎖化設計,即訊息的處理儘可能在同一個執行緒內完成,期間不進行執行緒切換,這樣就避免了多執行緒競爭和同步鎖。表面上看,序列化設計似乎CPU利用率不高,併發程度不夠。但是,通過調整NIO執行緒池的執行緒引數,可以同時啟動多個序列化的執行緒並行執行,這種區域性無鎖化的序列執行緒設計相比一個佇列-多個工作執行緒模型效能更優。
可靠性,鏈路有效性檢測:鏈路空閒檢測機制,讀/寫空閒超時機制;記憶體保護機制:通過記憶體池重用ByteBuf;ByteBuf的解碼保護;優雅停機:不再接收新訊息、退出前的預處理操作、資源的釋放操作。
Netty安全性:支援的安全協議:SSL V2和V3,TLS,SSL單向認證、雙向認證和第三方CA認證。
高效併發程式設計的體現:volatile的大量、正確使用;CAS和原子類的廣泛使用;執行緒安全容器的使用;通過讀寫鎖提升併發效能。IO通訊效能三原則:傳輸(AIO)、協議(Http)、執行緒(主從多執行緒)
流量整型的作用(變壓器):防止由於上下游網元效能不均衡導致下游網元被壓垮,業務流中斷;防止由於通訊模組接受訊息過快,後端業務執行緒處理不及時導致撐死問題。
TCP引數配置:SO_RCVBUF和SO_SNDBUF:通常建議值為128K或者256K;SO_TCPNODELAY:NAGLE演算法通過將緩衝區內的小封包自動相連,組成較大的封包,阻止大量小封包的傳送阻塞網路,從而提高網路應用效率。但是對於時延敏感的應用場景需要關閉該優化演算法;
10.NIOEventLoopGroup原始碼?
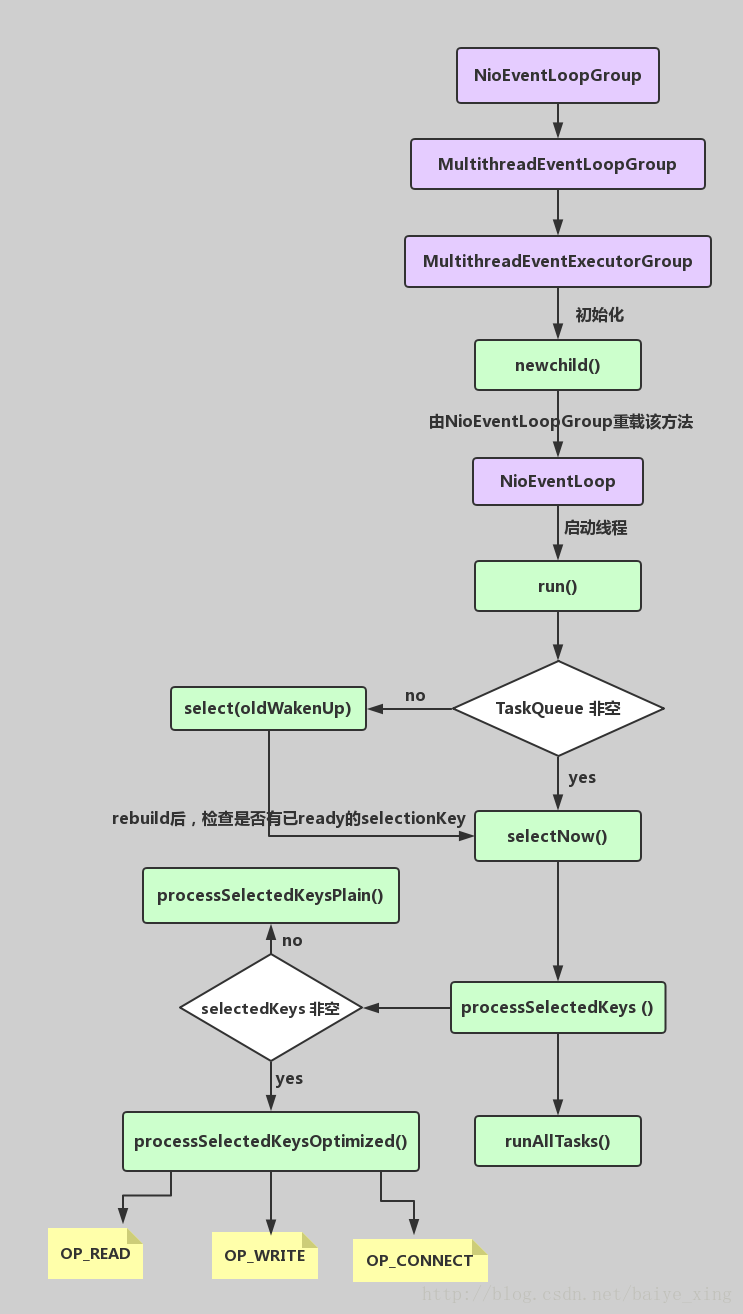
NioEventLoopGroup(其實是MultithreadEventExecutorGroup) 內部維護一個型別為 EventExecutor children [], 預設大小是處理器核數 * 2, 這樣就構成了一個執行緒池,初始化EventExecutor時NioEventLoopGroup過載newChild方法,所以children元素的實際型別為NioEventLoop。
執行緒啟動時呼叫SingleThreadEventExecutor的構造方法,執行NioEventLoop類的run方法,首先會呼叫hasTasks()方法判斷當前taskQueue是否有元素。如果taskQueue中有元素,執行 selectNow() 方法,最終執行selector.selectNow(),該方法會立即返回。如果taskQueue沒有元素,執行 select(oldWakenUp) 方法
select ( oldWakenUp) 方法解決了 Nio 中的 bug,selectCnt 用來記錄selector.select方法的執行次數和標識是否執行過selector.selectNow(),若觸發了epoll的空輪詢bug,則會反覆執行selector.select(timeoutMillis),變數selectCnt 會逐漸變大,當selectCnt 達到閾值(預設512),則執行rebuildSelector方法,進行selector重建,解決cpu佔用100%的bug。
rebuildSelector方法先通過openSelector方法建立一個新的selector。然後將old selector的selectionKey執行cancel。最後將old selector的channel重新註冊到新的selector中。rebuild後,需要重新執行方法selectNow,檢查是否有已ready的selectionKey。
接下來呼叫processSelectedKeys 方法(處理I/O任務),當selectedKeys != null時,呼叫processSelectedKeysOptimized方法,迭代 selectedKeys 獲取就緒的 IO 事件的selectkey存放在陣列selectedKeys中, 然後為每個事件都呼叫 processSelectedKey 來處理它,processSelectedKey 中分別處理OP_READ;OP_WRITE;OP_CONNECT事件。
最後呼叫runAllTasks方法(非IO任務),該方法首先會呼叫fetchFromScheduledTaskQueue方法,把scheduledTaskQueue中已經超過延遲執行時間的任務移到taskQueue中等待被執行,然後依次從taskQueue中取任務執行,每執行64個任務,進行耗時檢查,如果已執行時間超過預先設定的執行時間,則停止執行非IO任務,避免非IO任務太多,影響IO任務的執行。
每個NioEventLoop對應一個執行緒和一個Selector,NioServerSocketChannel會主動註冊到某一個NioEventLoop的Selector上,NioEventLoop負責事件輪詢。
Outbound 事件都是請求事件, 發起者是 Channel,處理者是 unsafe,通過 Outbound 事件進行通知,傳播方向是 tail到head。Inbound 事件發起者是 unsafe,事件的處理者是 Channel, 是通知事件,傳播方向是從頭到尾。
記憶體管理機制,首先會預申請一大塊記憶體Arena,Arena由許多Chunk組成,而每個Chunk預設由2048個page組成。Chunk通過AVL樹的形式組織Page,每個葉子節點表示一個Page,而中間節點表示記憶體區域,節點自己記錄它在整個Arena中的偏移地址。當區域被分配出去後,中間節點上的標記位會被標記,這樣就表示這個中間節點以下的所有節點都已被分配了。大於8k的記憶體分配在poolChunkList中,而PoolSubpage用於分配小於8k的記憶體,它會把一個page分割成多段,進行記憶體分配。
ByteBuf的特點:支援自動擴容(4M),保證put方法不會丟擲異常、通過內建的複合緩衝型別,實現零拷貝(zero-copy);不需要呼叫flip()來切換讀/寫模式,讀取和寫入索引分開;方法鏈;引用計數基於AtomicIntegerFieldUpdater用於記憶體回收;PooledByteBuf採用二叉樹來實現一個記憶體池,集中管理記憶體的分配和釋放,不用每次使用都新建一個緩衝區物件。UnpooledHeapByteBuf每次都會新建一個緩衝區物件。
本人才疏學淺,若有錯,請指出,謝謝!
如果你有更好的建議,可以留言我們一起討論,共同進步!
衷心的感謝您能耐心的讀完本篇博文!