
【面試題】演算法相關
1.氣泡排序
思想:比較相鄰的元素。如果第一個比第二個大,就交換它們的值,從開始第一對到結尾的最後一對
程式碼實現:O(n2)、O(n)、O(n2)、O(1)、穩定。
public static void bubble(int[] array) {
for (int i = 0; i < array.length - 1; i++) {
for (int j = 0; j < array.length - i - 1; j++) {
if (array[j] > array[j + 1]) {
int 優化:加入標誌性變數flag,標誌某一趟排序過程中是否有資料交換,若沒有,則已經有序。
2.簡單選擇排序
思想:每趟從待排序的記錄中選出關鍵字最小的記錄,放在最前面,直到全部排序結束為止。
程式碼實現:O(n2)、O(n2)、O(n2)、O(1)、不穩定
public void 3.直接插入排序
思想:每次從無序表中取出第一個元素,把它插入到有序表的合適位置,使有序表仍然有序。
程式碼實現:O(n2)、O(n)、O(n2)、O(1)、穩定
private static void insertSort(int[] data) {
// 第1個數肯定是有序的,從第2個數開始遍歷,依次插入有序序列
for (int i = 1; i < data.length; i++) {
int temp = data[i];
// 取出第i個數,和前i-1個數比較後,插入合適位置
int j = i - 1;
// 只要當前比較的數(data[j])比temp小,就把這個數後移一位
while (j >= 0 && temp < data[j]) {
data[j + 1] = data[j];
j--;
}
data[j + 1] = temp;
}
}3.5折半插入排序
思想:折半插入演算法是對直接插入排序演算法的改進,它通過“折半查詢”在比較區查詢插入點的位置,這樣可以減少比較的次數,但移動的次數不變。
程式碼實現:O(n2)、O(1)、穩定
private static void binaryInsertSort(int[] a) {
int n = a.length;
int i,j;
for(i=1;i<n;i++){
//temp為本次迴圈待插入有序列表中的數
int temp = a[i];
int low=0;
int high=i-1;
//尋找temp插入有序列表的正確位置,使用二分查詢法
while(low <= high){
//有序陣列的中間座標,此時用於二分查詢,減少查詢次數
int mid = (low+high)/2;
//若有序陣列的中間元素大於待排序元素,則有序序列向中間元素之前搜尋,否則向後搜尋
if(a[mid]>temp){
high = mid-1;
}else{
low = mid+1;
}
}
for(j=i-1;j>=low;j--){
//元素後移,為插入temp做準備
a[j+1] = a[j];
}
//插入temp
a[low] = temp;
}
}4.希爾排序(縮小增量排序)
思想:將待排序的陣列元素分成多個子序列,對各個子序列分別進行直接插入排序,待整個待排序列“基本有序”後(步長逐漸減小為1),最後對所有元素進行一次直接插入排序。
程式碼實現:O(nlogn)、不穩定
public static void shellSort(int[] data) {
// 計算出最大的h值
int h = 1;
while (h <= data.length / 3) {
h = h * 3 + 1;
}
while (h >= 1) {
for (int i = h; i < data.length; i += h) {
if (data[i] < data[i - h]) {
int tmp = data[i];
int j = i - h;
while (j >= 0 && data[j] > tmp) {
data[j + h] = data[j];
j -= h;
}
data[j + h] = tmp;
}
}
// 計算出下一個h值
h = h / 3;
}
}5.歸併排序
思想:把待排序序列分為若干個子序列,每個子序列是有序的。然後再把有序子序列合併為整體有序序列。即先將序列每次折半劃分,再將劃分後的序列段兩兩合併後排序。分治法的應用。
程式碼實現:O(nlogn)、O(nlogn)、O(nlogn)、O(n)、穩定。
private static void mergeSort(int[] data,int start,int end) {
//找出中間索引
int mid = (start + end) / 2;
if (start < end) {
//對左邊陣列進行遞迴
mergeSort(data, start, mid);
//對右邊陣列進行遞迴
mergeSort(data, mid + 1, end);
//合併
merge(data, start, mid, end);
}
}
public static void merge(int[] data,int start,int mid,int end) {
//用ArrayList來臨時存放陣列
List<Integer> list = new ArrayList<>();
//記錄左邊陣列的第一個索引
int s = start;
//記錄右邊陣列的第一個索引
int index = mid + 1;
while (start <= mid && index <= end) {
//從兩個陣列中取出最小的放入ArrayList中
if (data[start] < data[index]) {
list.add(data[start++]);
} else {
list.add(data[index++]);
}
}
//左邊剩餘部分依次放入ArrayList中
while (start <= mid) {
list.add(data[start++]);
}
//右邊剩餘部分依次放入ArrayList中
while (index <= end) {
list.add(data[index++]);
}
//將ArrayList中的數值拷貝到原陣列中
for (int datas : list) {
data[s++] = datas;
}
}6.快速排序
思想:陣列中的每個元素與基準值比較,陣列中比基準值小的放在基準值的左邊,形成左部;大的放在右邊,形成右部;接下來將左部和右部分別遞迴地執行上面的過程,直到排序結束。採取分而治之的思想。
程式碼實現:O(nlogn)、O(nlogn)、O(n2)、O(nlogn)、不穩定。
public static void sort (int[] data , int left,int right) {
if (left>right) {
return;
}
//獲取下次分割的基準標號
int mid = getMid(data,left,right);
//對“基準標號“左側的一組數值進行遞迴的切割,以至於將這些數值完整的排序
sort(data,left,mid-1);
//對“基準標號“右側的一組數值進行遞迴的切割,以至於將這些數值完整的排序
sort(data,mid+1,right);
}
public static int getMid(int[] data,int left,int right){
//以最左邊的數為基準
int pivot = data[left];
while (left<right){
//從右端開始,向左遍歷,直到找到小於pivot的數
while(left<right && data[right] > pivot){
right--;
}
//將比pivot小的元素放到最左邊
data[left] = data[right];
//從左端開始,向右遍歷,直到找到大於pivot的數
while(left<right && data[left] < pivot){
left++;
}
//將比pivot大的元素放到最右邊
data[right] = data[left];
}
//將pivot放到left的位置,
data[left] = pivot;
return left;
}
- 優化:三者取中演算法改進(固定值 或隨機數)、優化小陣列時的排序方案、優化遞迴操作。
7.堆排序
思想:
- 建堆是不斷調整堆的過程,從len/2處開始調整,一直到第一個節點,
- 比較節點i和它的孩子節點left(i),right(i),選出三者最大(或者最小)者,如果最大(小)值不是節點i而是它的一個孩子節點,那邊互動節點i和該節點,然後再呼叫調整堆過程,這是一個遞迴的過程。
- 根據元素構建堆。然後將堆的根節點取出(一般是與最後一個節點進行交換),將前面len-1個節點繼續進行堆調整的過程,然後再將根節點取出,這樣一直到所有節點都取出。
程式碼實現:O(nlogn)、O(nlogn)、O(nlogn)、O(1)、不穩定。
//堆排序
static void sort(int[] datas){
creat(datas);
for(int i = datas.length-1; i>0; i--){
swap(datas, 0, i);
adjust(datas, 0, i);
}
}
//建立大根堆
static void creat(int[] datas) {
//找到第一個非葉子節點
for(int i = datas.length/2 - 1; i >= 0; i--){
adjust(datas, i, datas.length);
}
}
//調整為大根堆
static void adjust(int[] datas, int root, int length) {
//獲得左子樹
int left = 2*root+1;
if (left >= length){
return;
}
//若右子樹大於左子樹,則取右孩子
if (left+1< length && datas[left] < datas[left + 1]){
left++;
}
//若左子樹大於根節點,則互換值,再調整堆。
if(datas[root] < datas[left]){
swap(datas, root, left);
adjust(datas,left,length);
}
}
//資料交換
private static void swap(int[] datas, int i, int j){
int temp = datas[i];
datas[i] = datas[j];
datas[j] = temp;
}
8.基數排序
思想:(桶排序)一種分配式排序,即通過將所有數字分配到應在的位置最後再覆蓋到原陣列完成排序的過程。將所有待比較數值(正整數)統一為同樣的數位長度,數位較短的數前面補零。然後,從最低位開始,依次進行一次排序。這樣從最低位排序一直到最高位排序完成以後,數列就變成一個有序序列。
程式碼實現(LSD):O(d(n+r)),r為基數,d為位數、穩定
public void radixSort(int[] list, int begin, int end, int digit) {
final int radix = 10; // 基數
int i = 0, j = 0;
int[] count = new int[radix]; // 存放各個桶的資料統計個數
int[] bucket = new int[end - begin + 1];
// 按照從低位到高位的順序執行排序過程
for (int d = 1; d <= digit; d++) {
// 置空各個桶的資料統計
for (i = 0; i < radix; i++) {
count[i] = 0;
}
// 統計各個桶將要裝入的資料個數
for (i = begin; i <= end; i++) {
j = getDigit(list[i], d);
count[j]++;
}
// count[i]表示第i個桶的右邊界索引
for (i = 1; i < radix; i++) {
count[i] = count[i] + count[i - 1];
}
// 將資料依次裝入桶中
// 這裡要從右向左掃描,保證排序穩定性
for (i = end; i >= begin; i--) {
// 求出關鍵碼的第k位的數字, 例如:576的第3位是5
j = getDigit(list[i], d);
// 放入對應的桶中,count[j]-1是第j個桶的右邊界索引
bucket[count[j] - 1] = list[i];
// 對應桶的裝入資料索引減一
count[j]--;
}
// 將已分配好的桶中資料再倒出來,此時已是對應當前位數有序的表
for (i = begin, j = 0; i <= end; i++, j++) {
list[i] = bucket[j];
}
}
}
public int[] sort(int[] list) {
radixSort(list, 0, list.length - 1, 3);
return list;
}9.八大排序演算法的總結
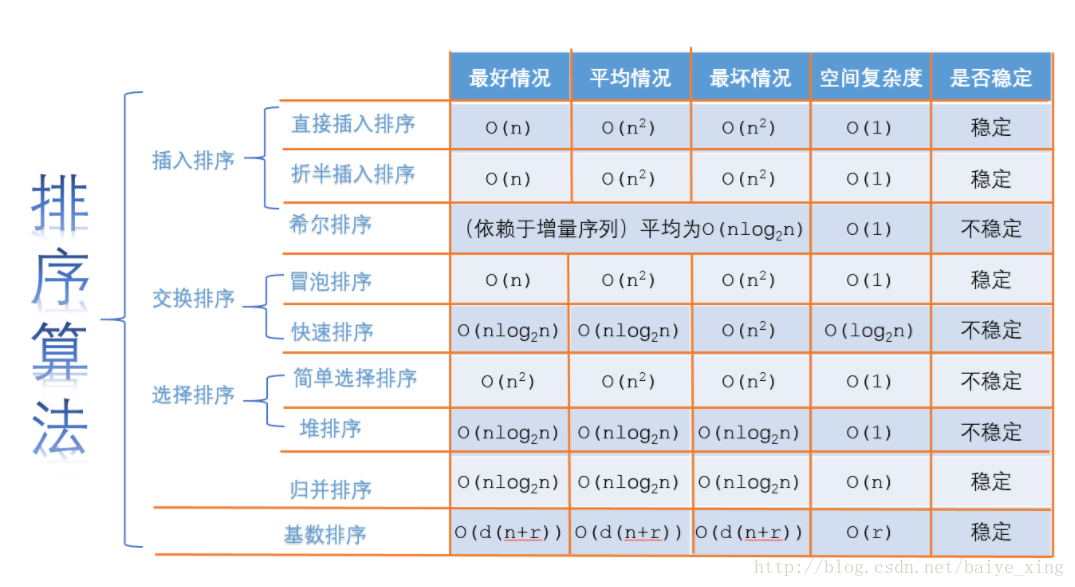
當資料很小時,使用插入(資料有序)、簡單選擇、氣泡排序。
當資料規模一般時,使用快速排序(無序)、歸併排序。
當資料規模很大時,使用歸併(穩定)、桶排序。
10.RSA加密演算法
- 隨意選擇兩個大的質數p和q,p不等於q,計算N=pq。
- 根據尤拉函式,求得r = (p-1)(q-1)
- 選擇一個小於 r 的整數 e,求得 e 關於模 r 的模反元素,命名為d。(模反元素存在,當且僅當e與r互質)
- 將 p 和 q 的記錄銷燬。
(N,e)是公鑰,(N,d)是私鑰。Alice將她的公鑰(N,e)傳給Bob,而將她的私鑰(N,d)藏起來。
RSA的缺點:產生金鑰很麻煩,受到素數產生技術的限制,因而難以做到一次一密;速度太慢:分組長度太大,為保證安全性,n 至少也要 600 bits 以上,使運算代價很高;安全性,RSA的安全性依賴於大數的因子分解,但並沒有從理論上證明破譯RSA的難度與大數分解難度等價,而且密碼學界多數人士傾向於因子分解不是NP問題。
11.負載均衡
LB是一種伺服器或網路裝置的叢集技術。負載均衡將特定的業務(網路服務、網路流量等)分擔給多個伺服器或網路裝置,從而提高了業務處理能力,保證了業務的高可用性。
負載均衡策略:請求輪詢、最少連線路由、ip雜湊、
負載均衡的例項
- http重定向:請求後返回一個新的URL,但有吞吐率限制、重定向訪問深度不同的缺點
- DNS負載均衡:為一個域名配置多個不同的IP地址,但DNS記錄快取不同
- 反向代理:使用者和實際伺服器中間人的角色,可以監控後端伺服器,但需要一定開銷。
- IP負載均衡:工作在傳輸層的NAT伺服器,可以修改傳送來的IP資料包,將資料包的目標地址修改為實際伺服器地址。
- 直接路由:工作在資料鏈路層,通過修改資料包的目標MAC地址(沒有修改目標IP),將資料包轉發到實際伺服器上。
- IP隧道:將排程器收到的IP資料包封裝在一個新的IP資料包中,轉交給實際伺服器,然後實際伺服器的響應資料包可以直接到達使用者端
12.一致性雜湊演算法
一致性雜湊的特點:平衡性、單調性、分散性、負載。
原理:將整個雜湊值空間組織成一個虛擬的圓環,如假設某雜湊函式H的值空間為0-2^32-1,可以選擇伺服器的ip或主機名作為關鍵字進行雜湊,這樣每臺機器就能確定其在雜湊環上的位置。從此位置沿環順時針“行走”,第一臺遇到的伺服器就是其應該定位到的伺服器。
虛擬節點:解決在服務節點太少時,容易因為節點分部不均勻而造成資料傾斜的問題。還可以解決因熱點資料造成雪崩的問題,對熱點區間進行劃分,將掛掉的伺服器的資料分配至其他伺服器
13.KMP演算法
KMP演算法是當遇到不匹配字元時,根據前面已匹配的字元數和模式串字首和字尾的最大相同字串長度陣列next的元素來確定向後移動的位數,預處理時間複雜度是O(m),匹配時間複雜度是O(n)
KMP演算法的核心就是求next陣列,在字串匹配的過程中,一旦某個字元匹配不成功,next陣列就會指導模式串P到底該相對於S右移多少位再進行下一次匹配,從而避免無效的匹配。
next陣列含義:代表在模式串P中,當前下標對應的字元之前的字串中,有多大長度的相同字首字尾。例如如果next [j] = k,代表在模式串P中,下標為j的字元之前的字串中有最大長度為k 的相同字首字尾。
next陣列求解方法:next[0] = -1。如果p[j] = p[k], 則next[j+1] = next[k] + 1;
如果p[j] != p[k], 則令k=next[k],如果此時p[j]==p[k],則next[j+1]=k+1,如果不相等,則繼續遞迴字首索引,令 k=next[k],繼續判斷,直至k=-1(即k=next[0])或者p[j]=p[k]為止程式碼實現
public void KMPMatcher() {
int n = text.length();
int m = pattern.length();
int prefix[] = computePrefix();
int q = 0;
int count = 0;
for(int i = 0; i < n; i++) {
while(q > 0 && pattern.charAt(q)!= text.charAt(i)) {
q = prefix[q -1];
}
if(pattern.charAt(q) == text.charAt(i))
q++;
if(q == m) {
System.out.println("Pattern occurs with shift " + ++count + "times");
q = prefix[q - 1];
}
}
if(count == 0) {
System.out.println("There is no matcher!");
}
}
//求解Next陣列
private int[] computePrefix() {
int length = pattern.length();
int[] prefix = new int[length];
prefix[0] = 0;
int k = 0;
for(int i = 1; i < length; i++) {
while(k > 0 && pattern.charAt(k) != pattern.charAt(i)) {
k = prefix[k -1];
}
if(pattern.charAt(k) == pattern.charAt(i))
k++;
prefix[i] = k;
}
return prefix;
}
//求解Next陣列的另一種方法
protected int[] getNext(char[] p) {
// 已知next[j] = k,利用遞迴的思想求出next[j+1]的值
// 如果已知next[j] = k,如何求出next[j+1]呢?具體演算法如下:
// 1. 如果p[j] = p[k], 則next[j+1] = next[k] + 1;
// 2. 如果p[j] != p[k], 則令k=next[k],如果此時p[j]==p[k],則next[j+1]=k+1,
// 如果不相等,則繼續遞迴字首索引,令 k=next[k],繼續判斷,直至k=-1(即k=next[0])或者p[j]=p[k]為止
int pLen = p.length;
int[] next = new int[pLen];
int k = -1;
int j = 0;
next[0] = -1; // next陣列中next[0]為-1
while (j < pLen - 1) {
//k表示字首的單個字元,j表示字尾的單個字元
if (k == -1 || p[j] == p[k]) {
k++;
j++;
next[j] = k;
} else {
//k回溯
k = next[k];
}
}
return next;
}
本人才疏學淺,若有錯,請指出,謝謝!
如果你有更好的建議,可以留言我們一起討論,共同進步!
衷心的感謝您能耐心的讀完本篇博文!