
第10章-基於樹的方法(1)-生成樹
一,本章簡介
1,本章主要學習目標
- 理解決策樹的基本概念
- 理解構成決策樹的三個基本元素
- 理解’不純度’及其他度量公式的定義
- 知道如何估計每個樹節點的各個所屬分類的後驗概率
- 理解基於樹的分類方法的優點
- 理解訓練誤差(或稱再代入誤差) 和 代價複雜度測量方法,知道它們的區別,以及為什麼要介紹這種方法
- 理解 weakest-link pruning (等價代價複雜度剪枝)
- 理解剪枝後的最優子樹都是互相嵌入的,可以被遞迴地獲取
- 理解基於交叉驗證來選擇複雜性的引數和最終子樹的方法
- 理解的model averaging目的
- 理解裝袋法(bagging)的步驟
- 理解隨機森林(random forest)的步驟
- 理解提升法(boosting)的步驟
決策樹既可以解決迴歸問題也可以解決分類問題。下面我們主要關注分類問題。
分類樹是與如k近鄰等原型法不同的一種方法。原型法的基本思想是對空間進行劃分,並找出一些具有代表性的中心。決策樹也不同於線性方法,如線性的判別分析、二次判別分析和logistic迴歸。這些方法是用超平面作為分類邊界。
分類樹是對空間進行層級的劃分。從整個空間開始遞迴地劃分成小區域。最後,被劃分出來的每個小區域都被賦予了一個類標籤。
2,介紹(CART)演算法
一個醫療案例:
決策樹的一個巨大的優點就是構造的分類器具有高度的可解釋性。這對於醫生來說是一個非常吸引人的特點。
在這個例子中,病人被分為兩類:高風險vs低風險。基於最初的24小時的資料,預測為高風險的病人可能無法存活超過30天。每個病人第一個24小時內都有19個測量指標,如血壓、年齡等。
下圖是一個樹形分類器,規則及解釋如圖所示:

這個分類器只關注了三個測量指標。對於一些病人,用一個指標就可以確定最終結果。所以,分類樹對醫生來說檢驗過程很簡單。
10.1 構建樹
我們要牢記:樹代表了對空間的遞迴地劃分。因此每一個感興趣的節點都對應原空間的一個子區域中的節點。兩個子節點佔據了不同的區域,如果合併兩個子節點,則合併後的區域也與父節點對應的區域相同。最後,每個葉節點都會被賦予一個分類。
樹形分類器的構造就是從X空間自身開始,不斷的劃分出越來越小的子空間。
定義:
我們用X定義特徵空間。X是多維歐式空間。然而有些時候,一些變數可能是分類變數,如性別。CART演算法的優點,就是可以用統一的方法處理數值型變數和分型別變數。而對於大多數其他分類方法來說並不具備這種優勢,如LDA。
- 假設輸入變量表示為:X∈X,包含p個特徵,
X1,X2,...,Xp - 用 t 表示節點,
tL 代表左子節點,tR 代表右子節點。 - 樹種所有節點的集合用 T 表示,所有葉節點的結合用 T̃
- 一次劃分用s表示,劃分的集合用S表示
根據下圖看一下,空間樹如何被劃分出來的:
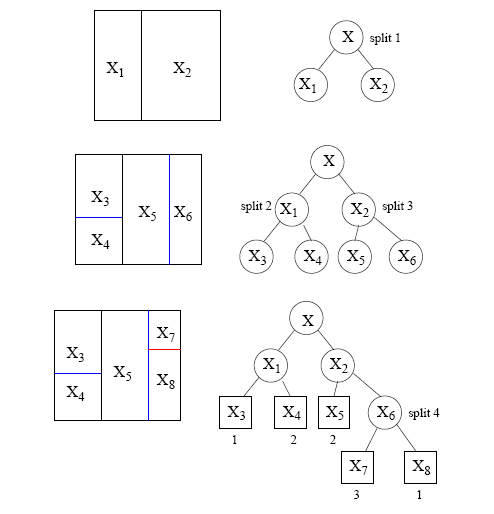
三個基本要素
- 空間劃分的選擇,如在哪個節點上進行劃分,以及如何劃分?
- 當我們知道如何劃分生成樹的時候,又在何時可以確定一個終結點並停止進行劃分呢?
- 我們必須對每一個終結點賦予一個類標籤。那麼我們又何如賦予這些標籤呢?
1) 標準問題集- 劃分空間節點的準備
如之前所述,假定輸入向量 X=(X1,X2,⋯,Xp),既包含了分類變數也包含了定序變數特徵。CART演算法使事情變得簡單,因為每次劃分僅從一個變數入手。
如果我們有定序變數,如Xj — 那麼此處拆分問題可以轉化為比較Xj是否小於或等於一個閾值。因此,對於任意定序變數Xj,問題集Q的統一形式如下:
{Is Xj ≤ c ?},對於任何實數 c.
當然也有其他形式的劃分方法,比如,你可能想問,是否可以形如 X1+X2≤ c ? 這種情況下,劃分線不是平行於座標軸的(劃分線是斜率為-1,截距為c的線)。因此,這裡我們可以限制問題格式。每個問題均是取一個特徵 Xj 與閾值進行比較。
因為訓練集是有限的,因此只有有限多個閾值 c 對資料點進行劃分。
如果 Xj 是分類變數, 取值於{1, 2, … , M}, 那麼問題集Q 形如:
{Is Xj ∈ A ?},其中,A 是 {1, 2, … , M} 的子集.
所有p個特徵向量的劃分或問題構成了劃分的候選集合。
綜上,第一步就是先確定所有的候選問題。以便在下一步構建樹的時候,可以挑選在哪個節點上用哪個問題來進行劃分。
2) 確定劃分優度-’goodness of split’
當我們選擇問題進行劃分的時候,我們需要測量該問題下每一個劃分的’goodness of split’。這既取決於問題的選擇也取決於被劃分的節點。這個’goodness of split’ 是用“不純度”公式來測量的。
直覺地,當我們劃分節點時候,我們想要使得每個葉節點的區域都更“純”。換句話說,就是使這個劃分區域中的點都儘可能多的屬於同一個分類,即,該類佔有絕對主導地位。
來看下面的例子。圖中有兩個分類,x 和 o 。劃分的時候我們先檢查水平變數是否高於或低於一個閾值,如下圖

劃分被藍線標註。切記我們候選劃分的特性,劃分區總是被平行於座標軸的線所分割的。就上面的例子說,我們會覺得是個好的劃分,因為左手邊比較“純”了,基本都是 x 類,只有2列屬於 o 。右手邊同樣比“較純”。
直覺上選擇每個劃分節點的時候我們都想生成“純”的節點。如果我們再往更深一層次探索,我們會再多兩個劃分,如下圖

現在,如您所見,坐上區域葉節點僅包含 x 類。因此純度是100%的,沒有其他的分類出現。一旦我們達到這個水平,我們就不必再進行更近一步的劃分了。因為所有的劃分都是100%的純度。在此訓練集上,更多的劃分不再有更好的結果,儘管可能在測試集上會有所不同。
10.2 不純度的測量公式
不純度公式是用來測量包含不同分類點劃分區域的“純的程度”的。假設有K個不同的類別,那麼就會有
不純度的測量公式可以被定義成不同的形式,但是最基本的要要素是要滿足下面的三個要素。
定義:一個不純度的測量公式 Φ ,對於所有K 元組(
- Φ 值對於均勻分佈將達到最大值,即當所有
Pj 都相等時; - Φ 值將達到最小值,當點屬於某分類的概率是1,屬於其他分類概率為0;
- Φ 對於(
P1,...,Pk )是對稱的,置換Pj ,Φ 值不變;
定義:給定一個不純度的測量公式 Φ ,對於 t 節點不純度為 i(t) :
i(t)=Φ( p(1|t),p(2|t),…,p(k|t) )
式中,p(j|t) 是給定節點t中的一個點為 j 類的後驗概率估計。一旦我們知道了i(t),我們就可以定義對於節點 t ,劃分優度,定義為 Φ(s, t):
式中,可以看出 Δi(s, t) 是節點 t 的不純度,與左右子節點不純度加權求和之間的差值。權值
再來看一下下圖例子:

假設紫色陰影的左側區域要被繼續劃分,上半部分(x)是左側子節點,下半部分(o)是右側子節點。那麼此時左側子節點的比例為8/10,右側為2/10.
分類樹演算法會遍歷所有候選劃分集,找到最大△i(s,t)對應的最優劃分。
接下來我們定義 I(t) = i(t) p(t), 即,節點t 的加權不純度值。 p(t)與上述中左右子節點的權值定義一致。當然如果節點t 是總體的第一個劃分得到的子節點,那麼權值是總體的樣本中被被劃分到節點t 的樣本的佔比。
那麼對於一個樹T,不純度的總測量定義為 , I(T):
這是所有葉節點的加權求和,注意不是所有節點,是葉節點集合T’。
且對於任何節點有:
進而,我們定義一個父節點與兩個子節點之間的不純度之差:(我們得到了一個遞迴公式)
=
=
=
最後,我們揭開了不純度度量的神祕面紗…
要知道,不論我們如何定義不純度公式,我們在分類樹種使用它的過程是保持一致的。所以,唯一不同的就是具體的不純度度量公式。
下面介紹可能會經常使用的不純度度量公式:
熵
相關推薦
第10章-基於樹的方法(1)-生成樹
一,本章簡介 1,本章主要學習目標 理解決策樹的基本概念 理解構成決策樹的三個基本元素 理解’不純度’及其他度量公式的定義 知道如何估計每個樹節點的各個所屬分類的後驗概率 理解基於樹的分類方法的優點 理解訓練誤差(或稱再代入誤差) 和 代價複雜
第10章-基於樹的方法(3)-樹的改進-整合方法
參考: https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf rob.schapire.net/papers/explaining-adaboost.pdf *https://statweb.stanford.edu/~
第10章-基於樹的方法(2)-樹的剪枝
###10.8 通過剪枝得到最優規模的樹 之前我們討論的都是如何生成樹,接下來我們要講解的是如何進行剪枝。 我們令一個樹 T 的誤分類誤差的期望為 R
《機器學習實戰》第三章:決策樹(1)基本概念
有半個月沒來了。 最近一段時間...大多在忙專案組的事(其實就是改一改現有程式碼的bug,不過也挺費勁的,畢竟程式碼不是自己寫的)。另外就是自己租了幾臺美帝的vps,搭了$-$的伺服器 ,效果還不錯。自己搭的話就不用去買別人的服務了,不過租vps畢竟還是要成本的,光用來番茄
python編程快速上手之第10章實踐項目參考答案(12.13.1)
true style span tip 12.1 user python input multi #! python3 # multiplicationTable.py import openpyxl,os from openpyxl.styles import Font
第10章 文檔對象模型DOM 10.1 Node節點類型
not 應該 特定 新增 ssi 方式 new ext prot DOM是針對 HTML 和 XML 文檔的一個 API(應用程序編程接口) 。DOM描繪了一個層次化的節點樹,允許開發人員添加、移除和修改頁面的某一部分。DOM 脫胎於Netscape 及微軟公司創始的 DH
Django第10章: 權限管理(遞歸菜單樹)
dex 通過 ava nta gis IT emp 自定義 無需 權限四表(重點) 用戶登錄 進入admin後臺填充數據; 前端利用form表單登錄; 用戶輸入登錄信息後, 若後端認證通過,則緩存當前用戶的所有權限信息 # views.py=============
第10章——模板方法模式
1、既然用了繼承,並且肯定這個繼承有意義,就應該要成為子類的模板,所有超昂福的程式碼都應該要上升到父類去,而不是讓每個子類都去重複。 2、當我們要完成在某一細節層次一直的一個過程或者一系列步驟,但其個別步驟在更詳細的層次上的實現可能不同時,我們通常考慮用模板方法模式來處理。 3、
組合語言(第3版) 第10章相關內容及實驗10和課程設計1
第十章 CALL和RET指令 文章目錄 第十章 CALL和RET指令 章節內容 概述 ret/retf call ret和call配合
第1章 統計與資料 第2章 資料的描述方法
統計的應用可以分為描述統計(即報表)和推斷統計(即預測建模) 樣本來源於總體,是試驗的產物,變數是每個試驗單元的特徵或屬性 推斷統計的五要素:總體、變數、樣本、推斷、可靠性 過程是講輸入轉化為輸出的一系列行動或操作,過程產生的一系列輸出被稱為樣本 所有資料可以分為定量資
第10章 網路安全(1)_對稱加密和非對稱加密
1 網路安全概述 1.1 計算機網路面臨的安全威協 (1)截獲:攻擊者從網路上竊聽他人的通訊內容,通常把這類攻擊稱為“截獲”。在被動攻擊中,攻擊者只是觀察和分析某一個協議資料單元(PDU)而不干擾資訊流。 (2)篡改:攻擊者篡改網路上傳遞的報文。這裡包括徹底中斷傳遞的報文,甚至把完
演算法班筆記 第五章 二叉樹和基於樹的DFS
第五章 二叉樹和基於樹的DFS 在這一章節的學習中,我們將要學習一個數據結構——二叉樹(Binary Tree),和基於二叉樹上的搜尋演算法。 在二叉樹的搜尋中,我們主要使用了分治法(Divide Conquer)來解決大部分的問題。之所以大部分二叉樹的問題可以使用分治法
機器學習實戰---讀書筆記: 第10章 利用K均值聚類演算法對未標註資料分組---1
#!/usr/bin/env python # encoding: utf-8 import os from matplotlib import pyplot as plt from numpy import * ''' 讀書筆記之--<<機器學習實戰>>--第10章_
【機器學習實戰—第4章:基於概率論的分類方法:樸素貝葉斯】程式碼報錯(python3)
1、報錯:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xae in position 199: illegal multibyte sequence 原因:這是檔案編碼的問題,檔案中有非法的多位元組字元。 解決辦法:開啟Ch04\
第七章:基於九鼎X210開發板移植2014.10版U-boot之初始化時鐘模組
重新燒錄,啟動,發現可以正常執行,然後卡死在DRAM之後,還打印出了一個O,這個O看起來挺熟悉的,開機時候列印的那個O?一下子就想到,我們雖然自己移植的那個重定位程式碼(拷貝BL2到記憶體中),但原版
第八章:基於九鼎X210開發板移植2014.10版U-boot之初始化網絡卡
接下來就要開始處理網絡卡相關的了,這樣我們才能掛載網路檔案系統,使用tftp伺服器之類的,但是很不幸,2014.10版本的uboot裡面沒有支援我們的開發板上的網絡卡。所以接下來要手動移植網絡卡相關
第九章:基於九鼎X210開發板移植2014.10版U-boot之啟動核心
接下來要啟動核心了。首先要先將機器碼設定成我們開發板的機器碼,將/board/Samsung/x210目錄下的x210.c中的board_init函式中的bi_arch_number傳入MACH_TYPE_SMDKV210,傳入正確的機器碼才能啟動核心。 但事實上,無論
第四章:基於九鼎X210開發板移植2014.10版U-boot之使用sd卡啟動
start.S是所有armv7架構的cpu共用的,在start.S中的應該都不需要太多的改動。分析到下面,對uboot有了解的朋友,應該都知道這幾個函式主要幹嘛的 cpu_init_cp15:對cp1
程式是怎樣跑起來的-第10章 通過組合語言瞭解程式的實際構成
第10章通過組合語言瞭解程式的實際構成 熱身問題 1.原生代碼指令中,表示其功能的英文縮寫稱為什麼? 助記符、組合語言是通過利用助記符來記述程式的。 2.組合語言的原始碼轉換成原生代碼的方式稱為什麼? 彙編、使用匯編器這個工具來進行彙編。 3.原生代碼轉換
python編程快速上手之第10章實踐項目參考答案(11.11.2)
答案 nic .com final timeout pre image 保存圖片 iframe #!/usr/bin/env python # -*- coding:utf-8 -*- import os import re import urllib import