
B+樹優缺點
優點
- 單次請求涉及的磁碟IO次數少(出度d大,且非葉子節點不包含表資料,樹的高度小);
- 查詢效率穩定(任何關鍵字的查詢必須走從根結點到葉子結點,查詢路徑長度相同);
- 遍歷效率高(從符合條件的某個葉子節點開始遍歷即可);
在B+樹中, 由於底層的各個葉子節點都通過指標組織成一個雙向連結串列, 結構如下圖所示。 因此,只需要從跟節點到葉子節點定位到第一個滿足條件的Key, 然後不斷在葉子節點迭代next指標即可實現遍歷,此時相當於順序IO。相反,如果通過每次從根節點查詢進行遍歷,相當於進行隨機IO,效率低下,如下圖所示:
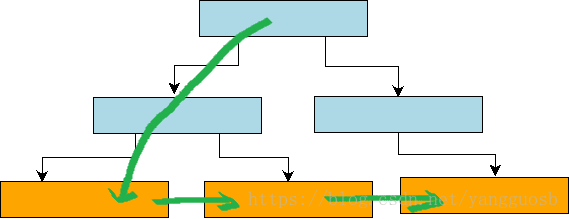
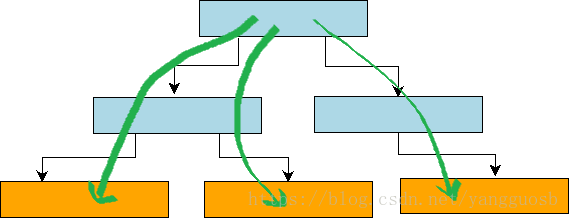
缺點
B+樹最大的效能問題在於會產生大量的隨機IO,主要存在以下兩種情況:
- 主鍵不是有序遞增的,導致每次插入資料產生大量的資料遷移和空間碎片;
- 即使主鍵是有序遞增的,大量寫請求的分佈仍是隨機的;
參考:
相關推薦
B+樹優缺點
優點 單次請求涉及的磁碟IO次數少(出度d大,且非葉子節點不包含表資料,樹的高度小); 查詢效率穩定(任何關鍵字的查詢必須走從根結點到葉子結點,查詢路徑長度相同); 遍歷效率高(從符合條件的某個葉子
hash相對B樹優缺點
個人總結,非標準,熱切盼望各位看官補充或拍磚。 hash 相對 B-Tree 的優點: 1、快 不論雜湊表中有多少資料,插入和刪除只需要接近0(1)的時間。實際上,這隻需要幾條機器指令。B樹的操作通常需要O(logN)的時間級。雜湊表不僅速度快,程式設計實現也相對容易。
B-樹,B+樹與B*樹的優缺點比較
首先注意:B樹就是B-樹,"-"是個連字元號,不是減號。 B-樹是一種平衡的多路查詢(又稱排序)樹,在檔案系統中有所應用。主要用作檔案的索引。其中的B就表示平衡(Balance) B+樹有一個最大的好處,方便掃庫,B樹必須用中序遍歷的方法按序掃庫,而B+樹直接從葉子結點挨個掃一遍就完了。 B+樹支援ran
二叉查詢樹,紅黑樹,AVL樹,B~/B+樹(B-tree),伸展樹——優缺點及比較
二叉查詢樹(Binary Search Tree) 很顯然,二叉查詢樹的發現完全是因為靜態查詢結構在動態插入,刪除結點所表現出來的無能為力(需要付出極大的代價)。 BST 的操作代價分析: (1) 查詢代價: 任何一個數據的查詢過程都需要從根結點出發,沿
資料庫B樹索引和hash索引的優缺點比較
雜湊值衝突多時,不適用 雜湊索引的是用欄位的值,計算出一個範圍內的hash值,通過hash值去對映得到資料的位置(行號還是實際資料的位置,還沒有區分)已經指向下一個資料的指標,不會儲存欄位的值,所以使用hash索引不能直接得到資料,只能得到一個位置資訊;hash函式計算hash值和對映的一些演算法,導致
數據結構~Sqlserver索引使用的B樹
vsa pvs lol kff avs elk bin nmf eth1 B樹相關概念 在B-樹中查找給定關鍵字的方法是,首先把根結點取來,在根結點所包含的關鍵字K1,…,Kn查找給定的關鍵字(可用順序查找或二分查找法),若找到等於給定值的關鍵字,則查找成功;否則,一定可以
【經典數據結構】B樹與B+樹(轉)
linux 每分鐘 www 數據 csapp png 感知 轉動 繼續 本文轉載自:http://www.cnblogs.com/yangecnu/p/Introduce-B-Tree-and-B-Plus-Tree.html 維基百科對B樹的定義為“在計算機科學中,B
B樹與B+樹
觸發 minute str 9.png 扇區 sram node 信息 title 轉自:http://www.cnblogs.com/yangecnu/p/Introduce-B-Tree-and-B-Plus-Tree.html 前面講解了平衡查找樹中的2-3樹以及
B-樹和B+樹的應用:數據搜索和數據庫索引
深度 出現 通過 都在 def 查找樹 兩個指針 屬性排序 n+1 B-樹 1 .B-樹定義 B-樹是一種平衡的多路查找樹,它在文件系統中很有用。 定義:一棵m 階的B-樹,或者為空樹,或為滿足下列特性的m 叉樹:⑴樹中每個結點至多有m 棵子樹;⑵若根結點不是葉子結點,
B樹、B+樹、紅黑樹、AVL樹
付出 而不是 通過 找到 磁盤讀寫 三次 復雜度 節點 span 定義及概念 B樹 二叉樹的深度較大,在查找時會造成I/O讀寫頻繁,查詢效率低下,所以引入了多叉樹的結構,也就是B樹。階為M的B樹具有以下性質: 1、根節點在不為葉子節點的情況下兒子數為 2 ~ M2、除根結
多路查找樹B樹
i+1 btree ecp key 個數 urn i++ can 輸入 #include "stdio.h" #include "stdlib.h" #include "io.h" #include "math.h" #include "time.h" #defin
B樹、B-樹、B+樹、B*樹介紹,和B+樹更適合做文件索引的原因
二叉搜索樹 margin 鏈表 重建 影響 不足 原來 之間 復制 今天看數據庫,書中提到:由於索引是采用 B 樹結構存儲的,所以對應的索引項並不會被刪除,經過一段時間的增刪改操作後,數據庫中就會出現大量的存儲碎片, 這和磁盤碎片、內存碎片產生原理是類似的,這些存儲碎片不僅
索引(B*樹索引/位圖索引)
功能 實施 ins 情況 不同 如果 使用 大表 pda 索引功能: 1.強制實施主鍵約束和唯一約束 2.提高性能 (1)大表,用索引比較快,小表,全表掃描,比較快。 (2)排序,如果select語句包括order by、group by、union或其它一些關鍵字,則
B樹和B+樹的總結
href 直接插入 也有 新的 img 結束 提高 通過 我們 https://www.cnblogs.com/George1994/p/7008732.html B樹和B+樹的總結 B樹 為什麽要B樹 磁盤中有兩個機械運動的部分,分別是盤片旋轉和磁臂
B數,B+樹
int 不能 一個 數據 內存 過大 深度 平衡 OS 0 為什麽會有多叉樹 當在程序中存儲數據的時候,可以使用二叉搜索樹。 當輸入的過於均勻的時候可能生成深度過大的二叉搜索樹,最壞的情況是,輸入節點的key按照大小排序,此時生成的二叉搜索樹就是一個鏈表了。 因此,為了避免
關系型數據庫索引是什麽,目的,原理及B,B+樹區別
b樹 內部 葉子節點 一個 記錄 tor .net 移動 tail 數據庫索引到底是什麽,是怎樣工作的? - CSDN博客http://blog.csdn.net/weiliangliang111/article/details/51333169MySQL索引原理及慢查詢優
從B樹、B+樹、B*樹談到R 樹
pid class OS clas track popu gpo AI detail 地址:https://blog.csdn.net/v_JULY_v/article/details/6530142/ 從B樹、B+樹、B*樹談到R 樹
B樹和B+樹的插入、刪除圖文詳解
留言 使用 結構 調整 -i 詳細 樹的高度 目的 根據 簡介:本文主要介紹了B樹和B+樹的插入、刪除操作。寫這篇博客的目的是發現沒有相關博客以舉例的方式詳細介紹B+樹的相關操作,由於自身對某些細節也感到很迷惑,通過查閱相關資料,對B+樹的操作有所頓悟,寫下這篇博客以做記錄
B樹和B+樹
樹的高度 需要 比較 詳細 細節 子類 是我 導致 相關 B樹和B+樹 簡介:本文主要介紹了B樹和B+樹的插入、刪除操作。寫這篇博客的目的是發現沒有相關博客以舉例的方式詳細介紹B+樹的相關操作,由於自身對某些細節也感到很迷惑,通過查閱相關資料,對B+樹的操作有所頓悟,寫下這
B樹、B-樹、B+樹、B*樹
屬於 基礎上 所有 二叉樹 優點 關鍵字 樹結構 .net 一次 B樹 即二叉搜索樹: 1.所有非葉子結點至多擁有兩個兒子(Left和Right); 2.所有結點存儲一個關鍵字; 3.非葉子結點的左指針指向小於