
14.效能優化答疑二
一、使用perf 工具,看到的是十六進位制地址而不是函式名。
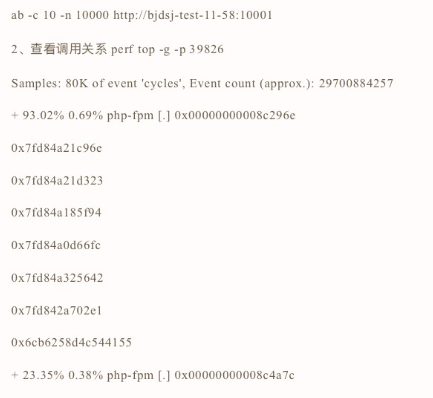
檢視perf最後歐,就會看到警告資訊:
Failed to open /opt/bitnami/php/lib/php/extensions/opcache.so, continuing without symbols
這說明,perf 找不到待分析程序依賴的庫。當然,實際上這個案例中有很多依賴庫都找不到,只不過,perf 工具本身只在最後一行顯示警告資訊,所以你只能看到這一條警告。
這個問題,其實也是在分析 Docker 容器應用時,我們經常碰到的一個問題,因為容器應用依賴的庫都在映象裡面。
針對這種情況,我總結了下面四個解決方法。
第一個方法,在容器外面構建相同路徑的依賴庫。這種方法從原理上可行,但是我並不推薦,一方面是因為找出這些依賴庫比較麻煩,更重要的是,構建這些路徑,會汙染容器主機的環境。
第二個方法,在容器內部執行 perf。不過,這需要容器執行在特權模式下,但實際的應用程式往往只以普通容器的方式執行。所以,容器內部一般沒有許可權執行 perf 分析。
比方說,如果你在普通容器內部執行 perf record ,你將會看到下面這個錯誤提示:
$ perf_4.9 record -a -g perf_event_open(..., PERF_FLAG_FD_CLOEXEC) failed with unexpected error1 (Operation not permitted) perf_event_open(..., 0) failed unexpectedly with error 1 (Operation not permitted)
當然,其實你還可以通過配置 /proc/sys/kernel/perf_event_paranoid (比如改成 -1),來允許非特權使用者執行 perf 事件分析。
不過還是那句話,為了安全起見,這種方法我也不推薦。
第三個方法,指定符號路徑為容器檔案系統的路徑。比如對於第 05 講的應用,你可以執行下面這個命令:
$ mkdir /tmp/foo $ PID=$(docker inspect --format {{.State.Pid}} phpfpm) $ bindfs/proc/$PID/root /tmp/foo $ perf report --symfs /tmp/foo
# 使用完成後不要忘記解除繫結
$ umount /tmp/foo/
不過這裡要注意,bindfs 這個工具需要你額外安裝。bindfs 的基本功能是實現目錄繫結(類似於 mount --bind),這裡需要你安裝的是 1.13.10 版本(這也是它的最新發布版)。
如果你安裝的是舊版本,你可以到 GitHub上面下載原始碼,然後編譯安裝。
第四個方法,在容器外面把分析紀錄儲存下來,再去容器裡檢視結果。這樣,庫和符號的路徑也就都對了。
比如,你可以這麼做。先執行 perf record -g -p < pid>,執行一會兒(比如 15 秒)後,按 Ctrl+C 停止。
然後,把生成的 perf.data 檔案,拷貝到容器裡面來分析:
$ docker cp perf.data phpfpm:/tmp
$ docker exec -i -t phpfpm bash
接下來,在容器的 bash 中繼續執行下面的命令,安裝 perf 並使用 perf report 檢視報告:
$ cd /tmp/ $ apt-get update && apt-get install -y linux-tools linux-perf procps $ perf_4.9 report
不過,這裡也有兩點需要你注意。
首先是 perf 工具的版本問題。在最後一步中,我們執行的工具是容器內部安裝的版本 perf_4.9,而不是普通的 perf 命令。這是因為, perf 命令實際上是一個軟連線,會跟核心的版本進行匹配,但映象裡安裝的 perf 版本跟虛擬機器的核心版本有可能並不一致。
另外,php-fpm 映象是基於 Debian 系統的,所以安裝 perf 工具的命令,跟 Ubuntu 也並不完全一樣。比如, Ubuntu 上的安裝方法是下面這樣:
$ apt-get install -y linux-tools-common linux-tools-generic linux-tools-$(uname -r))
而在 php-fpm 容器裡,你應該執行下面的命令來安裝 perf:
$ apt-get install -y linux-perf
當你按照前面這幾種方法操作後,你就可以在容器內部看到 sqrt 的堆疊:
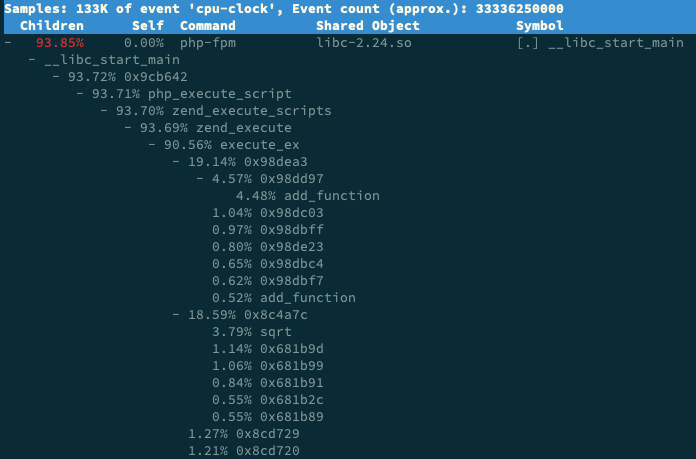
二、使用perf工具分析Java


兩個問題,其實是上一個 perf 問題的延伸。 像是 Java 這種通過 JVM 來執行的應用程式,執行堆疊用的都是 JVM 內建的函式和堆疊管理。所以,從系統層面你只能看到 JVM 的函式堆疊,而不能直接得到 Java 應用程式的堆疊。
perf_events 實際上已經支援了 JIT,但還需要一個 /tmp/perf-PID.map 檔案,來進行符號翻譯。當然,開源專案 perf-map-agent 可以幫你生成這個符號表。
此外,為了生成全部呼叫棧,你還需要開啟 JDK 的選項 -XX:+PreserveFramePointer。因為這裡涉及到大量的 Java 知識,我就不再詳細展開了。如果你的應用剛好基於 Java ,那麼你可以參考 NETFLIX 的技術部落格 Java in Flames (連結為 https://medium.com/netflix-techblog/java-in-flames-e763b3d32166),來檢視詳細的使用步驟。
說到這裡,我也想強調一個問題,那就是學習效能優化時,不要一開始就把自己限定在具體的某個程式語言或者效能工具中,糾結於語言或工具的細節出不來。
掌握整體的分析思路,才是我們首先要做的。因為,效能優化的原理和思路,在任何程式語言中都是相通的。
三、為什麼 perf 的報告中,很多符號都不顯示呼叫棧
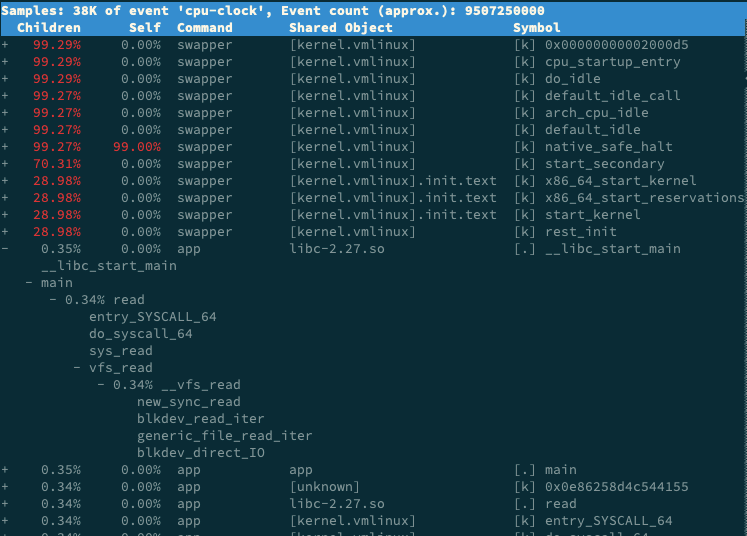
perf record -g 命令手機資訊,收集多次,每次都是command列為swapper的左側有加號,而app或其他的沒有加號,在symbol列看到sys_read,new_sync_read,blkdev_read_iter等資訊。(Ubunt系統)。
perf report是視覺化展示perf.data工具,在執行時,看到以下介面:
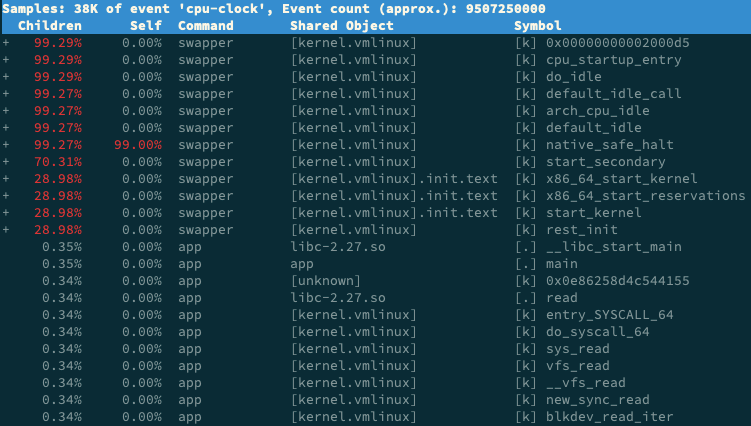
清楚看到只有swapper呼叫棧,其他所有符號都不能看到堆疊。發現效能工具無法理解時檢視手冊,man perf-report,找到 -g 說明: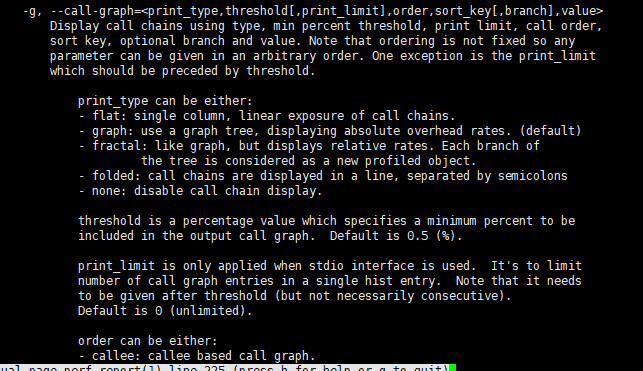
通過這個說明可以看到,-g 選項等同於 --call-graph,它的引數是後面那些被逗號隔開的選項,意思分別是輸出型別、最小閾值、輸出限制、排序方法、排序關鍵詞、分支以及值的型別。
我們可以看到,這裡預設的引數是 graph,0.5,caller,function,percent,具體含義文件中都有詳細講解,這裡我就不再重複了。
現在再回過頭來看我們的問題,堆疊顯示不全,相關的引數當然就是最小閾值 threshold。通過手冊中對 threshold 的說明,我們知道,當一個事件發生比例高於這個閾值時,它的呼叫棧才會顯示出來。
threshold 的預設值為 0.5%,也就是說,事件比例超過 0.5% 時,呼叫棧才能被顯示。再觀察我們案例應用 app 的事件比例,只有 0.34%,低於 0.5%,所以看不到 app 的呼叫棧就很正常了。
這種情況下,你只需要給 perf report 設定一個小於 0.34% 的閾值,就可以顯示我們想看到的呼叫圖了。比如執行下面的命令:
$ perf report -g graph,0.3
你就可以得到下面這個新的輸出介面,展開 app 後,就可以看到它的呼叫棧了。
四、perf report 報告。
在perf展開的分析詳情中,有children和self都有90%多的swapper程序,進而去圍繞這個程序展開,忽略只佔用0.6%的app程序?
看到swapper,先想到的是SWAP分割槽,swapper跟SWAP沒有任何關係,它只是系統初始化時 的init程序,之後就成了一個最低優先順序空閒任務。當CPU上沒有任何任務執行時,就會執行swapper,被稱為“空閒任務”。
在perf report介面中,展開它的呼叫棧,看到swapper時鐘事件都消耗費在了do_idle上,也就是在執行空閒任務:
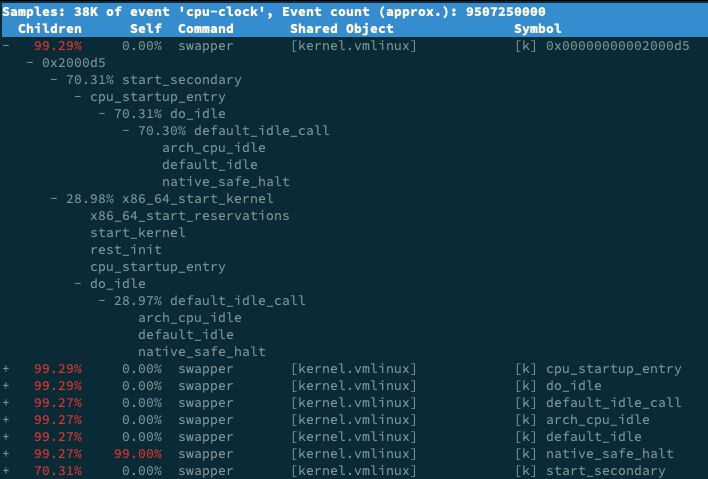
所以,分析圖,直接忽略前面99%的符號,轉而分析後面只有0.3%的app。其實在多工系統中,次數的事件,不一定就是效能瓶頸。
所以在只觀察一個大數值,並不能說明什麼問題,具體有沒有瓶頸還要觀測多個方面的多個指標,交叉驗證。
另外,關於Children和Self的含義,手冊有詳細說明:
- Self 是最後一列的符號(可以理解為函式)本身所佔比例;
- Children 是這個符號呼叫的其他符號(理解為子函式,包括直接呼叫和間接呼叫)佔用的比列之和。
perf,需要在核心中跟蹤核心棧的各種事件,不可避免帶來一定的效能損失,雖然對大部分應用沒有太大影響,但特定某些應用(像對時鐘週期特別敏感的應用),可能就是災難。
在使用效能工具時,要考慮工具本身對系統的影響,就要了解工具的原理:
- perf 這種動態追蹤工具,會帶來效能損失。
- vmstat、pidstat這些直接讀取proc 檔案的系統來獲取指標的工具,不會帶來效能損失。
五、效能優化書籍和參考資料推薦。
Brendan Gregg 是一位當之無愧的效能優化大師,他的效能工具圖譜很多文章中都會看到:Linux效能篇一。
Brendan Gregg 的效能優化書籍《Systems Performance:Enterprise and the Cloud》。中文版的名字是:《效能之巔:洞悉系統、企業與雲端計算》。雖然在2013年出版,但依然是經典,分析思路雞效能工具依然適合現在。
Brendan Gregg 的個人網站:http://www.brendangregg.com/ ,特別是 Linux Performance 這一頁包含很多Linux效能優化資料,比如:
- Linux效能工具圖譜
- 效能分析參考資料
- 效能優化演講視訊
但很多內容涉及到核心知識,對於初學者不太友好,要循序漸進一遍遍閱讀。