
資料庫索引以及索引的實現(B+樹介紹,和B樹,區別)
索引
索引是提高資料庫表訪問速度的方法。
分為聚集索引和非聚集索引。
聚集索引:對正文內容按照一定規則排序的目錄。
非聚集索引:目錄按照一定的順序排列,正文按照另一種順序排列,目錄與正文之間保持一種對映關係。
把資料庫索引比作字典查詢索引,
聚集索引就是按照拼音查詢,拼音欄中字的順序就是查詢得到的字的順序。
非聚集索引就像按照偏旁部首查詢,同是單人旁查到的字所在的頁碼可能是雜亂的,沒有順序的。
儲存結構
記憶體中儲存的資料是有限的,當需要在磁碟中進行查詢時就涉及到了磁碟的 I/O 操作。
當磁碟驅動器執行讀/寫功能時。碟片裝在一個主軸上,並繞主軸高速旋轉,當磁軌在讀/寫頭(又叫磁頭) 下通過時,就可以進行資料的讀 / 寫了。磁碟讀取資料是以盤塊(block)為基本單位的。位於同一盤塊中的所有資料都能被一次性全部讀取出來。而磁碟IO代價主要花費在查詢時間Ts上。因此我們應該儘量將相關資訊存放在同一盤塊,同一磁軌中。或者至少放在同一柱面或相鄰柱面上,以求在讀/寫資訊時儘量減少磁頭來回移動的次數,避免過多的查詢時間。
索引查詢時產生磁碟I/O消耗,相對於記憶體存取,I/O存取的消耗要高几個數量級,所以評價一個數據結構作為索引的優劣最重要的指標就是在查詢過程中磁碟I/O操作次數的時間複雜度。樹高度越小,I/O次數越少。
平衡樹的高度過深進行多次磁碟IO,導致查詢效率低下,而B樹和B+樹樹中每個結點最多含有m個孩子,所以相對平衡樹B樹和B+樹的高度比較低。
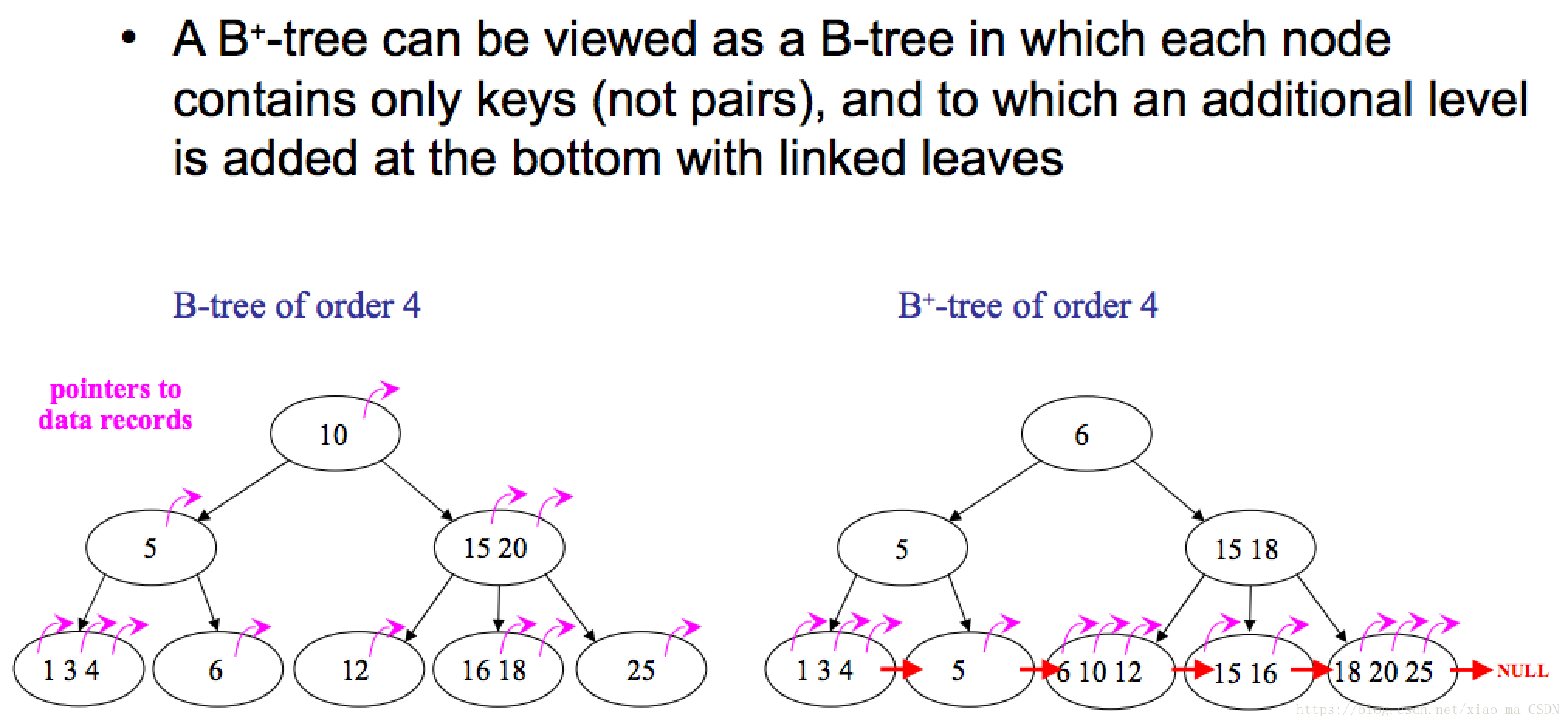
B樹
每個節點都儲存key和data,所有節點組成這棵樹,並且葉子節點指標為null。
B+樹
只有葉子節點儲存data,葉子節點包含了這棵樹的所有鍵值,葉子節點不儲存指標。所有非終端節點看成是索引,節點中僅含有其子樹根節點最大(或最小)的關鍵字,不包含查詢的有效資訊。B+樹中所有葉子節點都是通過指標連線在一起。
總結:為什麼使用B+樹?
1.檔案很大,不可能全部儲存在記憶體中,故要儲存到磁碟上
2.索引的結構組織要儘量減少查詢過程中磁碟I/O的存取次數(為什麼使用B-/+Tree,還跟磁碟存取原理有關,具體看下邊分析)
3. 區域性性原理與磁碟預讀,預讀的長度一般為頁(page)的整倍數,(在許多作業系統中,頁得大小通常為4k)
4. 資料庫系統巧妙利用了磁碟預讀原理,將一個節點的大小設為等於一個頁,這樣 每個節點只需要一次I/O 就可以完全載入,(由於節點中有兩個陣列,所以地址連續)。而紅黑樹這種結構, h 明顯要深的多。由於邏輯上很近的節點(父子)物理上可能很遠,無法利用區域性性。
為什麼B+樹比B樹更適合做索引?
1.B+樹磁碟讀寫代價更低
B+的內部結點並沒有指向關鍵字具體資訊的指標,即內部節點不儲存資料。因此其內部結點相對B 樹更小。如果把所有同一內部結點的關鍵字存放在同一盤塊中,那麼盤塊所能容納的關鍵字數量也越多。一次性讀入記憶體中的需要查詢的關鍵字也就越多。相對來說IO讀寫次數也就降低了。
2.B+-tree的查詢效率更加穩定
由於非終結點並不是最終指向檔案內容的結點,而只是葉子結點中關鍵字的索引。所以任何關鍵字的查詢必須走一條從根結點到葉子結點的路。所有關鍵字查詢的路徑長度相同,導致每一個數據的查詢效率相當。
在MySQL中,最常用的兩個儲存引擎是MyISAM和InnoDB,它們對索引的實現方式是不同的。
MyISAM data存的是資料地址。索引是索引,資料是資料。
InnoDB data存的是資料本身。索引也是資料。