
python3基礎:操作xml
XML 指的是可擴充套件標記語言(eXtensible Markup Language),和json類似也是用於儲存和傳輸資料,還可以用作配置檔案。類似於HTML超文字標記語言,但是HTML所有的標籤都是預定義的,而xml的標籤可以隨便定義。
XML元素
指從開始標籤到結束標籤的部分(均包括開始和結束)
一個元素可以包括:
- 其它元素
<aa>
<bb></bb>
</aa>
- 屬性
<a id=’132’></a>
- 文字
<a >abc</a>
- 混合以上所有
XML語法規則
- 所有的元素都必須有開始標籤和結束標籤,省略結束標籤是非法的。如:
<root>根元素</root>
- 大小寫敏感,以下是兩個不同的標籤
<Note>this is a test1</Note>
<note>this is a test2</note>
- xml文件必須有根元素
<note> <b>this is a test2</b> <name>joy</name> </note>
- XML必須正確巢狀,父元素必須完全包住子元素。如:
<note><b>this is a test2</b></note>
- XML屬性值必須加引號,元素的屬性值都是一個鍵值對形式。如:
<book category=" Python"></book>
注意:元素book的category屬性值python必須用引號括起來,單引號雙引號都可以。如果屬性值中包含單引號那麼用雙引號括起來,如果屬性值包含單引號那麼外面用雙引號括起來。
XML命名規則
名稱可以包含字母、數字以及其他字元
名稱不能以數字或標點符號開頭
名稱不能以字母xml或XML開始
名稱不能包含空格
可以使用任何名稱,沒有保留字
名稱應該具有描述性,簡短和簡單,可以同時使用下劃線。
避免“-”、“.”、“:”等字元
Xml的註釋格式
<!--註釋內容-->
Python對XML的解析
常見的XML程式設計介面有DOM和SAX,這兩種介面處理XML檔案的方式不同,使用場合也不同。python有三種方法解析XML:SAX,DOM和ElementTree
- DOM(Document Object Model)
DOM的解析器在解析一個XML文件時,一次性讀取整個文件,把文件中所有元素儲存在記憶體中的一個樹結構裡,之後利用DOM提供的不同函式來讀取該文件的內容和結構,也可以把修改過的內容寫入XML檔案。由於DOM是將XML讀取到記憶體,然後解析成一個樹,如果要處理的XML文字比較大的話,就會很耗記憶體,所以DOM一般偏向於處理一些小的XML,(如配置檔案)比較快。 - SAX(simple API for XML)
Python標準庫中包含SAX解析器,SAX是用的是事件驅動模型,通過在解析XML過程
中觸發一個個的事件並呼叫使用者定義的回撥函式來處理XML檔案。
解析的基本過程:
讀到一個XML開始標籤,就會開始一個事件,然後事件就會呼叫一系列的函式去處理
一些事情,當讀到一個結束標籤時,就會觸發另一個事件。所以,我們寫XML文件入
如果有格式錯誤的話,解析就會出錯。
這是一種流式處理,一邊讀一邊解析,佔用記憶體少。適用場景如下:
1、對大型檔案進行處理;
2、只需要檔案的部分內容,或者只需從檔案中得到特定資訊。
3、想建立自己的物件模型的時候。 - ElementTree(元素樹)
ElementTree就像一個輕量級的DOM,具有方便友好的API。程式碼可用性好,速度快,消耗記憶體少。
注:因DOM需要將XML資料對映到記憶體中的樹,一是比較慢,二是比較耗記憶體,而SAX流式讀取XML檔案,比較快,佔用記憶體少,但需要使用者實現回撥函式(handler)
xml.dom解析XML
本次先介紹DOM方式操作XML,先建立名為book.xml的檔案供後續使用。
<?xml version="1.0" encoding="utf-8" ?>
<!--this is a test about xml.-->
<booklist type="science and engineering">
<book category="math">
<title>learning math</title>
<author>張三</author>
<pageNumber>561</pageNumber>
</book>
<book category="Python">
<title>learning Python</title>
<author>李四</author>
<pageNumber>600</pageNumber>
</book>
</booklist>
minidom.parse(parse=None,bufsie=None)
函式作用:使用parse解析器開啟xml文件,並將其解析為DOM文件,也就是記憶體中的一棵樹,並得到這個物件
doc.docunmentElement
獲取xml文件物件,就是拿到DOM樹的根
程式碼示例:
>>> from xml.dom.minidom import parse
>>> DOMTree=parse(r'book.xml')
>>> type(DOMTree)
<class 'xml.dom.minidom.Document'>
>>> booklist=DOMTree.documentElement
>>> booklist
<DOM Element: booklist at 0x19c0606b340>
doc.toxml(encoding=None)
返回xml的文件內容
>>> booklist=DOMTree.documentElement
>>> print (booklist.toxml())
<booklist type="science and engineering">
<book category="math">
<title>learning math</title>
<author>張三</author>
<pageNumber>561</pageNumber>
</book>
<book category="Python">
<title>learning Python</title>
<author>李四</author>
<pageNumber>600</pageNumber>
</book>
</booklist>

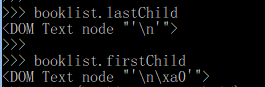
node.lastChild
返回元素的最後一個子節點
node.firstChild
返回元素的首個子節點
程式碼示例:
>>> booklist.lastChild
>>> booklist.firstChild
getElementsByTagName(name)獲取節點元素
獲取xml文件中的某個父節點下具有相同節點名的節點物件的集合。返回的是list
程式碼示例:
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'book.xml')
#獲取xml文件物件,就是拿到樹的根
booklist=DOMTree.documentElement
#獲取booklist物件中所有book節點的list集合
books=booklist.getElementsByTagName('book')
print(books)
print (type(books))
print(books)
print('有%d個book節點'%len(books))
print('*'*40)
print('第一個book節點%s'%booklist.getElementsByTagName('book')[0])
print('*'*40)
print('第一個book節點節點內容%s'%booklist.getElementsByTagName('book')[0].toxml())
print('*'*40)
print('第一個title節點%s'%booklist.getElementsByTagName('title')[0].toxml())

hasAttribute(name)判斷是否包含屬性值
程式碼示例:
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'book.xml')
#獲取xml文件物件,就是拿到樹的根
booklist=DOMTree.documentElement
print('DOM樹的根物件:',booklist)
if booklist.hasAttribute('type'):
#判斷根節點booklist是否有type屬性
print('booklist 元素存在type屬性')
else:
print('booklist 元素不存在type屬性!!!')
if booklist.getElementsByTagName('book')[0].hasAttribute('category'):
#判斷第一個book節點是否有category屬性
print('第一個book節點存在category屬性')
else:
print('第一個book節點不存在category屬性!!!')

node.getAttribute(name):獲取節點node的屬性值
程式碼示例:’’‘Node.getAttribute獲取節點的屬性值’’’
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'book.xml')
#獲取xml文件物件,就是拿到樹的根
booklist=DOMTree.documentElement
if booklist.hasAttribute('type'):
#判斷根節點booklist是否有type屬性
print('booklist 元素存在type屬性')
print ('根節點booklist的type屬性值為:',booklist.getAttribute('type'))
else:
print('booklist 元素不存在type屬性!!!')

node.childNodes:返回節點node下所有的子節點組成的list
程式碼示例:’’‘node.childNodes’’’
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'book.xml')
#獲取xml文件物件,就是拿到樹的根
booklist=DOMTree.documentElement
#獲取booklist物件中所有book節點的list集合
books=booklist.getElementsByTagName('book')
print('第一個book元素的所有子節點:',books[0].childNodes)

獲得標籤屬性
每一個結點都有它的nodeName,nodeValue,nodeType屬性
node.nodeName
node.nodeValue #nodeValue是結點的值,只對文字結點有效
node.nodeType
程式碼示例:’’‘獲取標籤屬性’’'
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'movie.xml')
#獲取xml文件物件,就是拿到樹的根
collection=DOMTree.documentElement
print ('collection屬性',collection.nodeName,collection.nodeValue,collection.nodeType)
#獲取所有的movies節點
movies=collection.getElementsByTagName('movie')
#遍歷集合,列印所有節點的nodename/nodeValue/nodeType
for movie in movies:
print ("*******************movie*******************")
for node in movie.childNodes:
print (node.nodeName,node.nodeValue,node.nodeType)
獲取節點文字值
程式碼示例:’’‘獲取節點文字值’’'
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'book.xml')
#獲取xml文件物件,就是拿到樹的根
booklist=DOMTree.documentElement
if booklist.hasAttribute('type'):
#判斷根節點booklist是否有type屬性,有則獲取並列印屬性值
print('Root element is ',booklist.getAttribute('type'))
#獲取booklist物件中所有的book節點的list集合
books=booklist.getElementsByTagName('book')
print('book節點的個數為:',len(books))
print('book節點的個數為:',books.length)
print ()
for book in books:
print ("*******************book*******************")
if book.hasAttribute('category'):
print ('category is ',book.getAttribute('category'))
#根據節點名title/author/pageNumber得到這些節點的集合list
title=book.getElementsByTagName('title')[0]
author=book.getElementsByTagName('author')[0]
pageNumber=book.getElementsByTagName('pageNumber')[0]
print ('title is ',title.childNodes[0].data)
print ('author is ',author.childNodes[0].data)
print ('pageNumber is ',pageNumber.childNodes[0].data)

node.hasChildNodes():判斷是否有子節點
程式碼示例:’’‘node .hasChildNodes()’’'
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'book.xml')
#獲取xml文件物件,就是拿到樹的根
booklist=DOMTree.documentElement
if booklist.hasAttribute('type'):
#判斷根節點booklist是否有type屬性,有則獲取並列印屬性值
print('Root element is ',booklist.getAttribute('type'))
#獲取booklist物件中所有的book節點的list集合
books=booklist.getElementsByTagName('book')
print('book節點的個數為:',books.length)
print ()
if books[0].hasChildNodes():
print('存在子節點:',books[0].childNodes)
else:
print('不存在子節點')

主要方法總結:
minidom.parse(filename):載入讀取XML檔案
doc.documentElement:獲取XML文件物件
node.getAttribute(AttributeName):獲取XML節點屬性值
node.getElementsByTagName(TagName):獲取XML節點物件集合
node.childNodes :返回子節點列表。
node.childNodes[index].nodeValue:獲取XML節點值
node.firstChild:訪問第一個節點,等價於pagexml.childNodes[0]
返回Node節點的xml表示的文字:
doc = minidom.parse(filename)
doc.toxml(‘UTF-8’)
訪問元素屬性:
Node.attributes[“id”]
a.name #就是上面的 “id”
a.value #屬性的值
root.nodeName/root.tagName:節點的名稱
root.nodeValue:節點的值,文字節點才有值,其它節點返回的是None
root.nodeType:節點的型別
NodeType Named Constant

練習1:讀取xml檔案寫入excel
程式碼示例:
‘’‘將xml檔案寫入到檔案中’’’
from xml.dom.minidom import parse
from openpyxl import Workbook
DOMTree=parse(r’book.xml’)
booklist=DOMTree.documentElement
type_name=booklist.getAttribute(‘type’)
#獲取第二個book物件的內容
book=booklist.getElementsByTagName(‘book’)[1]
book_name=book.getAttribute(‘category’)
title=book.getElementsByTagName(‘title’)[0].childNodes[0].data
author=book.getElementsByTagName(‘author’)[0].childNodes[0].data
pageNumber=book.getElementsByTagName(‘pageNumber’)[0].childNodes[0].data
wb=Workbook()
ws=wb.active
ws.append([book_name,title,author,pageNumber])
wb.save(r’book.xlsx’)
練習2:xml.dom解析xml的一個例項
xml檔案內容:
<?xml version="1.0" encoding="utf-8" ?>
<!--this is a test about xml.-->
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>
程式碼示例:’’‘xml.dom解析xml的一個例項’’’
from xml.dom.minidom import parse
#minidom解析器開啟xml文件並將其解析為記憶體中的一棵樹
DOMTree=parse(r'move.xml')
#獲取xml文件物件,就是拿到樹的根
collection=DOMTree.documentElement
if collection.hasAttribute('shelf'):
#判斷根節點collection是否有shelf屬性,有則獲取並列印屬性值
print('Root element is ',collection.getAttribute('shelf'))
#獲取所有的movies節點
movies=collection.getElementsByTagName('movie')
#遍歷集合,列印每部電影的詳細資訊
for movie in movies:
print ("*******************movie*******************")
my_list=[]
if movie.hasAttribute('title'):
print ('title is ',movie.getAttribute('title'))
for node in movie.childNodes:
my_list.append (node.nodeName)
type=movie.getElementsByTagName('type')[0]
print ('type is ',type.childNodes[0].data)
format=movie.getElementsByTagName('format')[0]
print ('format is ',format.childNodes[0].data)
if 'year' in my_list:
year=movie.getElementsByTagName('year')[0]
print ('year is ',year.childNodes[0].data)
rating=movie.getElementsByTagName('rating')[0]
print ('rating is ',rating.firstChild.data)
stars=movie.getElementsByTagName('stars')[0]
print ('stars is ',stars.childNodes[0].data)
description=movie.getElementsByTagName('description')[0]
print ('description is ',description.childNodes[0].data)

xml.dom建立XML檔案
建立步驟:
1.建立XML空白文件
2.產生根物件
3.向根物件中加入資料
4.將xml記憶體物件寫入檔案
minidom.Document()建立xml空白文件
該方法用於建立一個空白的xml文件物件,並返回這個doc物件。每個xml文件都是一個Document物件,代表著記憶體中的DOM樹
程式碼示例:’’‘minidom.Document()建立xml空白文件’’'
import xml.dom.minidom
#在記憶體中建立一個空的文件
doc=xml.dom.minidom.Document()
print(doc)

doc.createElement(tagName)
生成XML文件節點。引數表示待生成的節點名稱
程式碼示例:
import xml.dom.minidom
#在記憶體中建立一個空的文件
doc=xml.dom.minidom.Document()
#建立一個根節點物件
root=doc.createElement('Manager')
print('新增的xml標籤為:',root.tagName)
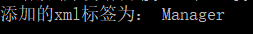
node.setAttribute(attname,value)
函式作用:給節點新增屬性-值對(attribute)
引數說明:
attname:屬性的名稱
value:屬性的值
程式碼示例:’’‘node.setAttribute(attname,value)’’'
import xml.dom.minidom
#在記憶體中建立一個空的文件
doc=xml.dom.minidom.Document()
#建立一個根節點物件
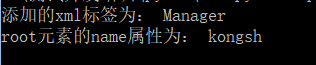
root=doc.createElement('Manager')
print('新增的xml標籤為:',root.tagName)
#給根節點新增屬性
root.setAttribute('name','kongsh')
value=root.getAttribute('name')
print('root元素的name屬性為:',value)
doc.createTextNode(data)
給葉子節點新增文字節點
程式碼示例:’’‘doc.createTextNode(data)’’'
import xml.dom.minidom
#在記憶體中建立一個空的文件
doc=xml.dom.minidom.Document()
#建立一個根節點物件
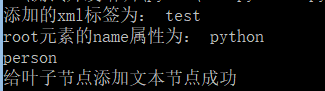
root=doc.createElement('test')
print('新增的xml標籤為:',root.tagName)
#給根節點新增屬性
root.setAttribute('name','python')
value=root.getAttribute('name')
print('root元素的name屬性為:',value)
#給根節點新增一個葉子節點
ceo=doc.createElement('person')
#給葉子節點ceo設定一個文字節點,用於顯示文字內容
ceo.appendChild(doc.createTextNode('kongsh'))
print (ceo.tagName)
print ("給葉子節點新增文字節點成功")
parent.appendChild(childNode)
把子節點childNode新增到父節點parent中
程式碼示例:’’‘parent.appendChild(childNode)’’'
import xml.dom.minidom
#在記憶體中建立一個空的文件
doc=xml.dom.minidom.Document()
#建立一個根節點companys物件
root=doc.createElement('companys')
print('新增的xml標籤為:',root.tagName)
#給根節點新增屬性
root.setAttribute('name','公司資訊')
#將根節點新增到文件物件中
doc.appendChild(root)
#給根節點新增一個葉子節點
company=doc.createElement('gloryroad')
#葉子節點下再巢狀葉子節點
name=doc.createElement('name')
#給節點新增文字節點
name.appendChild(doc.createTextNode('光榮之路'))
ceo=doc.createElement('CEO')
ceo.appendChild(doc.createTextNode('吳老師'))
#將各葉子節點新增到父節點company中
company.appendChild(name)
company.appendChild(ceo)
#將company節點新增到根節點companys中
root.appendChild(company)
print (doc.toxml())

doc.writexml():生成xml文件
函式作用:用於將記憶體中的xml文件樹寫入到檔案中,並儲存到本地磁碟。只有呼叫該方法後,才能將上面建立的存在於記憶體中的xml文件寫入本地硬碟中,這時才能看到新建的xml文件
語法:
writexml(file,indent=’’,addindent=’’,newl=’’,endocing=None)
引數說明:
file:要儲存為的檔案物件名
indent:根節點的縮排方式
allindent:子節點的縮排方式
newl:針對新行,指明換行方式
encoding:儲存檔案的編碼方式
程式碼示例:’’‘writexml(file,indent=’’,addindent=’’,newl=’’,endocing=None)’’'
import xml.dom.minidom
#在記憶體中建立一個空的文件
doc=xml.dom.minidom.Document()
#建立一個根節點companys物件
root=doc.createElement('companys')
print('新增的xml標籤為:',root.tagName)
#給根節點新增屬性
root.setAttribute('name','公司資訊')
#將根節點新增到文件物件中
doc.appendChild(root)
#給根節點新增一個葉子節點
company=doc.createElement('gloryroad')
#葉子節點下再巢狀葉子節點
name=doc.createElement('name')
#給節點新增文字節點
name.appendChild(doc.createTextNode('光榮之路'))
ceo=doc.createElement('CEO')
ceo.appendChild(doc.createTextNode('吳老師'))
#將各葉子節點新增到父節點company中
company.appendChild(name)
company.appendChild(ceo)
#將company節點新增到根節點companys中
root.appendChild(company)
#此處需要用codecs.open可以指定編碼方式
fp=open(r'company.xml','w','utf-8')
#將記憶體中的xml寫入到檔案
doc.writexml(fp,indent='',addindent='\t',newl='\n',encoding='utf-8')
fp.close()