
python3基礎:操作json
json是java script object notation的縮寫,用來儲存和交換文字資訊,比xml更小/更快/更易解析,易於讀寫,佔用頻寬小,網路傳輸速度快的特性,適用於資料量大,不要求保留原有型別的情況。
json語法規則
資料在名稱/值對中
資料用逗號分隔
花括號儲存物件
方括號儲存陣列
json名稱/值對
名稱/值對包括欄位名稱(在雙引號中),後面寫一個冒號,然後是值,例:
“firstname”:“json”
json資料型別
數字(整數、浮點數)
字串(在雙引號中)
邏輯值(true或false)
陣列(在方括號中)
物件(在花括號中)
null
json物件
在花括號中書寫,物件可以包含多個名稱/值對,例:
{“firstname”:“jonh”,“lastname”:“Doe”}
json陣列
employees是包含三個物件的陣列。每個物件代表一條關於某個人名的記錄,在方括號中書寫,陣列可以包含多個物件:
{
“employees”:[
{ “firstName”:“John” , “lastName”:“Doe” },
{ “firstName”:“Anna” , “lastName”:“Smith” },
{ “firstName”:“Peter” , “lastName”:“Jones” }
]
}
python解析json的流程
使用時需要import json匯入
json.dumps():將python物件編碼為json的字串
json.loads():將字串編碼為一個python物件
json.dump():將python物件序列化到一個檔案,是文字檔案,相當於將序列化後的json字元寫到一個檔案
json.load():從檔案反序列表出python物件
總結:不帶s的是序列化到檔案或者從檔案反序列化,帶s的都是記憶體操作不涉及持久化
json.dumps()
將一個Python資料型別列表編碼成json格式的字串
#python的列表轉換為json的陣列 >>> import json >>> json.dumps([1,2,3]) '[1, 2, 3]' #python的字串轉換為json的字串 >>> json.dumps('abdcs') '"abdcs"' #python的元祖轉換為json的陣列 >>> json.dumps((1,2,3,'a')) '[1, 2, 3, "a"]'#注意此時顯示的是方括號 #python的字典轉換為json的物件 >>> json.dumps({1:'a',2:'b'}) '{"1": "a", "2": "b"}'#注意此時1和2轉換後是加了引號的,因為json的名稱是必須要加引號的 #python的整數轉換為json的數字 >>> json.dumps(13) '13' #python的浮點數轉換為json的數字 >>> json.dumps(3.1415) '3.1415' #python的unicode字串轉換為json的字串 >>> json.dumps(u'a') '"a"' #python的True轉換為json的陣列true >>> json.dumps(True) 'true' #python的False轉換為json的陣列false >>> json.dumps(False) 'false' #python的None轉換為json的null >>> json.dumps(None) 'null' #json本質上是一個字串 >>> type(json.dumps('abc')) <class 'str'>
python型別和json型別的對應關係
根據以上輸出結果會發現Python物件被轉成JSON字串以後,跟原始的資料型別相比會有些特殊的變化,原字典中的元組被改成了json型別的陣列。在json的編碼過程中,會存在從Python原始型別轉化json型別的過程,但這兩種語言的型別存在一些差異,對照表如下:

程式碼示例:Python型別與json型別示例比對
#coding=utf-8
import json
a = [{1:12,"a":12.3}, [1,2,3],(1,2), "asd", "ad", 12,13,3.3,True, False, None]
print("Python型別:\n", a)
print("編碼後的json串:\n", json.dumps(a))

如何判斷一個json是否合法
import json
try:
## json.loads('"abc"')
json.loads('''abc''')
except Exception as e:
print (e)
else:
print('ok')
json.dumps()函式引數的使用
help(“json.dumps”)檢視文件,函式原型:
dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
該方法返回編碼後的一個json字串,是一個str物件encodedjson。dumps函式的引數很多,下面只說明幾個比較常用的引數。
sort_keys
是否按字典排序(a到z)輸出,預設編碼成json格式字串後,是緊湊輸出,並且也沒有順序的,不利於可讀。sort_keys等於True表示升序
程式碼示例:
import json
data=[{'a':'A','x':(2,4),'c':3.0}]
print (json.dumps(data))
print (json.dumps(data,sort_keys=True))
輸出結果:

indent
根據資料格式縮排顯示,讀起來更清晰,indent的數值表示縮排的位數
程式碼示例:
import json
data=[{'a':'A','x':(2,4),'c':3.0}]
print (json.dumps(data,sort_keys=True,indent=3))

separators
去掉逗號“,”和冒號“:”後面的空格。從上面的結果中可以看出‘, :’後面都有個空格,這都是為了美化的作用,但是在傳輸的過程中,越精簡越好,冗餘的東西去掉,因此就可以加上separators引數對傳輸的json串進行壓縮。該引數是元組格式的。
程式碼示例:
import json
data=[{'a':'A','b':(2,4),'c':3.0}]
print (json.dumps(data))
print (json.dumps(data,separators=(',',':')))

shipkeys
在encoding的過程中,dict的物件只能是基本資料類似(int,float,bool,None,str),如果是其它型別,那麼在編碼的過程中就會丟擲ValueError異常。shipkeys可以跳過那些非string物件的key的處理,就是不處理。
程式碼示例:
#coding=utf-8
import json
data= [ { 'a':'A', 'b':(2, 4), 'c':3.0,(1,2):'D tuple'} ]
try:
res=json.dumps(data)#skipkeys引數預設為False時
except Exception as e:
print (e)
print(u"設定skipkeys 引數")
print (json.dumps(data,skipkeys=True)))

ensure_ascii
表示編碼使用的字符集,預設是True,表示使用ascii碼進行編碼。如果設定為False,就會以Unicode進行編碼。由於解碼json字串時返回的就是Unicode字串,所以可以直接操作Unicode字元,然後直接編碼Unicode字串,這樣會簡單些。
程式碼示例:
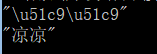
import json
print (json.dumps('涼涼'))
print (json.dumps('涼涼',ensure_ascii=False))
default:將類物件編碼成Json串
Python中的dict物件可以直接序列化為json的{},但是很多時候,可能用class表示物件,比如定義Employe類,然後直接去序列化就會報錯。原因是類不是一個可以直接序列化的物件,但我們可以使用dumps()函式中的default引數來實現,由兩種方法:
- 在類內部定義一個obj_json 方法將物件的屬性轉換成dict,然後再被序列化為json。
- 通過__dict__屬性,通常class及其例項都會有一個__dict__屬性(除非類中添加了__slots__屬性),它是一個dict型別,儲存的是類或類例項中有效的屬性
程式碼示例1:通過類中的方法實現
import json
class Employee(object):
def __init__(self,name,age,sex,tel):
self.name=name
self.age=age
self.sex=sex
self.tel=tel
#將序列化函式定義到類中
def obj_json(self,obj_instance):
return{
'name':obj_instance.name,
'age':obj_instance.age,
'sex':obj_instance.sex,
'tel':obj_instance.tel
}
emp=Employee('kongsh',28,'female',13123456789)
print (json.dumps(emp,default=emp.obj_json))
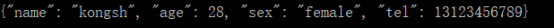
程式碼示例2:通過類的__dict__屬性實現
import json
class Employee(object):
def __init__(self,name,age,sex,tel):
self.name=name
self.age=age
self.sex=sex
self.tel=tel
emp=Employee('kongsh',18,'female',13123456789)
print (emp.__dict__)
print (json.dumps(emp,default=lambda Employee:Employee.__dict__))
print (json.dumps(emp,default=lambda emp:emp.__dict__))

json.loads()
將json的字串解碼成python物件
>>> json.loads('{"a":"b"}')#外面用單引號
{'a': 'b'}
>>> json.loads('{"2":1}')
{'2': 1}
>>> a=json.loads('{"1":{"a":"b"}}')
>>> a
{'1': {'a': 'b'}}
json轉換為python
由以上輸出可以看出編碼過程中,Python中的list和tuple都被轉化成json的陣列,而解
碼後,json的陣列最終被轉化成Python的list的,無論是原來是list還是tuple。

程式碼示例:從json到Python的型別轉化
#coding=utf-8
import json
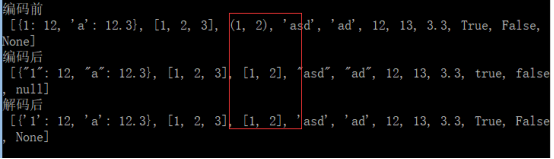
a = [{1:12, 'a':12.3}, [1,2,3], (1,2), 'asd', 'ad', 12, 13, 3.3, True, False, None]
print(u"編碼前\n", a)
print(u"編碼後\n", json.dumps(a))
print(u"解碼後\n", json.loads(json.dumps(a)))
注意:
json格式的字串解碼成Python物件以後,String型別都變成了Unicode型別,陣列變成了list,不會回到原來的元組型別,字典key的字元型別也被轉成Unicode型別
json反序列化為物件
json反序列化為類物件或者類的例項,使用的是loads()方法中的object_hook引數
程式碼示例:
import json
class Employee(object):
def __init__(self,name,age,sex,tel):
self.name=name
self.age=age
self.sex=sex
self.tel=tel
emp=Employee('kongsh',18,'female',13123456789)
def jsonToClass(emp):
return Employee(emp['name'], emp['age'], emp['sex'], emp['tel'])
json_str='{"name": "kongsh", "age": 18, "sex": "female", "tel": 13123456789}'
e=json.loads(json_str,object_hook=jsonToClass)
print (e)
print(e.name)
