
TensorBoard進行視覺化
TensorBoard是TensorFlow下的一個視覺化的工具,能夠幫助研究者們視覺化訓練大規模神經網路過程中出現的複雜且不好理解的運算,展示訓練過程中繪製的影象、網路結構等。
一、配置環境
對tensorflow視覺化首先需要tf官網提供的tensorboard.exe這個程式,當然這個程式在下載tf的時候也是自帶的,我是用anaconda進行安裝和配置的,則tensorboard.exe位於"E:\Anaconda\Scripts"目錄下,首先將這個目錄新增到環境變數中,在使用者變數的Path中,新增工具路徑。

二、視覺化操作
tensorboard.exe對tf進行視覺化的時候,需要tf生成的events.out.tfevents檔案。
而且,有一個需要注意的地方,tensorboard.exe呼叫是基於當前路徑的,就是你cmd命令列所示的目錄。所以最簡單的呼叫方法是直接上訴tfevents目錄,直接輸入cmd,開啟命令列工具

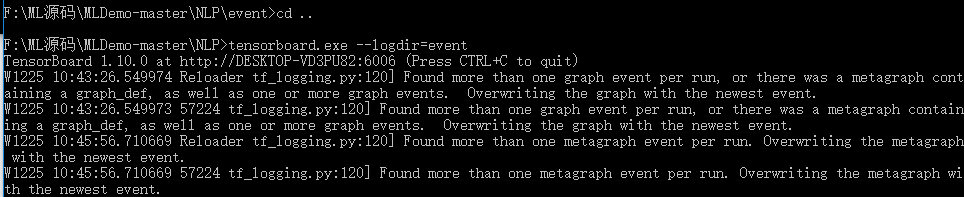
然後回退到上一目錄進行呼叫
呼叫命令:
tensorboard.exe --logdir = event所在目錄如下圖所示,然後在瀏覽器開啟指定的網址,就可以檢視視覺化的結果了
http://desktop-vd3pu82:6006

相關推薦
TensorBoard進行視覺化
TensorBoard是TensorFlow下的一個視覺化的工具,能夠幫助研究者們視覺化訓練大規模神經網路過程中出現的複雜且不好理解的運算,展示訓練過程中繪製的影象、網路結構等。 一、配置環境 對tensorflow視覺化首先需要tf官網提供的tensorboard.e
88、使用tensorboard進行視覺化學習,檢視具體使用時間,訓練輪數,使用記憶體大小
''' Created on 2017年5月23日 @author: weizhen ''' import os import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_d
TensorFlow-- 啟動TensorBoard並進行視覺化
tensorboard可以視覺化所建造出來的神經網路,有助於理解神經網路的內部結構和複雜運算,展示訓練過程中繪製的影象、網路結構等。 資料準備 import tensorflow as tf with tf.name_scope('input1'):
機器學習入門-載入sklearn中資料並用matplotlib進行視覺化
from sklearn import datasets import matplotlib.pyplot as plt def get_data(): """ 從sklearn中獲取鳶尾花的資料 :return: 鳶尾花資料的字典,字典中包括的key有:【'data'
NLP之WE之Skip-Gram:基於TF利用Skip-Gram模型實現詞嵌入並進行視覺化、過程全記錄
NLP之WE之Skip-Gram:基於TF利用Skip-Gram模型實現詞嵌入並進行視覺化 輸出結果 程式碼設計思路 程式碼執行過程全記錄 3081 originated -> 12 as 3081 originated
資料分析(使用matplotlib,seaborn,ploty進行視覺化)——1
柱狀圖 使用matplotlib畫圖 import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np # 匯入資料 df = pd.read_csv(
Pytorch求索(2): Pytorch使用visdom進行視覺化
Pytorch使用visdom進行視覺化 文章目錄 Pytorch使用visdom進行視覺化 visdom介紹 visdom核心概念 visdom安裝與使用 常用API plot.scat
應用圖表進行視覺化時,如何有效地展現資料?
歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 大部分人對資料進行視覺化時,只是一種圖表的堆砌,先把需要的單個圖表做完,然後簡單地羅列組合在一起,最後改變一下整體顏色,就完成了。整個過程雖然不能說錯,但並沒有把圖表的優勢發揮出來。下面分享一些用圖表展現資料的方法,希望對題主有所幫助。
【Visual Studio 擴充套件工具】使用 ComponentOne迷你圖控制元件,進行視覺化資料趨勢分析
概述 迷你圖 —— Sparklines是迷你的輕量級圖表,有助於快速視覺化資料。 它們是由資料視覺化傳奇人物Edward Tufte發明的,他將其描述為“資料密集,設計簡單,位元組大小的圖形。”雖然迷你圖不包含傳統圖表中的許多元素(如軸和座標), 基於它們的簡單性,它們可以比其他圖表型別更具資訊性
爬取微信好友資訊,進行視覺化分析(頭像人臉識別部分已更新!)(程式碼已上傳)
【Code】下載 1、專案說明 本次專案主要實現了以下功能: 2、微信好友資訊的獲取與檔案儲存 3、微信好友性別分析 4、微信好友地區分佈視覺化 5、微信好友個性簽名詞雲圖及好友備註詞雲圖 6、微信好
行人重識別(ReID) ——基於MGN-pytorch進行視覺化展示
模型訓練,修改demo.sh,將 --datadir修改已下載的Market1501資料集地址,將修改CUDA_VISIBLE_DEVICES=2,3自己的GPU裝置ID,將修改--nGPU自己的GPU數量。 部分demo.sh示例: #mAP: 0.920
使用ROS的rqt_plot對任意語言的程式進行視覺化
簡介 經常做資料處理的同學可能比較熟悉MATLAB或者Python,而做影象或者機器人用到最多的其實是C和C++。經常需要在除錯時實時看到某些資料的變化趨勢,而C++卻沒有一套好的視覺化庫(或者需要很麻煩的配置。)於是寫了這個工具。呼叫者只要在程式裡列印需要實時顯示的資料,然後將控制
爬取拉勾熱門城市“資料分析”崗位,並進行視覺化分析
首先,寫一個爬取崗位的爬蟲,如下:# -*- coding:utf-8 -*- from json import JSONDecodeError import requests import time import pandas as pd # 獲取儲存職位資訊的json
利用 ELK系統分析Nginx日誌並對資料進行視覺化展示
一、寫在前面 結合之前寫的一篇文章:Centos7 之安裝Logstash ELK stack 日誌管理系統,上篇文章主要講了監控軟體的作用以及部署方法。而這篇文章介紹的是單獨監控nginx 日誌分析再進行視覺化圖形展示,並在使用者前端使用nginx 來代理kibana
Caffe提取任意層特徵並進行視覺化
原圖 conv1層視覺化結果 (96個filter得到的結果) 資料模型與準備 安裝好Caffe後,在examples/images資料夾下有兩張示例影象,本文即在這兩張影象上,用Caffe提供的預訓練模型,進行特徵提取,並進行視覺化。 1. 進入
利用TICK對Docker進行視覺化監控
效能監控是容器服務必不可少的基礎設施,容器化應用運行於宿主機上,我們需要知道該容器的執行情況,包括 CPU使用率、記憶體佔用、網路狀況以及磁碟空間等等一系列資訊。本文通過TICK 的技術棧方案實現Docker的效能監控。 一、監控結構 Telegraf:
TensorFlow-tensorboard結果視覺化
TensorFlow-tensorboard結果視覺化 硬體:NVIDIA-GTX1080 軟體:Windows7、python3.6.5、tensorflow-gpu-1.4.0 一、基礎知識 tensorboard為TensorFlow網路視覺化的介面 tf.name_s
Spark GraphX 對圖進行視覺化
Spark 和 GraphX 對並不提供對資料視覺化的支援, 它們所關注的是資料處理. 但是, 一圖勝千言, 尤其是在資料分析時. 接下來, 我們構建一個視覺化分析圖的 Spark 應用. 需要用到的第三方庫有: GraphStream: 用於畫出網路圖BreezeViz
爬取鏈家租房資料,資料處理,進行視覺化分析
lianjiaspider.py import asyncio import aiohttp import pandas as pd from lxml import etree class LianjiaSpider(object): def __init
matplotlib—三種方法載入資料檔案進行視覺化
1.csv獲取資料 (1)匯入模組 from matplotlib import pyplot as plt import numpy as np import csv #用來正常顯示中文標籤 plt.rcParams['font.sans-serif