
Machine Learning Yearning(3、4)
Chapter 3、Prerequisites and Notation
預備知識和註釋
如果你有學習過機器學習課程,比如我在Coursera上的的機器學習MOOC,或者如果你有應用監督學習的經驗,你也將能夠理解這段文字。
我假設你熟悉監督學習(supervised learning):使用標記的訓練樣本(x,y)去學習一個從x對映到y的函式。 監督學習演算法包括線性迴歸(linear regression),邏輯迴歸(logistic regression)和神經網路(neural networks)。 機器學習的形式有很多,但是現如今大部分機器學習的實用價值來自於監督學習。
我將經常提到神經網路(也稱為“deep learning”)。你只需要遵循本問對它是什麼有一個基本的理解就可以了。
如果您不熟悉這裡提到的概念,請觀看在Coursera上前三週 機器學習視訊課程

Chapter 4、Scale drives machine learning progress
規模驅使機器學習前進
深度學習(神經網路)的許多想法已經存在幾十年了。 為什麼這些想法現在才火起來?
最近得以進步的最大驅動因素有兩個:
- 資料可用性。 人們現在在數字裝置(膝上型電腦,移動裝置)上花費更多的時間。這些活動產生大量的資料,我們可以使用這些資料來訓練和反饋我們的學習演算法。
- 計算尺度。 我們幾年前才開始能夠訓練足夠大的神經網路,以利用我們現在擁有的巨大的資料集。
具體來說,即使你積累了更多的資料,通常傳統學習演算法(如邏輯迴歸)的效能表現“平穩”。這意味著它的學習曲線“平坦”,即使你給它更多的資料,演算法也不會再有提升效果。
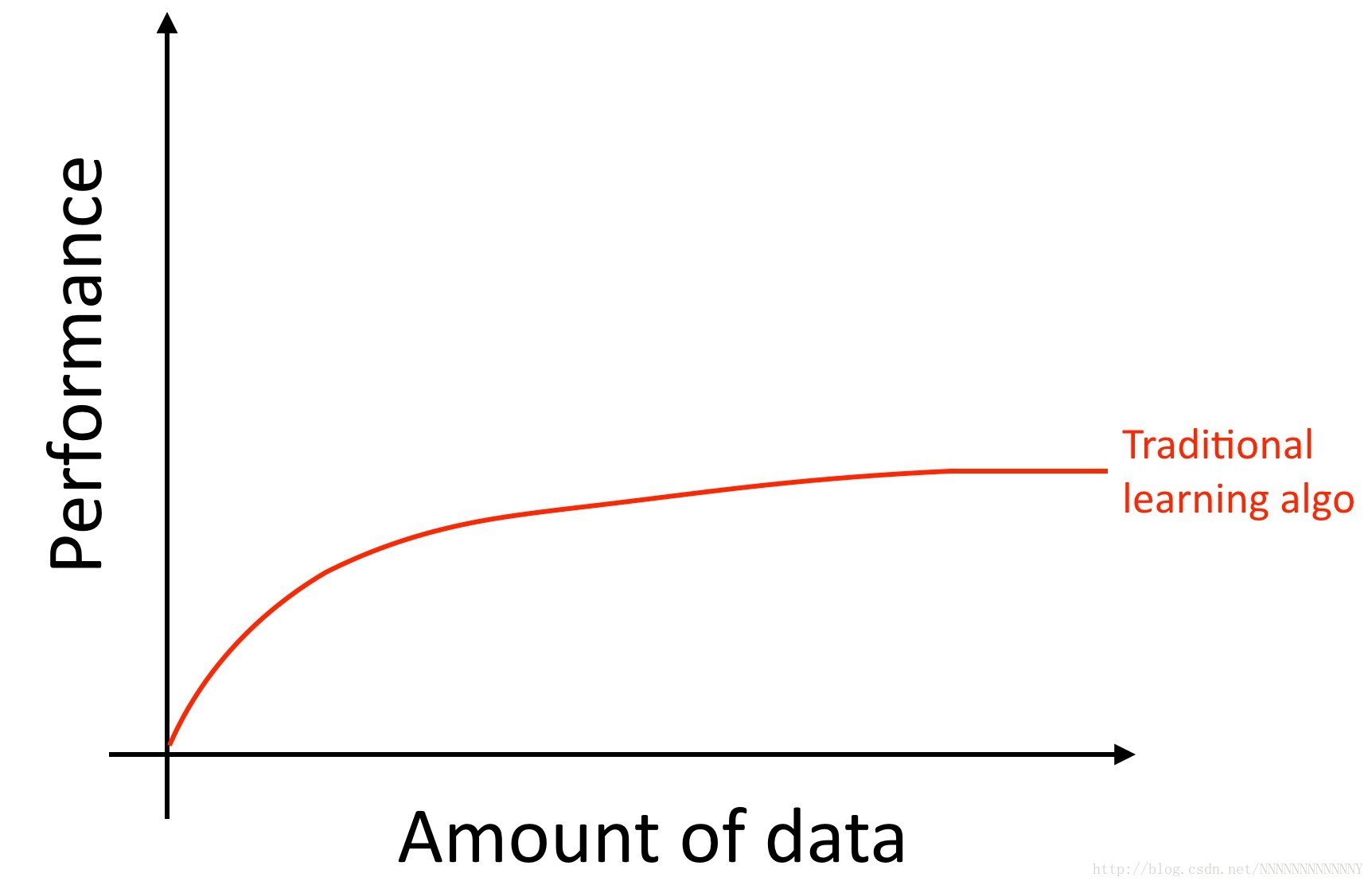
這就好像傳統的演算法不知道如何處理我們現在擁有的所有資料。
如果你在同一個監督學習任務上訓練一個小的神經網路(NN),你可能會獲得略好一點的效能:

這裡,“小的神經網路”是指僅具有少量隱藏單位/層/引數的神經網路。 最後,如果你訓練越來越大的神經網路,你可以獲得更好的效能:[1]

因此,當你做到下面兩點的時候你會獲得最佳的效能(i)訓練一個非常大的神經網路,使其在上面的綠色曲線上; (ii)有大量的資料。
許多其他細節,如神經網路架構也很重要,這裡已經有很多創新。 但是現在提高演算法效能的更可靠的方法之一仍然是(i)訓練更大的網路和(ii)獲得更多的資料。
如何完成(i)和(ii)的方法是極其複雜的。 這本書將詳細討論細節。 我們將從對傳統學習演算法和神經網路都有用的一般策略開始,並建立構建深度學習系統所需的最先進策略。
[1]這個圖表展示了NN在小資料集下做得更好。這種效果不如NNs在大資料集中表現良好的效果一致。 在小資料系統中,取決於特徵是如何手工設計的,傳統演算法可能做的很好,也可能做得並不好。 例如,如果你有20個訓練樣本,那麼使用邏輯迴歸還是神經網路可能並不重要; 手工特徵的選擇將比演算法的選擇產生更大的影響。 但如果你有100萬的樣本,我更傾向於神經網路。