
ideal中如何新增幾個不同的專案在同一個idea的顯示頁面
今天,我遇到了一個問題,就是同事給了我一些專案,我下載了之後,專案有點多,然後想把這些專案都放到一個裡面,所以我就採取了新增module的方式進行新增,首先先看一下我們的四個專案,
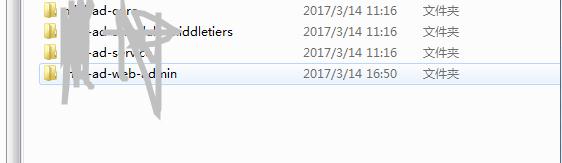
我們就想實現在一個idea裡面進行新增這四個module
1.首先我們要新建一個專案,手動的在那個專案中新建一個資料夾

然後我們可以把要匯入的module,可以手動的貼上到這個myFirstTest的下面,因為我們如果
要import module的話,這個import的這個引用的匯入,而不是物理空間的匯入,所以我們需要手動的
先貼上。
2.然後我們在open這個專案

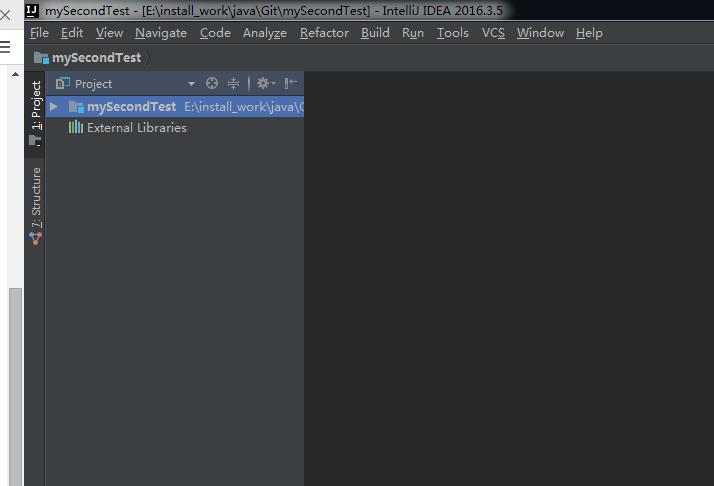
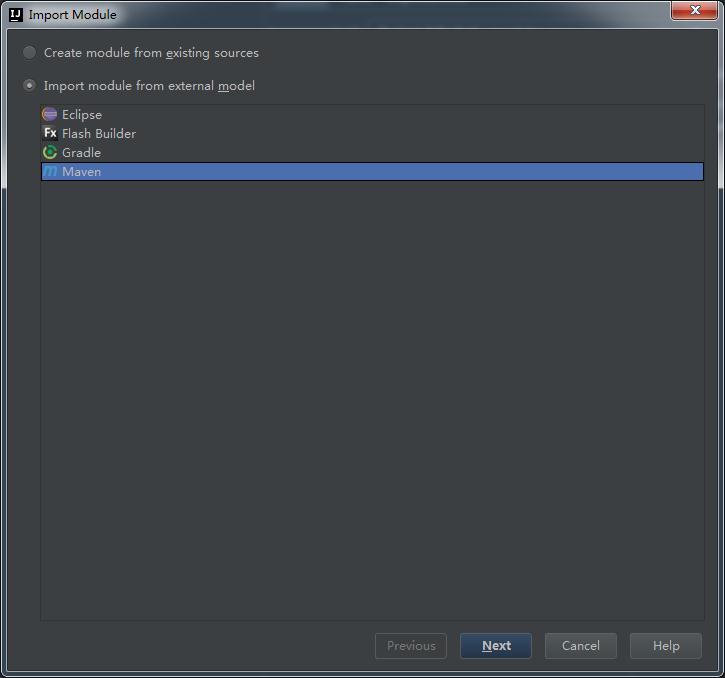
3.然後選擇要新增的module: File->Project Structure...->Modules可以新增Modules
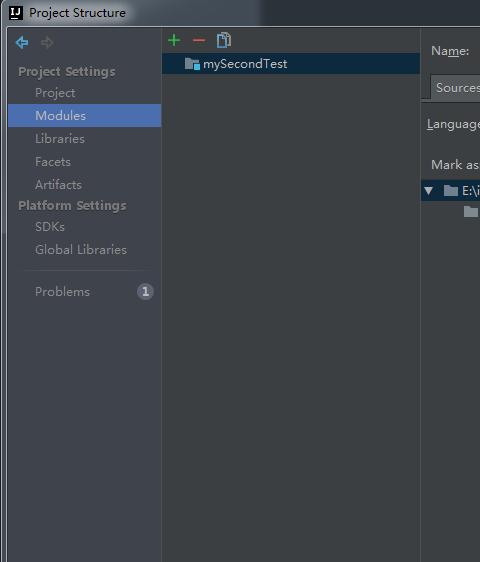
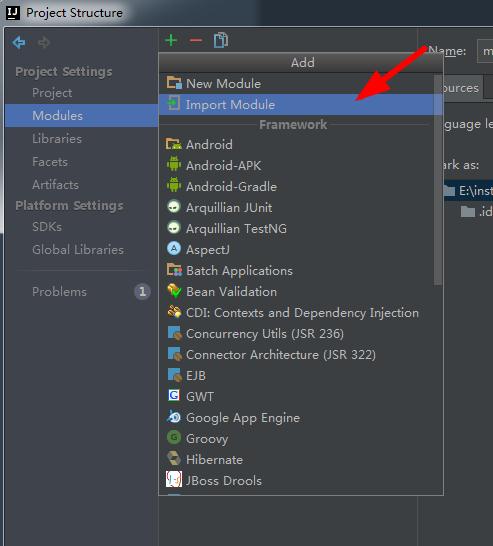
然後我們把這些module匯入進來(我們可以提前把這些手動的貼上,那麼這樣你的物理空間就可以有效了)
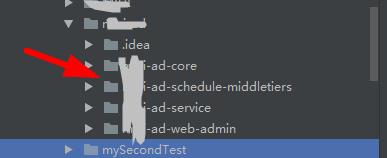
依次類推,我們就可以在我們這個專案就可以看到了四個單獨的modules了
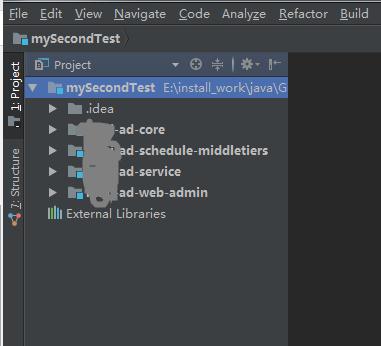
OK,這個樣子,我們就實現了多個module的操作了
相關推薦
ideal中如何新增幾個不同的專案在同一個idea的顯示頁面
今天,我遇到了一個問題,就是同事給了我一些專案,我下載了之後,專案有點多,然後想把這些專案都放到一個裡面,所以我就採取了新增module的方式進行新增,首先先看一下我們的四個專案, 我們就想實現在一個idea裡面進行新增這四個module 1.首先我們要新建一個專案,手動
win7系統中,用登錄檔的方式新增幾個右鍵選單
1.資料夾裡面 空白處》右鍵選單》生成檔案清單 Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\Directory\Background\shell\生成檔案清單] [HKEY_CLASSES_ROOT\Directory\Backgr
使用ArrayList集合,對其新增100個不同的元素: 1.使用add()方法將元素新增到ArrayList集合物件中; 2.呼叫集合的iterator()方法獲得Iterator物件,並呼叫Ite
import java.util.*; public class Example { public static void main(String[] args) { ArrayList list=new ArrayList(); System.out.print
在一個專案中匯入多個不同tensorflow模型
剛開始直接採用呼叫一個模型的方法: (1)定義網路 (2)新建sess:sess = tf.Session(config=config) (3)定義saver:saver = tf.train.S
C++ string中的幾個小陷阱,你掉進過嗎?
stl 試題 賦值 clu ror ati world mod iostream C++開發的項目難免會用到STL的string。使用管理都比char數組(指針)方便的多。但在得心應手的使用過程中也要警惕幾個小陷阱。避免我們項目出bug卻遲遲找不到原因。1. 結構體中的
elasticsearch中的幾個概念總結
查詢 article ase con 總結 diff 返回 cse nan 1、Geo spatial search : 地理空間搜索,可以在搜索查詢中指定的某一距離內查找所要的內容。也可以返回以當前為圓心,逐漸添加圓的半徑。直到找到所匹配到的內容。
python筆記10-切片(從list或字符串中取幾個元素)
-1 下標 功能 切片 name 字符 list python 筆記 name1 = ‘zcl,pyzyz‘names = [‘zcl‘,‘py‘,‘zyz‘]#切片的意思就是從list裏面或者字符串裏面取幾個元素#切片操作對字符串也是完全適用的# print(names[
SQLServer2PostgreSQL遷移過程中的幾個問題
post content enter 文件 中一 postgres 能夠 lac ftw 1、PostgreSQL 跨平臺遷移工具Migration Toolkit的使用指南:http://www.enterprisedb.com/docs/en/8.4/mtkguide/
C程序中讓兩個不同版本的庫共存
lua compile c 原文連接:http://blog.gotocoding.com/archives/875今天有同學提出,如何在一個C程序中讓兩個不同版本的庫共存。首先想到的方案是,把其中一個版本的庫函數全部重命名,比如把每一個函數名都加一個_v2的後綴。人工替換到沒什麽,但是如果函數個
【轉載】Spark學習——spark中的幾個概念的理解及參數配置
program submit man 聯眾 tail 進行 orb 數據源 work 首先是一張Spark的部署圖: 節點類型有: 1. master 節點: 常駐master進程,負責管理全部worker節點。2. worker 節點: 常駐worker進程,負責管理
數據庫基礎查詢語句中的幾個細節
語句 nvl 備註 nav 數據庫 數據庫基礎 細節 字符串 rom 運算 select 姓名列,工資列,工資列*12 from 表名 計算年薪 字符串拼接 irst_name||‘是‘||start_date||‘入職的,工資是‘||salary||‘,職位是
mybatis中的幾個註意的地方
suffix tle ive lis trim student clu 後綴 name 1、首先定義一個sql標簽,一定要定義唯一id<sql id="Base_Column_List" >name,age</sql>2、然後通過id引用<se
Servlet中的幾個重要的對象(轉)
localhost http ttr 屬性 webapps source 指定路徑 開始 orm 講解四大類,ServletConfig對象,ServletContext對象、request對象,response對象 ServletConfig對象 獲取途
php學習筆記-PHP中的幾個取整函數
4.5 一個 個數 等於 之間 gpo 容易 學習 函數 floor是向下取整,比如4.5,它是在4和5之間的一個數,那麽結果就是4。 ceil是向上取整,比如3.7,它是在3和4之間的一個數,那麽結果就是4。 round是對一個數四舍五入,小數部分如果小於5則直接舍去,如
js運算中的幾個註意點
bsp nan 繼續 操作 邏輯或 style log class 判斷 1.除了字符串參與的加法外,非Number類型的值進行運算時,會將這些值轉換為Number然後再運算 var res = true + 100;console.log(res); // =101va
自制貪吃蛇遊戲中的幾個“大坑”
是我 問題 時間 分享 為什麽 輸入 all min top 貪吃蛇遊戲已經告一段落了,在完成這個遊戲的過程中,我遭遇了許多“坎坷”和“挫折”,下面就幾個讓我印象深刻的“挫折”做一個具體的講解,以此來為這個貪吃蛇項目畫上一個完整句號。(包括打包這個遊戲時遇到的問題及解決
機器學習中的幾個概念的關系
概念 clas ear into deep 大數據 多倫多 有監督 hmm 目前, 機器學習主要由以下三條主線進行發展: graph LR subgraph 三代神經網絡 A[1 線性分類器] ==> B[2 非線性分類器] B ==SVM==> C[3 深度學
[JavaScript]記錄完成輪播過程中的幾個點
計算 arm class 問題: 動作 hid 需要 asc scrip 記錄幾個坑 之前的輪播: 完整代碼:GitHub 效果預覽:GitHub 最近完成的輪播: 完整代碼:GitHub 效果預覽:GitHub 在完成輪播中解決兩個問題: 1.setInterval()會
xorm中的幾個坑
專案中使用的是xorm,雖然用了很順手了,可是還是會遇到一些坑,這裡紀錄一些。 結構體自動忽略空欄位 在xorm中,結構體會自動忽略空欄位(或則說預設值,比如int 的0 ,string的""),這個時候,怎麼解決呢? 把結構體中的欄位,提到where語句的條件中,比如: orm.Get(&Us
Android SurfaceView+MediaPlayer實現幾個不同的視訊輪流播放
MediaPlayer 1)如何獲得MediaPlayer例項: 可以使用直接new的方式: MediaPlayer mp = new MediaPlayer(); 也可以使用create的方式,如: MediaPlayer mp = MediaPlayer.create(t