
MySQL檢視 索引 儲存過程 觸發器 函式
檢視: 也就是一個虛擬表(不是真實存在的),它的本質就是根據SQL語句獲取動態的資料集,併為其命名。使用者使用時只需要使用命名的檢視即可獲取結果集,並可以當做表來使用。它的作用就是方便查詢操作,減少複雜的SQL語句,增強可讀性,更加安全。
①建立檢視
-- 建立檢視 -- 格式 create view 檢視名稱 as SQL語句 create view user_view as select name,age,gender from userinfo
userinfo的表:
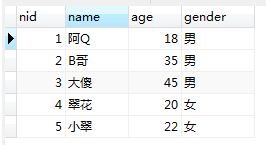
生成的檢視user_view:
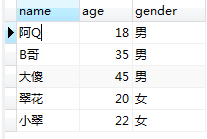
②刪除檢視:
格式:drop view 檢視名稱
drop view user_view
③修改檢視:
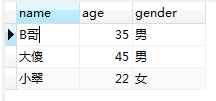
-- 修改檢視 -- 格式 alter view 檢視名稱 as SQL語句 alter view user_view as select name,age,gender from userinfo where age > 20
修改後的檢視user_view:
索引:是表的目錄,在查詢內容之前可以先在目錄中查詢索引位置,以此快速定位查詢資料,對於索引,會儲存在額外的檔案中。是專門用於幫助使用者快速查詢資料的一種資料結構,類似於字典中的目錄,查詢字典內容時可以根據目錄查詢到資料庫的存放位置,然後直接獲取即可
①特點
a:由資料庫中一列或多列組合而成,作用就是提高對錶中資料的查詢速度
b:建立和維護索引需要耗費時間,會減慢寫入速度
②索引分類
a:普通索引--僅加速查詢,資料列可以重複,不做約束
b:唯一索引--加速查詢,約束列資料不能重複,可以有null
c:主鍵索引--加速查詢,約束列資料不能重複,不能為null
d:組合索引--多列可以建立一個索引檔案,聯合唯一,加速查詢,約束列資料不能重複,不能為null
e:全文索引--對文字的內容進行分詞,進行搜尋
③建立索引
-- 建立索引 -- 格式 -- 建立表的時候建立 CREATE TABLE tb_name )( 欄位名稱 欄位型別 [ 完整性約束條件 ], [ UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [ 索引名稱 ] (欄位名稱 [(長度) ]) [ ASC | DESC ] ); -- 已存在表建立 1,CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名稱 ON 表名{欄位名稱[(長度)] [ASC|DESC]} 2,ALTER TABLE tb_name ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名稱(欄位名稱[(長度)] [ASC|DESC]); -- 刪除索引 DROP INDEX 索引名稱 ON tb_name
觸發器:是一種特殊的儲存過程,它在插入,刪除或修改特定表中的資料時觸發執行,比資料庫本身標準功能有更精細更復雜的資料控制能力。
④普通索引
-- 普通索引 create table tb1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name(name) ) -- 檢視索引 show index from tb1
⑤唯一索引
-- 建立唯一索引 create table tb1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, unique ix_name (name) )
⑥主鍵索引
create table tb1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name (name) )
儲存過程:簡單地說就是一組SQL語句集,功能強大,可以實現一些比較複雜的邏輯功能。
①優點:
a:通過把處理封裝在容易使用的單元中,簡化複雜操作
b:由於不要求反覆建立一些列處理步驟,這保證了資料的完整性,如果開發人員和應用程式都使用同一儲存過程,則所使用的程式碼是相同的。還有 就是防止錯誤,需要執行的步驟越多,出錯的可能性越大。防止錯誤保證了資料的一致性。
c:簡化對變動的管理,如果表名,列名或業務邏輯有變化,只需要更改儲存過程的程式碼,使用它的人員不會改自己的程式碼了
d:提高效能,因為使用儲存過程比使用單條語句要快
e:存在一些職能用在單個請求的MySql元素和特性,儲存過程可以使用它們來編寫功能更強更靈活的程式碼
總結起來就是:簡單,安全,高效能
②缺點:
a:不同的資料庫,語法差別大,移植困難,換了資料庫,需要重寫編寫
b:不好管理,把過多的業務邏輯寫在儲存過程不好維護,不利於分層管理,容易混亂,一般儲存過程適用於個別對效能要求較高的業務
③創
-- 建立 -- 如果儲存過程存在,則先刪除 drop procedure if exists p1; -- delimiter 替換預設的輸入結束符 delimiter // -- procedure create procedure p1() begin select * from course; end// delimiter ; -- 通過call來執行 call p1()
對於儲存過程,可以接收三個引數:
in:僅用於傳入引數用
out:僅用於返回值用
inout:既可以傳入又可以當做返回值
drop procedure if exists p1; delimiter // create procedure p1( in i1 int, in i2 int, inout i3 int, out r1 int ) begin declare temp1 int; declare temp2 int default 0; set temp1 = 1; set r1 = i1 + i2 + temp1 + temp2; set i3 = i3 + 100; end// delimiter ; -- 執行過程 -- @表示變數 set @t1 = 4; set @t2 = 0; call p1(1,2,@t1,@t2); -- 返回值就是inout 和 out對應的結果 select @t1,@t2;
注:儲存過程的作用就是獲取兩類資料--普通值和結果集,它可以執行多個sql語句,結果集只能是一個,也就是說,在儲存過程中,如果有多個select只會拿一個
觸發器:是一種特殊的儲存過程,它在插入,刪除或修改特定表中的資料時觸發執行,比資料庫本身標準功能有更精細更復雜的資料控制能力。
函式:http://www.cnblogs.com/kissdodog/p/4168721.html
自定義函式:
-- 自定義函式 drop function if exists f1; delimiter \\ create function f1( i1 int, i2 int ) returns int begin declare num int; set num = i1 + i2; return(num); end; \\ delimiter; -- 在查詢中使用 select f1(11,nid) as "result",name from tb;
與儲存過程的區別:不能獲取結果集,不允許寫sql語句,通過returns返回,而儲存過程可以寫sql語句,通過out或inout返回