
列資料庫與行資料庫對比以及應用範圍
阿新 • • 發佈:2018-12-25
1)Relative Database Management System
2)Non-Relative Database Management System
而從物理(儲存的)視角來看,則可以分為:
1)Row Based Storage DBMS
2)Column Based Storage DBMS
當然, 無論無論是邏輯視角還是物理視角, 它們都是不衝突的, 比如我們可以將邏輯上的RDBMS和物理上的Row Based Storage DBMS相結合, 那就成為我們平常使用最多的一種資料庫產品型別,比如
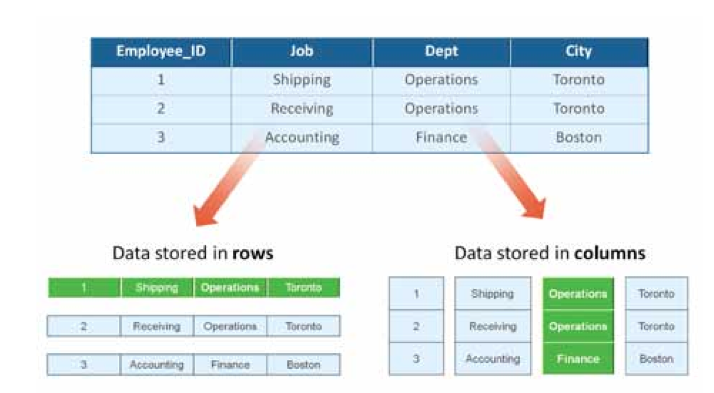
上圖是摘錄自infobright的一份文件, 該圖形象的描述了物理上兩種不同的儲存方式與關係型表之間的關係。可以看到,在通常的基於行儲存的RDBMS中, 資料是按照行資料為基礎單元進行儲存的, 而在基於列式的DBMS中, 資料則是按照一列一列的資料為單元進行儲存, 那麼,
1)這兩種不同的儲存方式會造就什麼樣的差異那?
2)為什麼通常認為基於行儲存的RDBMS更適合OLTP型別的應用場景, 而基於列式的RDBMS則更適合OLAP型別的應用場景那?
不妨讓我們來簡單分析一下…
1 - 基於行儲存的RDBMS行為分析
因為資料在這種型別的RDBMS中是按照行儲存的,那麼資料在寫入的時候可以按照一行一行順序寫入,對於磁碟來講, 這種行為與其物理結構造就的行為是比較契合的。在OLTP型別的應用中, 這種行為是合適的, 雖然基於行的儲存在資料讀取的時候會存在一定的“缺陷”(很多時候, 並非每一行中每一列的值都需要讀取出來),但在OLTP型別的應用中, 通過索引啦之類的機制,可以基本搞定。
所以, 不嚴謹點兒講, “基於行儲存的RDBMS適合OLTP型別的應用場景”這句話還算恰當。
|
2 - 基於列式的RDBMS行為分析 在基於列式的RDBMS中, 資料現在是按照一列一列為單元進行儲存的,那麼要進行一行一行的資料寫入的時候, 可能就需要“跳躍式”的將每一行每一列的值寫入到不同的區塊,顯然,對於磁碟結構來說,這中儲存方式對資料的寫入是不夠友好的,效能指定好不到哪兒去(當然,是與基於行儲存的DBMS相比)。但是,反過來看, 對資料寫入的支援或許不好,那對資料的讀取那?很簡單就可以看出來,如果我每次都對一列,一列的資料感興趣,我完全可以快速的讀取每一列的所有值,那麼, 這種特性對讀取的列上所有的值進行統計分析就比較讚了。至於說“基於列式的RDBMS則更適合OLAP型別的應用場景”, 我們不妨以資料倉庫這種特定場景為基礎進行一簡單的“分析”(CRM之類也可以)。 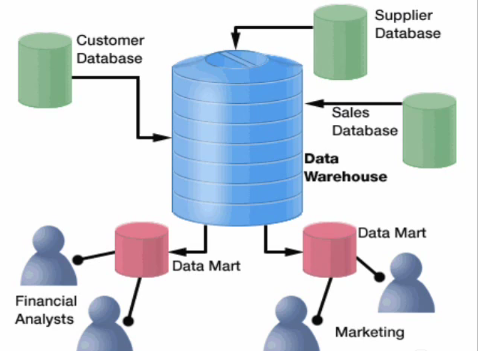 |
DW會將各個資料來源彙總過來的資料做抽取,清洗,轉換, 載入之類的工作,然後放入Star Schema或者Snowflake Schema建模的新儲存模型中,然後供後端的其它分層和應用使用,此後,大多數操作型別都將是資料讀取型別。
|