
Source-Selection-Free Transfer Learning 源域自動選擇
論文地址:https://www.ijcai.org/Proceedings/11/Papers/392.pdf
簡介
當訓練集中帶標籤資料很少,無法訓練出一個較好的分類模型時,我們就會希望通過遷移學習能夠從其他的輔助域中遷移出有利於目標任務的知識來輔助建立目標分類器,現有的大多數遷移學習方法都是手動的選擇一個或者多個輔助域來進行遷移,那如果有一種遷移學習方法能夠自動選擇出這些輔助域是一件多棒的事情!有了這個能力,就可以將網路這一片資料海洋的資源利用起來了,想想,網路自動選擇使用那些資料,並且資料來源可以來自於網路,這是不是可以越來越接近黑客帝國中的智慧中心了,無盡的資料,通過自動遷移篩選,可以完成各種任務,cool!這就是Source-Selection-Free Transfer Learning(SSFTL)想要完成的目標,儘管SSFTL不能做到我們想象的那一步,但是確實是邁出了一小步。
在該方法中,應用場景是文字識別,其中並不需要使用者給出特定的源域資料集用來進行目標分類任務,因為輔助域資料可以從網路上獲取。作者假設網路上的資訊源和目標任務擁有相同的特徵空間(使用的字典相同),但是標籤域可能不同( ),甚至是互斥的。然後為了幫助在 和 之間進行橋接,這裡假設有一個社交媒體集合,這些社交媒體通過標記 打上標籤,以至於 與 是重疊的,同時, 又是 的一個子集。SSFTL的目標就是在 和 進行橋接,然後從源域中選出一個子集用來作為遷移資料,將知識遷移到目標任務。
為了在 和 建立一作有效的橋,作者使用圖形表示將所有標籤嵌入到潛在的歐幾里德空間中,然後標籤之間的關係就可以使用這個潛在空間中對應的標籤原型(被對映後的標籤)之間的距離進行表示。將每個源分類器的標籤預測結果也對映到潛在空間中,這樣也可以通過這之間的距離可以抉擇出那些源域資料是與目標標籤(目標任務)是有利的。最後,再通過一個正則化框架來學習一個有效的分類器來對目標文字進行分類。這稍微有點繞,我們看下面的詳細內容吧。
Source-Selection-Free Transfer Learning
像上面所說,假設我們有少量的帶標籤目標資料 以及豐富的無標籤資料 。在輔助域中,有k個精光預訓練的分類器{ }。輔助域和源域有著相同的特徵空間(使用相同的字典)。另外,假設有一些社交媒體集合,例如Delicious,它包含了很多標記 , 覆蓋了所有目標域和源域中的標籤( and ),SSFTL的目標是通過利用這些輔助分類器以及社交媒體資料來訓練一個目標分類器。
SSFTL需要解決兩個問題:
- 在輔助域和目標域的標籤之間進行橋接
- 使用經過預訓練的源域分類器學習到的源域與目標域之間的關係訓練一個目標分類器
第一步,利用社交標記資料,構建一個標籤圖,然後通過圖形嵌入來學習標籤的潛在低維空間。第二步,通過一個正則化框架傳遞源分類器中編碼的知識。
構建標籤嵌入圖
為了利用社交媒體資料中的潛在圖框架,作者在圖上應用了圖譜技術[Chung,1997]將圖中的每個點對映到了一個低維潛在空間。通過這樣,每個標籤將在這個潛在空間上有一個座標,稱這個座標為該類的"原型(Prototype)"。因為這樣一個潛在空間的維度比起原特徵空間來說可能太低了,由標籤稀疏性導致的誤匹配問題可能會減輕。然後各類別之間的關係,比如相似或者不相似,可以通過在潛在空間中他們對應的原型之間的距離進行表示。
那麼就是需要獲得一個潛在特徵空間表示矩陣,這個潛在特徵空間表示矩陣怎麼獲取呢?作者使用了Laplacian Eigenmap[Belkin and Niyogi,2003]來構建這個矩陣V。給出標籤圖 以及它的權重或者鄰接矩陣M,Laplacian Eigenmap 旨在通過解決以下的優化問題來學習V,然後這個V就是我們的標籤嵌入圖:
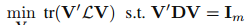
其中D是一個對角矩陣,然後 是拉普拉斯矩陣[Belkin and Niyogi,2003]。 則是一個m維的單位陣。注意到如果兩個標籤原型之間的距離越小,那麼也就表示這兩個標籤在語義上也是相似的。因此,基於潛在空間中標籤原型的距離,我們就可以在域間進行知識遷移。
知識遷移(用於自動選擇源域的正則化框架)
在目標分類任務中,目標是學習一個分類器 ,在文中g(x)是一個線性模型,可以被寫為 。
因為目標域中有標籤的資料較少,因此我們需要通過所有輔助域分類器的結合來幫助目標分類器在無標籤資料上做預測:
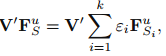
其中 是輔助域分類器在目標域無標籤資料 上的預測結果,然後 表示為這些輔助域分類器的權重。
在潛在空間中,目標域標籤原型也許會被輔助域標籤原型包圍或者分離,這意味著輔助域分類器也許會對目標分類器g(x)有幫助。因此,通過結合經過對映後的輔助域分類器,可以用於正則化在無標籤資料上的目標分類器,如下:

其中 為無標籤資料矩陣。
最後獲得以下優化問題:
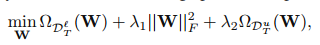
其中:
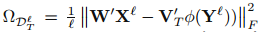
這是一個在有標籤矩陣上的損失函式,然後 就是對應的標籤矩陣。然後 是一個正則化項用於避免過擬合。然後從輔助域中遷移的知識被編碼在 裡面,源域和目標域標籤之間的關係則被編碼在V裡面。
好了,通過以上的優化,就可以訓練處目標分類器g(x)對目標資料進行分類了。
總結

SSFTL對源域中每個類預訓練一個分類器—>通過網上的社交媒體標記資料 構建一個標籤圖—>將源域和目標標籤對映到該圖空間中—>計算標籤之間的距離代表標籤之間的關係—>通過這些關係(使用 衡量)將源域分類器結合來幫助優化目標分類器g(x)。
SSFTL實現了通過網路資料來輔助目標分類器對目標任務進行分類,其源域為網路資料,同時使用了一個覆蓋了源域和目標域所有標籤的線上社交媒體資料Delicious來構建嵌入圖以衡量標籤之間的關係,這樣就可以選出與目標域標籤類似的源域標籤,進而可以選出那些與目標域資料相似的源域資料,通過這樣優化以訓練目標分類器。但是該方法也許具有一定的侷限性,比如特徵空間相同、