
12C環境下分庫分表改造查詢優化
某交易查詢庫主要使用Oracle 12.1.0.2.0的In Memory特性快取三張按月分割槽的大表,In Memory元件主要是針對OLAP應用的,而這種應用絕大部分的操作都是查詢,而且很多時候只關心表中特定的一個或多個列,所以in memory特性還可以指定只把表中的特定的一個或多個列載入到in memory area當中。開始的情況由於併發等多種因素,跑的還是很快的。隨著時間的推移,三個表的資料量越來越大,所佔用記憶體資源也越來越多。總是出現這樣那樣的問題。如今年上半年該系統的一次故障。
SQL> r
1 select wait_class_id,wait_class,count() cnt
2 from dba_hist_active_sess_history
3 where snap_id between 12073 and 12074
4 group by wait_class_id,wait_class
5
WAIT_CLASS_ID WAIT_CLASS CNT
1740759767 User I/O 12472
2363
3386400367 Commit 2301
1893977003 Other 1093
3875070507 Concurrency 132
4217450380 Application 67
4108307767 System I/O 21
3290255840 Configuration 1
8 rows selected.
查詢對應的IO情況所反應到資料庫中的事件是什麼
EVENT_ID EVENT CNT
3056446529 read by other session 6149
834992820 db file parallel read 4756
2652584166 db file sequential read 1418
3926164927 direct path read 993
506183215 db file scattered read 56
根據其等待時間,檢視對應的SQL文字為:
SELECT
FROM (SELECT tmp_page., rownum row_id
FROM (SELECT t.TRAN_UUID,
t.IN_MNO,
t.EX_MNO merchantCode,
t.CARD_TYP,
t.CARD_DISP_NO,
t.TRAN_RESPONSE_CD,
t.TRAN_CD,
t.TRAN_STS,
t.TRAN_SEQ_NO,
t.TRAN_BAT_NO,
to_char(t.TRAN_DATE_TIME, 'YYYYMMDD') AS TRAN_DT,
to_char(t.TRAN_DATE_TIME, 'HH24MISS') AS TRAN_TM,
t.TRAN_IN_MOD payWay,
t.TERMINAL_NUM,
t.POS_SIGN_FLG,
t.TRAN_AMT,
t.RECEIVER_FEE_AMT,
t.TRAN_FLG,
t.ROOT_XXXX_ORG_NM belongtoOrgNm,
t.BUSINESS_EMP_NM empNm,
t.XXXX_ORG_NM directlyOrg,
t.XXXX_ORG_NO,
t.XXXX_ORG_PATH
FROM T_SSP_TRANDATA_MPOS t
WHERE t.TRAN_DATE BETWEEN TO_DATE(:1, 'yyyyMMdd') AND
TO_DATE(:2, 'yyyyMMdd')
AND t.ROOT_XXXX_ORG_NO = :3
AND t.XXXX_ORG_PATH LIKE :4 || '%'
ORDER BY t.TRAN_DATE_TIME DESC) tmp_page
WHERE rownum < = :5)
WHERE row_id > :6;
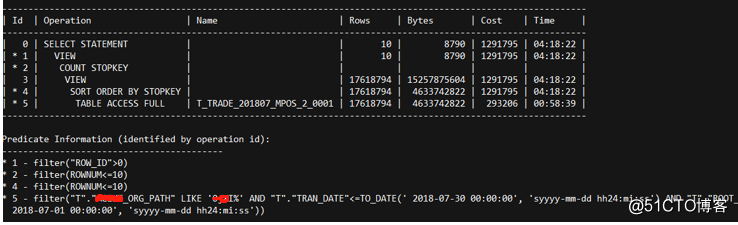
執行計劃類似如下:

使用AWR對比相同時間不同日期時間段,檢視該SQL在前一天單次執行時間為1,168毫秒,約0.01分。執行頻率為171,故障時間段單次執行時間為102,929毫秒,約1.71分。執行的頻率為248。故障時間段要比平時多執行77次。多出131.67分。
推測故障時間段明顯比前一天的執行頻率要高。是否存在前臺的使用者點選某個按鈕,等了半天沒響應,然後就一直點,導致這個SQL一直重複的執行。
IO資源幾乎耗盡,會話a在進行把磁碟上的資料塊讀到記憶體,會話b,會話c 同時也請求這個資料塊。就導致了b、c read by other session。
direct path read表小的時候將資料讀到快取中,表不斷增大後,oracle演算法干預在大於2%的cache後會採用直接路勁讀的方式,跳過載入快取。大量的反覆讀取磁碟IO會將IO耗盡,決定設定10949事件關閉該特性。
要使用IN MEMORY特性,需要設定parallel_degree_policy=AUTO和parallel_force_local=false,才能夠真正意義上的啟動IM特性,不然只是執行計劃中的啟用,是假象。
後將parallel_degree_policy改為AUTO。後又重新載入T_SSP_TRANDATA_MPOS表全部進入in memory。這麼一折騰後,系統穩定了一段時間,可後期還有這樣那樣的問題。
在程式碼不改動的情況下,開發和架構部同事進行了拆表分庫的方案。三個大表廢棄一張表,另外兩個表拆分成為4個表,並按月又進行了拆分,一個月有四個小表。新庫遷移完成,投產當晚,進行資料校驗的同時發現該查詢功能還是跑不出結果該SQL單次執行時間150S以
上,改造這麼久無法交差啊。
著手檢視SQL,進行SQL優化。
SELECT
FROM (SELECT tmp_page., rownum row_id
FROM (SELECT to_char(TRAN_DATE_TIME, 'yyyyMMdd HH24:mm:ss'),
t.TRAN_UUID,
t.IN_MNO,
t.EX_MNO merchantCode,
t.CARD_TYP,
t.CARD_DISP_NO,
t.TRAN_RESPONSE_CD,
t.TRAN_CD,
t.TRAN_STS,
t.TRAN_SEQ_NO,
t.TRAN_BAT_NO,
to_char(t.TRAN_DATE_TIME, 'YYYYMMDD') AS TRAN_DT,
to_char(t.TRAN_DATE_TIME, 'HH24MISS') AS TRAN_TM,
t.TRAN_IN_MOD payWay,
t.TERMINAL_NUM,
t.POS_SIGN_FLG,
t.TRAN_AMT,
t.RECEIVER_FEE_AMT,
t.TRAN_FLG,
t.XXXX_ORG_NO,
t.XXXX_ORG_PATH
FROM T_TRADE_201807_MPOS_2_0001 t
WHERE t.TRAN_DATE BETWEEN TO_DATE('20180701', 'yyyyMMdd') AND
TO_DATE('20180730', 'yyyyMMdd')
AND t.ROOT_XXXX_ORG_NO = '6AAAAAAAAA'
AND t.XXXX_ORG_PATH LIKE '0FDAFDS%'
ORDER BY t.TRAN_DATE_TIME DESC) tmp_page
WHERE rownum < = 10)
WHERE row_id > 0;
如下是執行計劃:
該表索引情況:
OWNER INDEX_NAME COLUMN_NAME
XXXX IDX_1807_MPOS_21_XXXX_ORG_NO XXXX_ORG_NO
XXXX IDX_1807_MPOS_21_IN_MNO IN_MNO
XXXX IDX_1807_MPOS_21_ROOT_XXXX_N ROOT_XXXX_ORG_NO
XXXX IDX_1807_MPOS_21_TRAN_DT TRAN_DATE
XXXX IDX_1807_MPOS_21_TRAN_TM TRAN_DATE_TIME
XXXX PK_T_SSP_1807_MPOS_21 TRAN_UUID
XXXX PK_T_SSP_1807_MPOS_21 TRAN_DATE
我們都知道建立索引需要檢視該表的基數情況,根據基數與總行數的比值我們就能知道該表某個列的選擇性。
該7月表的總行數18228172條,ROOT_XXXX_ORG_NO列的基數為1,說明都是重複值該列。
而這個ROOT_XXXX_ORG_NO索引的選擇性太低了。絕對是不推薦建立索引的!當一個表中的列選擇性大於20%的時候,說明該列資料分佈比較均衡。且出現在where條件中,該列沒有建立索引,那麼該列就必須建立索引。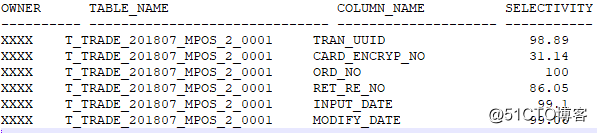
不想多說什麼了,既然開發部門的同事在領導面前無法交差,我們試著看看有沒有優化的餘地。
首先收集一下該表的統計資訊,以及做一下動態取樣。執行時間縮短不少。
明確一下分頁語句一定排序,要不然每次返回結果都不一樣。業務邏輯不嚴謹的話還行。
這裡需要看where條件後面的欄位了。
當where條件是等值,oder by其他列,那麼where條件的列在前,其他列在後。
當where條件不等值,order by其他列,那麼建立索引就不一定怎麼建了,關鍵看過濾的資料多不多!!!
基於以上考慮情況,建立如下索引:
create index xxx.IDX_1807_MPOS_21_NO_PA on xxx.T_TRADE_201807_MPOS_2_0001 ("TRAN_DATE_TIME","ROOT_xxxx_ORG_NO","xxxx_ORG_PATH") tablespace XXX_IDX online nologging;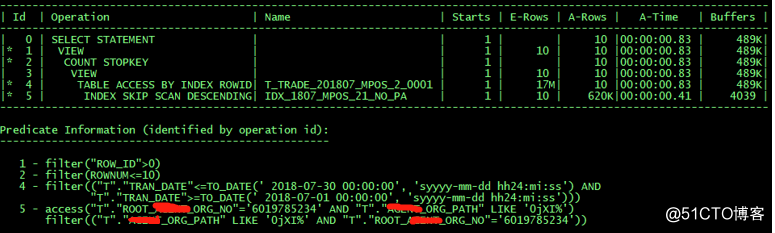
結果秒出,開發部門的同事可以交差了。
通過我們的監控系統也能感受到此次的優化情況,如CPU利用率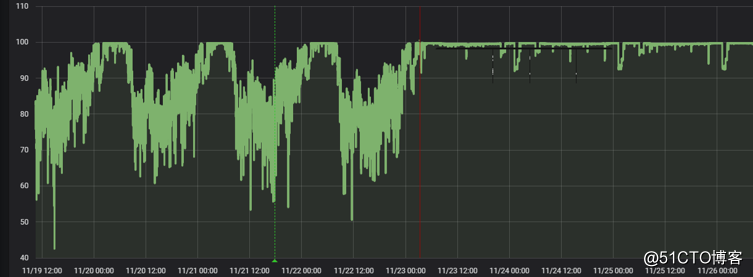
記憶體使用率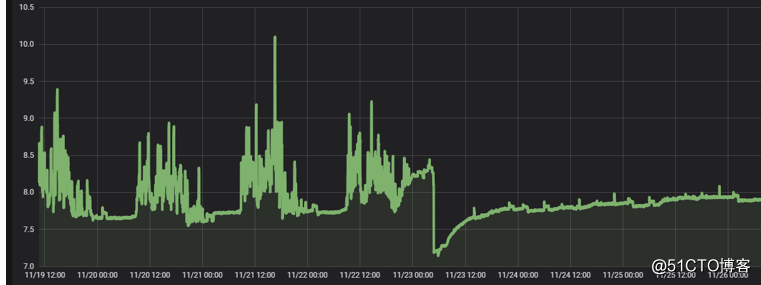
DBtime監控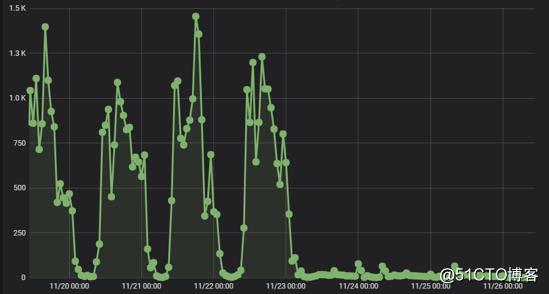
由原來的各種突起峰值,到現在的平穩執行。
這裡有幾個疑問,這樣的索引跳掃是否有問題?返回的行數為什麼不是10行?歡迎大家積極討論。
總得留點懸念吧