
REDIS快取叢集介紹
本次介紹redis快取叢集,目前是為了解決session共享的問題(這裡只說如何配置叢集),當然它可以解決更麻煩的問題,只是目前還用不到。redis快取叢集是比較實用的技能,佈置方式要根據自己的實際需求來判斷。使用過程最重要的是如何解決快取帶來的問題,今天介紹的主要是如何使用官方推薦的方式去實現叢集。例子是在單臺伺服器上跑的,有什麼錯誤的地方希望大家多多指正。
安裝步驟可以看之前寫的,可能有點亂:REDIS叢集配置(LINUX)
視訊(講的時候忘錄了,後來補錄的,醉了):
目錄:
正文
1.背景介紹
Redis
Redis 是一個開源(BSD許可)的,記憶體中的資料結構儲存系統,通俗的來講就是基於記憶體的高效能K/V資料庫。
Redis 作為一個key—value儲存系統。支援儲存的value型別相對更多,包括string(字串)、list(連結串列)、set(集合)、zset(sorted set --有序集合)和hash(雜湊雜湊)。
-
Redis的核心是用標準ANSI C寫成的,基於一種事件模型;
-
高速,資料存在記憶體中,在記憶體中進行操作;
-
持久化,可以非同步儲存資料到硬碟中,在宕機恢復後迅速解決資料丟失的問題;
-
分散式 讀寫分離模式;
-
單執行緒,利用redis佇列技術並將訪問變為序列訪問,消除了傳統資料庫序列控制的開銷;
-
屬於NoSql,支援事務,操作都是原子性;
-
可用作cache,訊息匯流排,或者在某些開發專案中作為結構不復雜的資料庫來使用
redis的效能如何?
- 每秒可以處理超過10萬次讀寫操作
- 機械硬碟的讀寫速度:50-90MB/s,
- 固態硬碟的讀寫速度可以達到:500MB/s,
- 記憶體DDR3 1333Hz的讀寫速度大概在8G/s,
新浪微博架構師楊衛華(11年)曾說過:“國內前十大網站的子產品估計用1臺Redis就可以滿足儲存及Cache的需求”。
2.知識剖析
叢集(CLUSTER)
叢集是一組相互獨立的、通過高速網路互相聯通的節點,構成了一個組,並以單一系統的模式加以管理。一個客戶與叢集相互作用時,叢集就是一個獨立的伺服器。
叢集技術是一種通用的技術,其目的是為了解決單機運算能力的不足、IO能力的不足、提高服務的可靠性、獲得規模可擴充套件能力,降低整體方案的運維成本(執行、升級、維護成本)。能在大流量訪問下提供穩定的業務,叢集化是儲存的必然形態。
- 提高效能
- 降低成本
- 提高可擴充套件性
- 增強可靠性
Redis叢集(redis-cluster)
Redis 叢集是一個提供在多個Redis節點之間共享資料的程式集。
Redis 叢集並不支援同時處理多個鍵的 Redis 命令,因為這需要在多個節點間移動資料,這樣會降低redis叢集的效能,在高負載的情況下可能會導致不可預料的錯誤。
Redis 叢集通過分割槽來提供一定程度的可用性,即使叢集中有一部分節點失效或者無法進行通訊, 叢集也可以繼續處理命令請求。
Redis 叢集的優勢:
1.快取永不宕機:啟動叢集,永遠讓叢集的一部分起作用。主節點失效了子節點能迅速改變角色成為主節點,整個叢集的部分節點失敗或者不可達的情況下能夠繼續處理命令;
2.迅速恢復資料:持久化資料,能在宕機後迅速解決資料丟失的問題;
3.Redis可以使用所有機器的記憶體,變相擴充套件效能;
4.使Redis的計算能力通過簡單地增加伺服器得到成倍提升,Redis的網路頻寬也會隨著計算機和網絡卡的增加而成倍增長;
5.Redis叢集沒有中心節點,不會因為某個節點成為整個叢集的效能瓶頸;
6.非同步處理資料,實現快速讀寫。
Redis 叢集的資料分片
Redis 叢集沒有使用一致性hash,而是引入了雜湊槽的概念。
Redis 叢集內建了16384個雜湊槽,每個key通過CRC16校驗後對16384取模來決定放置哪個槽。叢集的每個節點負責一部分hash槽,舉個例子,比如當前叢集有3個節點,那麼:
節點 A 包含 0 到 5500號雜湊槽.
節點 B 包含5501 到 11000 號雜湊槽.
節點 C 包含11001 到 16384號雜湊槽.
這種結構很容易新增或者刪除節點.
比如如果我想新添加個節點D,我需要從節點 A, B, C中得部分槽到D上.
如果我想移除節點A,需要將A中的槽移到B和C節點上,然後將沒有任何槽的A節點從叢集中移除即可.
由於從一個節點將雜湊槽移動到另一個節點並不會停止服務,所以無論新增刪除或者改變某個節點的雜湊槽的數量都不會造成叢集不可用的狀態.
Redis 叢集的主從複製模型
為了使在部分節點失敗或者大部分節點無法通訊的情況下叢集仍然可用,所以叢集使用了主從複製模型,每個節點都會有N-1個複製品.
比如之前的例子有A,B,C三個節點的叢集,在沒有複製模型的情況下,如果節點B失敗了,那麼整個叢集就會以為缺少5501-11000這個範圍的槽而不可用.
然而如果在叢集建立的時候(或者過一段時間)我們為每個節點新增一個從節點A1,B1,C1,那麼整個叢集便有三個master節點和三個slave節點組成,這樣在節點B失敗後,叢集便會選舉B1為新的主節點繼續服務,整個叢集便不會因為槽找不到而不可用了。不過當B和B1 都失敗後,叢集就不可用了。
主從複製的一些特點
1)採用非同步複製;
2)一個主redis可以含有多個從redis;
3)每個從redis可以接收來自其他從redis伺服器的連線;
4)主從複製對於主redis伺服器來說是非阻塞的,這意味著當從伺服器在進行主從複製同步過程中,主redis仍然可以處理外界的訪問請求;
5)主從複製對於從redis伺服器來說也是非阻塞的,這意味著,即使從redis在進行主從複製過程中也可以接受外界的查詢請求,只不過這時候從redis返回的是以前老的資料,如果你不想這樣,那麼在啟動redis時,可以在配置檔案中進行設定,那麼從redis在複製同步過程中來自外界的查詢請求都會返回錯誤給客戶端;
(雖然說主從複製過程中對於從redis是非阻塞的,但是當從redis從主redis同步過來最新的資料後還需要將新資料載入到記憶體中,在載入到記憶體的過程中是阻塞的,在這段時間內的請求將會被阻,但是即使對於大資料集,載入到記憶體的時間也是比較多的);
6)主從複製提高了redis服務的擴充套件性,避免單個redis伺服器的讀寫訪問壓力過大的問題,同時也可以給為資料備份及冗餘提供一種解決方案;
7)為了編碼主redis伺服器寫磁碟壓力帶來的開銷,可以配置讓主redis不在將資料持久化到磁碟,而是通過連線讓一個配置的從redis伺服器及時的將相關資料持久化到磁碟,不過這樣會存在一個問題,就是主redis伺服器一旦重啟,因為主redis伺服器資料為空,這時候通過主從同步可能導致從redis伺服器上的資料也被清空;
3.常見問題
叢集節點的操作方式:
-
叢集重新分片
./redis-trib.rb reshard 127.0.0.1:7000 -
新增一個新節點
./redis-trib.rb add-node 127.0.0.1:7006 -
新增一個從節點
./redis-trib.rb add-node --slave 127.0.0.1:7006 -
移除一個節點(如果是主節點要確保這個主節點是空的)
./redis-trib del-node 127.0.0.1:7000 <\node-id> -
遷移從節點
CLUSTER REPLICATE <\master-node-id> -
停止節點
./redis1/redis-cli -p 7001 shutdown -
叢集方式登入
./redis-cli -c -h -p 如:./redis-cli -p 7003 -c 預設情況下不能從slaves讀取資料,但建立連線後,執行一次命令READONLY,該slaves即可讀取資料。
Redis 持久化
redis提供了不同級別的持久化方式,一種是RDB,一種AOF。
可以同時開啟兩種持久化方式, 在這種情況下,當redis重啟的時候會優先載入AOF檔案來恢復原始的資料,因為在通常情況下AOF檔案儲存的資料集要比RDB檔案儲存的資料集要完整.
–
RDB:在指定的時間間隔能對資料進行快照儲存(就是隔一段時間把記憶體裡的資料轉存到硬碟等介質上)
–
AOF:每次對伺服器寫的操作指令記錄下來,當伺服器重啟的時候會重新執行這些命令來恢復原始的資料,AOF命令以redis協議追加儲存每次寫的操作到檔案末尾.Redis還能對AOF檔案進行後臺重寫,使得AOF檔案的體積不至於過大.
4.編碼實戰
Redis叢集實現方式
*參考頁首配置步驟
1.建立不同的redis節點,在需要的地方執行redis例項,每個redis例項有單獨的ip或埠,並且配置啟用叢集管理;
2.建立redis-trib的執行環境:安裝ruby,redis.gem
3.通過使用Redis叢集命令工具redis-trib建立叢集;
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002
–replicas 1 表示 自動為每一個master節點分配一個slave節點,上面有6個節點,程式會按照一定規則生成3個master(主)3個slave(從)
redis.conf 叢集的基礎配置
繫結ip(這裡是本地配置,其他伺服器配置對應的ip)
bind 127.0.0.1
埠
port 6379
後臺守護啟動
daemonize yes
開啟aof模式
appendonly yes
開啟叢集管理
cluster-enabled yes
節點響應超時時間 如果超過這個響應時間就會認定節點不可用
cluster-node-timeout 5000
5.擴充套件思考
Redis 一致性保證
Redis 並不能保證資料的強一致性. 這意味這在實際中叢集在特定的條件下可能會丟失寫操作.
- 第一個原因是因為叢集是用了非同步複製和寫入的操作過程:
客戶端向主節點B寫入一條命令;
主節點B向客戶端回覆命令狀態;
主節點將寫入操作複製給他的從節點 B1, B2 和 B3;
這時候主節點對命令的複製工作發生在返回命令回覆之後, 因為如果每次處理命令請求都需要等待複製操作完成的話, 那主節點處理命令請求的速度將極大地降低 —— 我們必須在效能和一致性之間做出權衡。
注意:Redis 叢集可能會在將來提供同步寫的方法。
- 另外一種可能會丟失命令的情況是叢集出現了網路分割槽, 並且一個客戶端與至少包括一個主節點在內的少數例項被孤立。
舉個例子 假設叢集包含 A 、 B 、 C 、 A1 、 B1 、 C1 六個節點, 其中 A 、B 、C 為主節點, A1 、B1 、C1 為A,B,C的從節點, 還有一個客戶端 Z1 假設叢集中發生網路分割槽,那麼叢集可能會分為兩方,大部分的一方包含節點 A 、C 、A1 、B1 和 C1 ,小部分的一方則包含節點 B 和客戶端 Z1 . Z1仍然能夠向主節點B中寫入, 如果網路分割槽發生時間較短,那麼叢集將會繼續正常運作,如果分割槽的時間足夠讓大部分的一方將B1選舉為新的master,那麼Z1寫入B中得資料便丟失了.
不同方式的redis的叢集化方案
(1)Twitter開發的twemproxy代理方案
(2)豌豆莢開發的codis
(3)redis官方的redis-cluster
(4)客戶端分片
(5)Sentinel哨兵模式
客戶端分割槽
就是在客戶端就已經決定資料會被儲存到哪個redis節點或者從哪個redis節點讀取。大多數客戶端已經實現了客戶端分
區。
代理分割槽
意味著客戶端將請求傳送給代理,然後代理決定去哪個節點寫資料或者讀資料。代理根據分割槽規則決定請求哪些Redis例項,然後根據Redis的響應結果返回給客戶端。redis和memcached的一種代理實現就是Twemproxy
查詢路由(Query routing)
意思是客戶端隨機地請求任意一個redis例項,然後由Redis將請求轉發給正確的Redis節點。Redis Cluster實現了一種混合形式的查詢路由,但並不是直接將請求從一個redis節點轉發到另一個redis節點,而是在客戶端的幫助下直接redirected到正確的redis節點。
持久化資料還是快取?
無論是把Redis當做持久化的資料儲存還是當作一個快取,從分割槽的角度來看是沒有區別的。當把Redis當做一個持久化的儲存(服務)時,一個key必須嚴格地每次被對映到同一個Redis例項。當把Redis當做一個快取(服務)時,即使Redis的其中一個節點不可用而把請求轉給另外一個Redis例項,也不對我們的系統產生什麼影響,我們可用任意的規則更改對映,進而提高系統的高可用(即系統的響應能力)。
一致性雜湊能夠實現當一個key的首選的節點不可用時切換至其他節點。同樣地,如果你增加了一個新節點,立刻就會有新的key被分配至這個新節點。
重要結論如下:
- 如果Redis被當做快取使用,使用一致性雜湊實現動態擴容縮容,也就是說可以動態擴充套件操作節點
- 如果Redis被當做一個持久化儲存使用,必須使用固定的keys-to-nodes對映關係,節點的數量一旦確定不能變化。否則的話(即Redis節點需要動態變化的情況),必須使用可以在執行時進行資料再平衡的一套系統,而當前只有Redis叢集可以做到這樣
6.參考文獻
7.更多討論
D-鄭州-8-韓亞博(744336687) 19:58:36
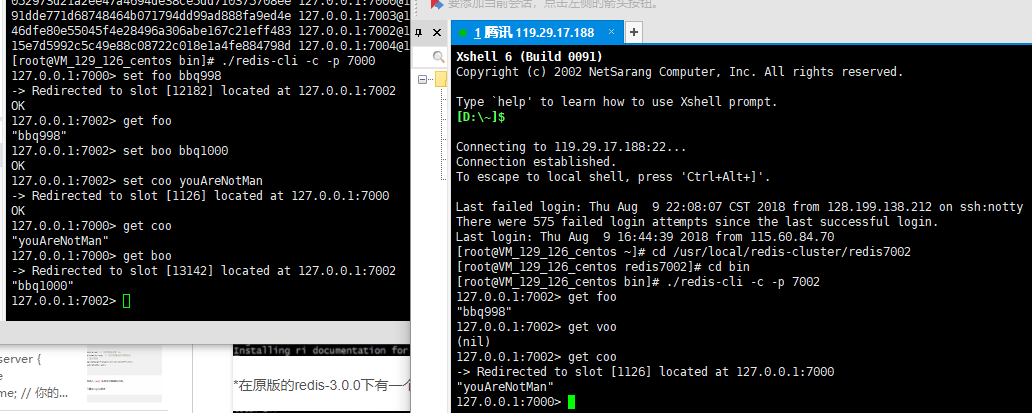
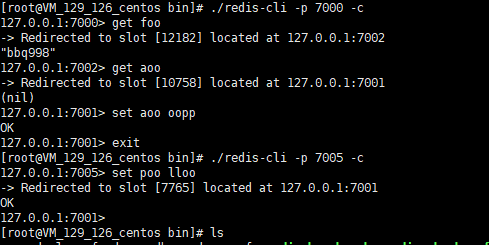
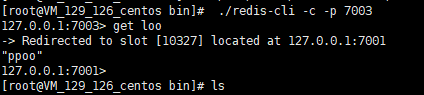
訪問之後節點就跳轉到 健所在的節點了?
Ask:看圖:
埠7005:
埠7003:
B-武漢-14-Java-張鵬(583229382) 19:58:57
多個伺服器是將地址加上去?
- Ask:多個伺服器就是在每個伺服器上的redis節點(例項)先配置好ip和埠啟動,然後在建立的時候寫對應的ip:埠。或者使用add命令新增:
./redis-trib.rb add-node --slave ip:7006
B-武漢-14-Java-張鵬(583229382) 20:07:41
如果中間的地址丟失會影響後面的地址嗎,不同效能的伺服器需要分配權重嗎
- Ask:redis叢集是沒有分配權重這個概念的,它是通過分片來決定哪寫資料存在什麼地方,然後每個節點是平等的,需要拿資料的時候先看這個資料在什麼地方(地址),如果不在本地節點就去其他節點取。
B-武漢-14-Java-張鵬(583229382) 20:09:11
memcached可以叢集嗎?
- Ask:可以的,方式也是有些雷同
在一臺或者多臺機器上啟動多個例項,客戶端配置memcache節點的ip和prot,由客戶端實現分散式快取(這屬於偽叢集);或者使用Magent代理元件搭建叢集服務
B-武漢-14-Java-張鵬(583229382) 20:10:50
分散式佈置的?
- Ask:
memcache可以分散式,但是它自己本身不支援分散式,需要由客戶端程式庫實現