
Mysql關於分庫、分表、分割槽的具體介紹
1、分表
分表是將一個大表按照一定的規則分解成多張具有獨立儲存空間的實體表,我們可以稱為子表,每個表都對應三個檔案,MYD資料檔案,.MYI索引檔案,.frm表結構檔案。這些子表可以分佈在同一塊磁碟上,也可以在不同的機器上。app讀寫的時候根據事先定義好的規則得到對應的子表名,然後去操作它。
分表幾種策略方式
1.1、mysql叢集
事實它並不是分表,但起到了和分表相同的作用。叢集可分擔資料庫的操作次數,將任務分擔到多臺資料庫上。叢集可以讀寫分離,減少讀寫壓力。從而提升資料庫效能。
1.2、自定義規則分表
1 Range(範圍)–這種模式允許將資料劃分不同範圍。例如可以將一個表通過年份劃分成若干個分割槽。
2 Hash(雜湊)–這中模式允許通過對錶的一個或多個列的Hash Key進行計算,最後通過這個Hash碼不同數值對應的資料區域進行分割槽。例如可以建立一個對錶主鍵進行分割槽的表。
3 Key(鍵值)-上面Hash模式的一種延伸,這裡的Hash Key是MySQL系統產生的。
4 List(預定義列表)–這種模式允許系統通過預定義的列表的值來對資料進行分割。
5 composite(複合模式) –以上模式的組合使用。
1.3、利用merge儲存引擎來實現分表
Merge表有點類似於檢視。使用Merge儲存引擎實現MySQL分表,這種方法比較適合那些沒有事先考慮分表,隨著資料的增多,已經出現了資料查詢慢的情況。
這個時候如果要把已有的大資料量表分開比較痛苦,最痛苦的事就是改程式碼。所以使用Merge儲存引擎實現MySQL分表可以避免改程式碼。
Merge引擎下每一張表只有一個MRG檔案。MRG裡面存放著分表的關係,以及插入資料的方式。它就像是一個外殼,或者是連線池,資料存放在分表裡面。
merge合併表的要求:
- 合併的表使用的必須是MyISAM引擎
- 表的結構必須一致,包括索引、欄位型別、引擎和字符集
對於增刪改查,直接操作總表即可。
實現方式:
1.使用者1表
CREATE TABLE `user1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`sex` int(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8; 2.使用者2表
create table user2 like user1;3.主表
CREATE TABLE `alluser` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT NULL, `sex` int(1) NOT NULL DEFAULT '0', KEY `id` (`id`) ) ENGINE=MRG_MyISAM DEFAULT CHARSET=utf8 INSERT_METHOD=LAST UNION=(`user1`,`user2`);
ps:
1) ENGINE = MERGE 和 ENGINE = MRG_MyISAM是一樣的意思,都是代表使用的儲存引擎是 Merge。
2) INSERT_METHOD,表示插入方式,取值可以是:0 和 1,0代表不允許插入,1代表可以插入;
3) FIRST插入到UNION中的第一個表,LAST插入到UNION中的最後一個表。
1. 先在user1表中增加一條資料,然後再在user2表中增加一條資料,檢視 alluser中的資料。
insert into user1(name,sex) values ('張三',1);
insert into user2(name,sex) values ('李四',2);select * from alluser; 發現是剛剛插入的資料如下:
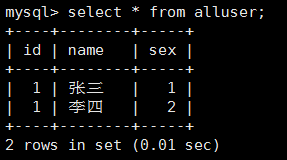
這就出現了一個id重複,這就造成了當刪除和修改的時候異常,解決辦法是給 alluser的id賦唯一值。
我們解決方法是,重新建立一張表tb_ids(id int),用來專門存一個id的,並插入一條初始資料,同時刪除掉user1和user2中的資料。
create table tb_ids(id int);
insert into tb_ids values(1);
delete from user1;
delete from user2;然後在user1和user2表中分別建立一個觸發器(tr_seq和tr_seq2),觸發器的功能是 當在user1或者user2表中增加一條記錄時,取出tb_ids中的id值,賦給user1和user2的id,然後將tb_ids的id值加1,
user1表的觸發器內容如下(user2表的觸發器修要修改 觸發器的名字 和 表名,如下紅字標註):
DELIMITER $$
CREATE TRIGGER tr_seq
BEFORE INSERT on user1
FOR EACH ROW BEGIN
select id into @testid from tb_ids limit 1;
update tb_ids set id = @testid + 1;
set new.id = @testid;
END$$
DELIMITER;2.在user1和user2表中分別增加一條資料,
insert into user1(name,sex) values('王五',1);
insert into user2(name,sex) values('趙六',2);3.查詢user1和user2中的資料:
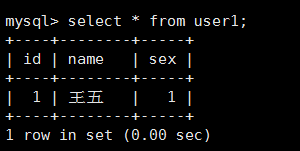
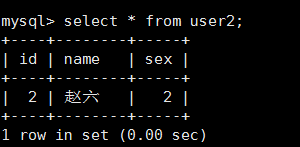
4.查詢總表alluser中的資料,發現id沒有重複的:

2、分割槽
分割槽和分表相似,都是按照規則分解表。不同在於分表將大表分解為若干個獨立的實體表,而分割槽是將資料分段劃分在多個位置存放,可以是同一塊磁碟也可以在不同的機器。分割槽後,表面上還是一張表,但資料雜湊到多個位置了。app讀寫的時候操作的還是大表名字,db自動去組織分割槽的資料。
3、分表和分割槽的區別與聯絡
1.都能提高mysql的性高,在高併發狀態下都有一個良好的表現。
2.分表和分割槽不矛盾,可以相互配合的,對於那些大訪問量,並且表資料比較多的表,我們可以採取分表和分割槽結合的方式(如果merge這種分表方式,不能和分割槽配合的話,可以用其他的分表試試),訪問量不大,但是表資料很多的表,我們可以採取分割槽的方式等。
3.分表技術是比較麻煩的,需要手動去建立子表,app服務端讀寫時候需要計運算元表名。採用merge好一些,但也要建立子表和配置子表間的union關係。
4.表分割槽相對於分表,操作方便,不需要建立子表。
我們知道對於大型的網際網路應用,資料庫單表的資料量可能達到千萬甚至上億級別,同時面臨這高併發的壓力。Master-Slave結構只能對資料庫的讀能力進行擴充套件,寫操作還是集中在Master中,Master並不能無限制的掛接Slave庫,如果需要對資料庫的吞吐能力進行進一步的擴充套件,可以考慮採用分庫分表的策略。
5.資料庫分表可以解決單表海量資料的查詢效能問題,分庫可以解決單臺數據庫的併發訪問壓力問題