
資料庫分割槽、分表、分庫、分片
一、分割槽的概念
資料分割槽是一種物理資料庫的設計技術,它的目的是為了在特定的SQL操作中減少資料讀寫的總量以縮減響應時間。
分割槽並不是生成新的資料表,而是將表的資料均衡分攤到不同的硬碟,系統或是不同伺服器儲存介子中,實際上還是一張表。另外,分割槽可以做到將表的資料均衡到不同的地方,提高資料檢索的效率,降低資料庫的頻繁IO壓力值,分割槽的優點如下:
1、相對於單個檔案系統或是硬碟,分割槽可以儲存更多的資料;
2、資料管理比較方便,比如要清理或廢棄某年的資料,就可以直接刪除該日期的分割槽資料即可;
3、精準定位分割槽查詢資料,不需要全表掃描查詢,大大提高資料檢索效率;
4、可跨多個分割槽磁碟查詢,來提高查詢的吞吐量;
5、在涉及聚合函式查詢時,可以很容易進行資料的合併;
二、分類 (row 行 ,column 列)
1、水平分割槽
這種形式分割槽是對錶的行進行分割槽,通過這樣的方式不同分組裡面的物理列分割的資料集得以組合,從而進行個體分割(單分割槽)或集體分割(1個或多個分割槽)。所有在表中定義的列在每個資料集中都能找到,所以表的特性依然得以保持。舉個簡單例子:一個包含十年發票記錄的表可以被分割槽為十個不同的分割槽,每個分割槽包含的是其中一年的記錄。(朋奕注:這裡具體使用的分割槽方式我們後面再說,可以先說一點,一定要通過某個屬性列來分割,譬如這裡使用的列就是年份)2、垂直分割槽
這種分割槽方式一般來說是通過對錶的垂直劃分來減少目標表的寬度,使某些特定的列被劃分到特定的分割槽,每個分割槽都包含了其中的列所對應的行。舉個簡單例子:一個包含了大text三、分割槽、分表、分庫的詳細理解
一、什麼是分割槽、分表、分庫
分割槽
就是把一張表的資料分成N個區塊,在邏輯上看最終只是一張表,但底層是由N個物理區塊組成的
分表
就是把一張表按一定的規則分解成N個具有獨立儲存空間的實體表。系統讀寫時需要根據定義好的規則得到對應的字表明,然後操作它。
分庫
一旦分表,一個庫中的表會越來越多
將整個資料庫比作圖書館,一張表就是一本書。當要在一本書中查詢某項內容時,如果不分章節,查詢的效率將會下降。而同理,在資料庫中就是分割槽。
二、常用的單機資料庫的瓶頸
問題描述
- 單個表資料量越大,讀寫鎖,插入操作重新建立索引效率越低。
- 單個庫資料量太大(一個數據庫資料量到1T-2T就是極限)
- 單個數據庫伺服器壓力過大
- 讀寫速度遇到瓶頸(併發量幾百)
三、分割槽
什麼時候考慮使用分割槽?
一張表的查詢速度已經慢到影響使用的時候。
sql經過優化
資料量大
- 表中的資料是分段的
對資料的操作往往只涉及一部分資料,而不是所有的資料
分割槽解決的問題
主要可以提升查詢效率
分割槽的實現方式(簡單)
mysql5 開始支援分割槽功能
CREATE TABLE sales (
id INT AUTO_INCREMENT,
amount DOUBLE NOT NULL,
order_day DATETIME NOT NULL,
PRIMARY KEY(id, order_day)
) ENGINE=Innodb
PARTITION BY RANGE(YEAR(order_day)) (
PARTITION p_2010 VALUES LESS THAN (2010),
PARTITION p_2011 VALUES LESS THAN (2011),
PARTITION p_2012 VALUES LESS THAN (2012),
PARTITION p_catchall VALUES LESS THAN MAXVALUE);四、分表
什麼時候考慮分表?
一張表的查詢速度已經慢到影響使用的時候。
sql經過優化
- 資料量大
當頻繁插入或者聯合查詢時,速度變慢
分表解決的問題
分表後,單表的併發能力提高了,磁碟I/O效能也提高了,寫操作效率提高了
- 查詢一次的時間短了
- 資料分佈在不同的檔案,磁碟I/O效能提高
- 讀寫鎖影響的資料量變小
- 插入資料庫需要重新建立索引的資料減少
分表的實現方式(複雜)
需要業務系統配合遷移升級,工作量較大
分割槽和分表的區別與聯絡
分割槽和分表的目的都是減少資料庫的負擔,提高表的增刪改查效率。
- 分割槽只是一張表中的資料的儲存位置發生改變,分表是將一張表分成多張表。
- 當訪問量大,且表資料比較大時,兩種方式可以互相配合使用。
當訪問量不大,但表資料比較多時,可以只進行分割槽。
常見分割槽分表的規則策略(類似)
- Range(範圍)
- Hash(雜湊)
- 按照時間拆分
- Hash之後按照分表個數取模
- 在認證庫中儲存資料庫配置,就是建立一個DB,這個DB單獨儲存user_id到DB的對映關係
12306的訂單是如何儲存的?
五、分庫
什麼時候考慮使用分庫?
- 單臺DB的儲存空間不夠
- 隨著查詢量的增加單臺數據庫伺服器已經沒辦法支撐
分庫解決的問題
其主要目的是為突破單節點資料庫伺服器的 I/O 能力限制,解決資料庫擴充套件性問題。
垂直拆分
將系統中不存在關聯關係或者需要join的表可以放在不同的資料庫不同的伺服器中。
按照業務垂直劃分。比如:可以按照業務分為資金、會員、訂單三個資料庫。
需要解決的問題:跨資料庫的事務、jion查詢等問題。
水平拆分
例如,大部分的站點。資料都是和使用者有關,那麼可以根據使用者,將資料按照使用者水平拆分。
按照規則劃分,一般水平分庫是在垂直分庫之後的。比如每天處理的訂單數量是海量的,可以按照一定的規則水平劃分。需要解決的問題:資料路由、組裝。
讀寫分離
對於時效性不高的資料,可以通過讀寫分離緩解資料庫壓力。需要解決的問題:在業務上區分哪些業務上是允許一定時間延遲的,以及資料同步問題。
思路
垂直分庫-->水平分庫-->讀寫分離
六、拆分之後面臨新的問題
問題
- 事務的支援,分庫分表,就變成了分散式事務
- join時跨庫,跨表的問題
- 分庫分表,讀寫分離使用了分散式,分散式為了保證強一致性,必然帶來延遲,導致效能降低,系統的複雜度變高。
常用的解決方案:
對於不同的方式之間沒有嚴格的界限,特點不同,側重點不同。需要根據實際情況,結合每種方式的特點來進行處理。
選用第三方的資料庫中介軟體(Atlas,Mycat,TDDL,DRDS),同時業務系統需要配合資料儲存的升級。
七、資料儲存的演進
單庫單表
單庫單表是最常見的資料庫設計,例如,有一張使用者(user)表放在資料庫db中,所有的使用者都可以在db庫中的user表中查到。
單庫多表
隨著使用者數量的增加,user表的資料量會越來越大,當資料量達到一定程度的時候對user表的查詢會漸漸的變慢,從而影響整個DB的效能。如果使用mysql, 還有一個更嚴重的問題是,當需要新增一列的時候,mysql會鎖表,期間所有的讀寫操作只能等待。
可以通過某種方式將user進行水平的切分,產生兩個表結構完全一樣的user_0000,user_0001等表,user_0000 + user_0001 + …的資料剛好是一份完整的資料。
多庫多表
隨著資料量增加也許單臺DB的儲存空間不夠,隨著查詢量的增加單臺數據庫伺服器已經沒辦法支撐。這個時候可以再對資料庫進行水平拆分。
八、總結
總的來說,優先考慮分割槽。當分割槽不能滿足需求時,開始考慮分表,合理的分表對效率的提升會優於分割槽。
九、案例分析
京東的商品評價儲存設計,原文地址
現狀
- 商品的評論數量:數十億條
- 每天的服務呼叫:數十億次
- 每年成倍增長
整體的資料儲存:基礎資料儲存,文字儲存
基礎資料儲存
Mysql:只儲存非文字的基礎資訊。包括:評論狀態,使用者,時間等基礎資料。以及圖片,標籤,點贊等附加資訊。資料組織形式(不同的資料又可選擇不同的庫表拆分方案):
- 評論基礎資料按使用者ID進行拆庫並拆表
- 圖片及標籤處於同一資料庫下,根據商品編號分別進行拆表
- 其它的擴充套件資訊資料,因資料量不大、訪問量不高,處理於同一庫下且不做分表即可
文字儲存
文字儲存(評論的內容)使用了mongodb、hbase
- 選擇nosql而非mysql
- 減輕了mysql儲存壓力,釋放msyql,龐大的儲存也有了可靠的保障
- nosql的高效能讀寫大大提升了系統的吞吐量並降低了延遲
裡面會有詳細的說明!!我就不轉載了!!
資料分片
在分散式儲存系統中,資料需要分散儲存在多臺裝置上,資料分片(Sharding)就是用來確定資料在多臺儲存裝置上分佈的技術。資料分片要達到三個目的:
- 分佈均勻,即每臺裝置上的資料量要儘可能相近;
- 負載均衡,即每臺裝置上的請求量要儘可能相近;
- 擴縮容時產生的資料遷移儘可能少。
資料分片方法
資料分片一般都是使用Key或Key的雜湊值來計算Key的分佈,常見的幾種資料分片的方法如下:
- 劃分號段。這種一般適用於Key為整型的情況,每臺裝置上存放相同大小的號段區間,如把Key為[1, 10000]的資料放在第一臺裝置上,把Key為[10001, 20000]的資料放在第二臺裝置上,依次類推。這種方法實現很簡單,擴容也比較方便,成倍增加裝置即可,如原來有N臺裝置,再新增N臺裝置來擴容,把每臺老裝置上一半的資料遷移到新裝置上,原來號段為[1, 10000]的裝置,擴容後只保留號段[1, 5000]的資料,把號段為[5001, 10000]的資料遷移到一臺新增的裝置上。此方法的缺點是資料可能分佈不均勻,如小號段資料量可能比大號段的資料量要大,同樣的各個號段的熱度也可能不一樣,導致各個裝置的負載不均衡;並且擴容也不夠靈活,只能成倍地增加裝置。
- 取模。這種方法先計算Key的雜湊值,再對裝置數量取模(整型的Key也可直接用Key取模),假設有N臺裝置,編號為0~N-1,通過Hash(Key)%N就可以確定資料所在的裝置編號。這種方法實現也非常簡單,資料分佈和負載也會比較均勻,可以新增任何數量的裝置來擴容。主要的問題是擴容的時候,會產生大量的資料遷移,比如從N臺裝置擴容到N+1臺,絕大部分的資料都要在裝置間進行遷移。
- 檢索表。在檢索表中儲存Key和裝置的對映關係,通過查詢檢索表就可以確定資料分佈,這裡的檢索表也可以比較靈活,可以對每個Key都儲存對映關係,也可結合號段劃分等方法來減小檢索表的容量。這樣可以做到資料均勻分佈、負載均衡和擴縮容資料遷移量少。缺點是需要儲存檢索表的空間可能比較大,並且為了保證擴縮容引起的資料遷移量比較少,確定對映關係的演算法也比較複雜。
- 一致性雜湊。一致性雜湊演算法(Consistent Hashing)在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot Spot)問題,該方法的詳細介紹參考此處http://blog.csdn.net/sparkliang/article/details/5279393。一致性雜湊的演算法簡單而巧妙,很容易做到資料均分佈,其單調性也保證了擴縮容的資料遷移是比較少的。
通過上面的對比,在這個系統選擇一致性雜湊的方法來進行資料分片。
虛擬伺服器
為了讓系統有更好的擴充套件性,這裡提出儲存層VServer(虛擬伺服器)的概念,一個VServer是一個邏輯上的儲存伺服器,是分散式儲存系統的一個儲存單元,一臺物理裝置上可以部署多個VServer,一個VServer支援一個寫程序和多個讀程序。
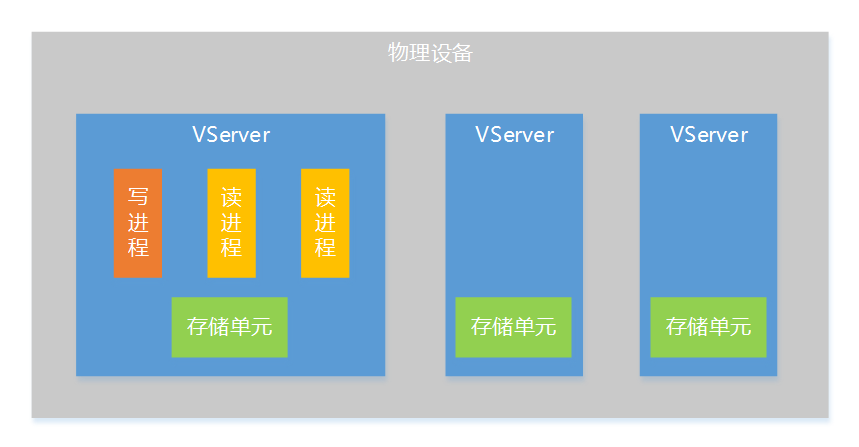
通過VServer的方式,會有下面一些好處:
- 提高單機效能。為了不引入複雜的鎖機制,採用了單寫程序的設計,如果單機只有一個寫程序,寫併發能力會受到限制,通過VServer方式把單機上的儲存資源(記憶體、硬碟)劃分為多個儲存單元,這樣就支援多個寫程序同時工作,大大提升單機寫併發能力。
- 部署擴充套件性更好。VServer的方式在部署上非常靈活,可以根據單機的資源情況來確定VServer的數量,針對不同的機型配置不同的VServer數量,這樣不同的機型都能充分利用機器上的資源,即使在一個系統中使用多種機型,也能做到機器的負載比較均衡。
一致性雜湊的應用
資料分片是在介面層實現的,目的是把資料均勻地劃分到不同的VServer上。有了介面層的存在,邏輯層定址就輕量了很多,定址儲存層VServer的工作全部由介面層負責,邏輯層只需要隨機選一個介面層機器訪問即可。
介面層使用了一致性雜湊的割環演算法來實現資料分片,在割環演算法中,為了讓資料均勻分佈到各個VServer,每個VServer需要有多個VNode(虛擬節點)。一個Key定址的過程如下圖所示,首先根據Hash(Key)在雜湊環上找到對應的VNode,在根據VNode和VServer的對映表確定所屬的VServer。
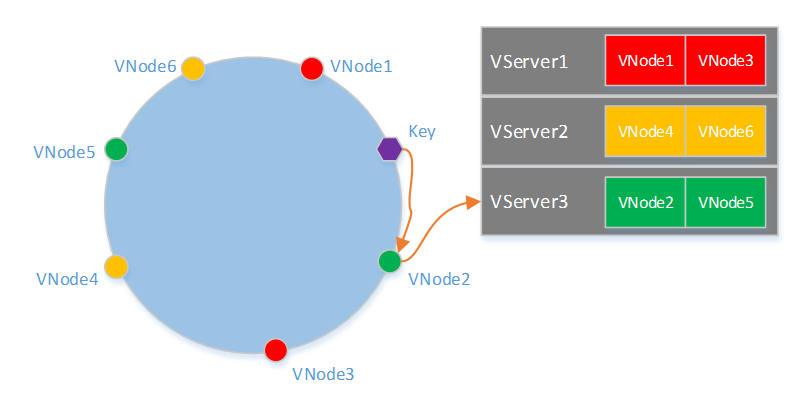
由上述查詢過程可知,需要事先離線計算出VNode在雜湊環上的分佈、VServer和VNode對映關係。為了是計算結果具有通用性,即在擁有任何數量VServer的一個系統都可以使用該結果得到一致性雜湊的對映表,這就要求結果是與機器無關的,比如不能使用IP來計算VNode的雜湊值。在計算前需要確定每個VServer包含的VNode數量,以及一個系統所支援的最大VServer數量。一個簡單的方法是類似上文連結中提到的方法,但不能和IP相關,可以改用VServer和VNode的編號來計算雜湊值,如Hash("1#1"),Hash("1#2")… 這種方法要求一個VServer包含的VNode的數量比較多,大概需要500個才能使各個VServer上的資料比較均勻。當然還有其他的一些方法做到一個VServer上包含更少的VNode數量,並且讓資料分佈偏差在一定範圍內。
Google提出了一種新的一致性雜湊演算法Jump Consistent Hash,此演算法零記憶體消耗,均勻分配,快速,並且只有5行程式碼,優勢非常明顯,詳細介紹見此處http://my.oschina.net/u/658658/blog/424161。和上面介紹的方法相比,一個最大的不同點是,在擴容重新分佈資料時,在上面的方法中,新機器的一個VNode上的資料只會來自一個老機器上的VNode,而這種方法是會來自所有老機器上的VNode。這個問題可能會導致一些設計上覆雜化,所以使用的時候要慎重考慮。
分片模式是什麼?
資料的切分(Sharding)根據其切分規則的型別,可以分為兩種切分模式。
(1)一種是按照不同的表(或者Schema)來切分到不同的資料庫(主機)之上,這種切分可以稱之為資料的垂直(縱向)切分
(2)另外一種則是根據表中的資料的邏輯關係,將同一個表中的資料按照某種條件拆分到多臺資料庫(主機)上面,這種切分稱之為資料的水平(橫向)切分。
分片相關的概念
邏輯庫(schema) :
通常對實際應用來說,並不需要知道中介軟體的存在,業務開發人員只需要知道資料庫的概念,所以資料庫中介軟體可以被看做是一個或多個數據庫叢集構成的邏輯庫。
- 邏輯表(table):
既然有邏輯庫,那麼就會有邏輯表,分散式資料庫中,對應用來說,讀寫資料的表就是邏輯表。邏輯表,可以是資料切分後,分佈在一個或多個分片庫中,也可以不做資料切分,不分片,只有一個表構成。
- 分片表:
是指那些原有的很大資料的表,需要切分到多個數據庫的表,這樣,每個分片都有一部分資料,所有分片構成了完整的資料。 總而言之就是需要進行分片的表。
- 非分片表:
一個數據庫中並不是所有的表都很大,某些表是可以不用進行切分的,非分片是相對分片表來說的,就是那些不需要進行資料切分的表。
- 分片節點(dataNode)
資料切分後,一個大表被分到不同的分片資料庫上面,每個表分片所在的資料庫就是分片節點(dataNode)。
- 節點主機(dataHost)
資料切分後,每個分片節點(dataNode)不一定都會獨佔一臺機器,同一機器上面可以有多個分片資料庫,這樣一個或多個分片節點(dataNode)所在的機器就是節點主機(dataHost),為了規避單節點主機併發數限制,儘量將讀寫壓力高的分片節點(dataNode)均衡的放在不同的節點主機(dataHost)。
- 分片規則(rule)
前面講了資料切分,一個大表被分成若干個分片表,就需要一定的規則,這樣按照某種業務規則把資料分到某個分片的規則就是分片規則,資料切分選擇合適的分片規則非常重要,將極大的避免後續資料處理的難度。
轉:https://blog.csdn.net/weixin_38074050/article/details/78640004相關推薦
資料庫分割槽、分表、分庫、分片
一、分割槽的概念 資料分割槽是一種物理資料庫的設計技術,它的目的是為了在特定的SQL操作中減少資料讀寫的總量以縮減響應時間。 分割槽並不是生成新的資料表,而是將表的資料均衡分攤到不同的硬碟,系統或是不同伺服器儲存介子中,實際上還是一張表。另外,分割
資料庫分割槽、分表、分庫,讀寫分離
分割槽就是把一張表的資料分成N個區塊,在邏輯上看最終只是一張表,但底層是由N個物理區塊組成的。分割槽的實現方式(簡單)mysql5 開始支援分割槽功能CREATE TABLE sales ( id INT AUTO_INCREMENT, amount DOUB
使用Mycat實現Mysql資料庫的主從複製、讀寫分離、分表分庫、負載均衡和高可用
Mysql叢集搭建 使用Mycat實現Mysql資料庫的主從複製、讀寫分離、分表分庫、負載均衡和高可用(Haproxy+keepalived),總體架構: 說明:資料庫的訪問通過keepalived的虛擬IP訪問HAProxy負載均衡器,實現HAProxy的高可用,HAProxy用於實
學會資料庫讀寫分離、分表分庫——用Mycat,這一篇就夠了!
轉: https://www.cnblogs.com/joylee/p/7513038.html 系統開發中,資料庫是非常重要的一個點。除了程式的本身的優化,如:SQL語句優化、程式碼優化,資料庫的處理本身優化也是非常重要的。主從、熱備、分表分庫等都是系統
Mysql關於分庫、分表、分割槽的具體介紹
1、分表 分表是將一個大表按照一定的規則分解成多張具有獨立儲存空間的實體表,我們可以稱為子表,每個表都對應三個檔案,MYD資料檔案,.MYI索引檔案,.frm表結構檔案。這些子表可以分佈在同一塊磁碟上,也可以在不同的機器上。app讀寫的時候根據事先定義好的規則得到對應的子表
資料庫讀寫分離、分表分庫——Mycat
系統開發中,資料庫是非常重要的一個點。除了程式的本身的優化,如:SQL語句優化、程式碼優化,資料庫的處理本身優化也是非常重要的。主從、熱備、分表分庫等都是系統發展遲早會遇到的技術問題問題。Mycat是一個廣受好評的資料庫中介軟體,已經在很多產品上進行使用了。希望通過這篇
資料庫切庫、分庫、分表
切庫的基礎和實際運用—讀寫分離:如何方便進行讀寫分離,目前有兩種方式:1.動態資料來源切換它是指程式執行時,把資料來源動態的織入到程式中,讓指定的程式連線主庫還是從庫2.直接定義查資料來源和寫資料來源直接在專案裡定義兩個資料庫連線,一個是主庫連線一個是從庫連線,更新資料的時候我們讀取主庫連線,查詢資料的時候讀
資料庫水平切分的實現原理—分庫、分表、讀寫分離、負載均衡、主從複製
水平切分資料庫的目的 其主要目的是為突破單節點資料庫伺服器的 I/O 能力限制,解決資料庫擴充套件性問題 通過一系列的切分規則將資料水平分佈到不同的DB或table中,在通過相應的DB路由或者table路由規則找到需要查詢的具體的DB或者table,以進行Query操作
Mycat分庫分表的簡單實踐 / 用Mycat,學會資料庫讀寫分離、分表分庫
原創 楊建榮的學習筆記 2017-09-06 10:03 //沒找到原創地址,轉載別人的也沒留地址 。。。 MySQL的使用場景中,讀寫分離只是方案中的一部分,想要擴充套件,勢必會用到分庫分表,可喜的是Mycat裡已經做到了,今天花時間測試了一下,感覺還不錯。
mysql分庫、分表、分割槽
分表是分散資料庫壓力的好方法。 分表,最直白的意思,就是將一個表結構分為多個表,然後,可以再同一個庫裡,也可以放到不同的庫。 當然,首先要知道什麼情況下,才需要分表。個人覺得單表記錄條數達到百萬到千萬級別時就要使用分表了。 1,分表的分類 1>縱向分表
Mycat分庫分表的簡單實踐 / 用Mycat,學會資料庫讀寫分離、分表分庫
MySQL的使用場景中,讀寫分離只是方案中的一部分,想要擴充套件,勢必會用到分庫分表,可喜的是Mycat裡已經做到了,今天花時間測試了一下,感覺還不錯。 關於分庫分表 當然自己也理了一下,分庫分表的這些內容,如果分成幾個策略或者階段,大概有下面的幾種。 最上面的第一種是直接拆表,比如資料庫db1下面有te
分散式資料庫架構--分庫、分表、排序、分頁、分組、實現
最近研究分散式資料庫架構,發現排序、分組及分頁讓著實人有點頭疼。現把問題及解決思路整理如下。 一、 多分片(水平切分)返回結果合併(排序) 1、Select + None Aggregate Function的有序記錄合併排序 解決思路:對各分片返回的有序記錄,進行排序去重合
【分庫、分表】MySQL分庫分表方案
分表 性能 正常 事先 AD 現在 新用戶 我們 java 一、Mysql分庫分表方案 1.為什麽要分表: 當一張表的數據達到幾千萬時,你查詢一次所花的時間會變多,如果有聯合查詢的話,我想有可能會死在那兒了。分表的目的就在於此,減小數據庫的負擔,縮短查詢時間。 mys
數據庫切庫、分庫、分表
動態數據 alt idt 速度 提高 sql 操作 一個數據庫 並發 切庫的基礎和實際運用—讀寫分離: 如何方便進行讀寫分離,目前有兩種方式: 1.動態數據源切換 它是指程序運行時,把數據源動態的織入到程序中,讓指定的程序連接主庫還是從庫 自定義註解完成數據庫切庫 2.直
sharding(1):誰都能讀懂的分庫、分表、分區
一個數 效率 存儲方式 開放 大量 har 但是 業務 相關信息 本文通過大量圖片來分析和描述分庫、分表以及數據庫分區是怎樣進行的。 1.sharding前的初始數據分布 在本文中,我打算用高考考生相關信息作為實驗數據。請無視表的字段是否符合現實,也請無視表的設計是否符合
理論結合實踐總結分庫、分表
垂直拆分 垂直分表 把一張列比較多的表拆分成多張表,又稱為「大表拆小表」,拆分是基於關係型資料庫中的「列」(欄位)進行的。通常情況,某個表中的欄位比較多,可以新建立一種「擴充套件表」,可以按照如下原則進行垂直拆分: 把不經常使用的欄位單獨放在一張表 把 tex
學會數據庫讀寫分離、分表分庫——用Mycat
切換 心跳 native 自動生成 拆分 運行 管理命令 users 業界 系統開發中,數據庫是非常重要的一個點。除了程序的本身的優化,如:SQL語句優化、代碼優化,數據庫的處理本身優化也是非常重要的。主從、熱備、分表分庫等都是系統發展遲早會遇到的技術問題問題。Myca
大資料分庫、分表設計(mysql)
1.應用場景: 使用mysql資料庫做查詢,當資料量超過200w時,查詢數度受到限制,此時為了避開這一瓶頸,我們採取分庫分表的資料庫設計思想,將資料按照一定規律儲存至資料庫,常用的方式如下: 1.1使用時間作為依據分庫/分表
mysql主從、主主、分庫、分表
mysql: mysql主從複製: 一主一從 互為主從 一主多從 多主多從 主從延遲:主庫寫資料為多執行緒,從庫同步資料為單執行緒,從庫同步速度慢。 【1】MySQL_proxy-----mysql中介軟體; 【2】從資料伺服器高配置; 【3】從伺服器
HIVE的安裝配置、mysql的安裝、hive建立表、建立分割槽、修改表等內容、hive beeline使用、HIVE的四種資料匯入方式、使用Java程式碼執行hive的sql命令
1.上傳tar包 這裡我上傳的是apache-hive-1.2.1-bin.tar.gz 2.解壓 mkdir -p /home/tuzq/software/hive/ tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /home/