
Java平行計算Fork/Join框架使用
背景介紹
假如目前有個需求,計算1000個數字之和,此需求是不是很簡單,一次迴圈,即可完成計算;但如果是計算100W甚至更多的呢?當然,此時的迴圈依然可以達到目的,但效率就不敢恭維;同時,如果此時有個需求,需要統計100個檔案中某個單詞出現的次數呢?最直接的辦法也是依次迴圈這100個檔案,最終統計到結果,更好一步,你應該想到了執行緒池處理,起10個執行緒,每個執行緒讀10個檔案統計,這樣效率就提升10倍左右。使用執行緒池可以很好的解決問題,但是對最終結果合併可能比較麻煩。幸好,JDK為我們提供了很好的並行解決方案fork/join框架。
Fork/Join介紹
Fork/Join主要功能即將一個任務拆分為多個子任務執行,最終再將子任務的執行結果合併(瞭解Hadoop的童鞋此時應該想起了Hadoop的MapReduce)。
如果需要學習Fork/Join,首先需要了解如下四個類:
- ForkJoinPoll:程式中只需要建立一個這樣的例項來執行所有fork-join任務。
- RecursiveTask:線上程池中執行一個本類的子類,它可以返回結果。
- RecursiveAction:和RecursiveTask類似但是不返回結果。
- ForkJoinTask:是RecursiveTask和RecursiveAction的父類,join方法就是定義在本類中。一般不需要直接使用此類,但是如果想要了解更多方法,你可以在本類中找到很多有用的javadoc文件。
Fork/Join圖例介紹
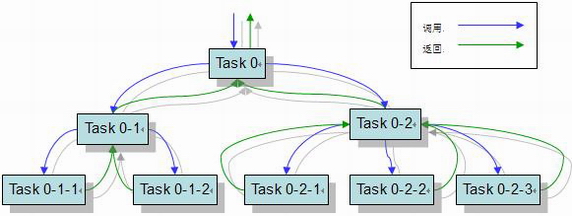
分治法原理
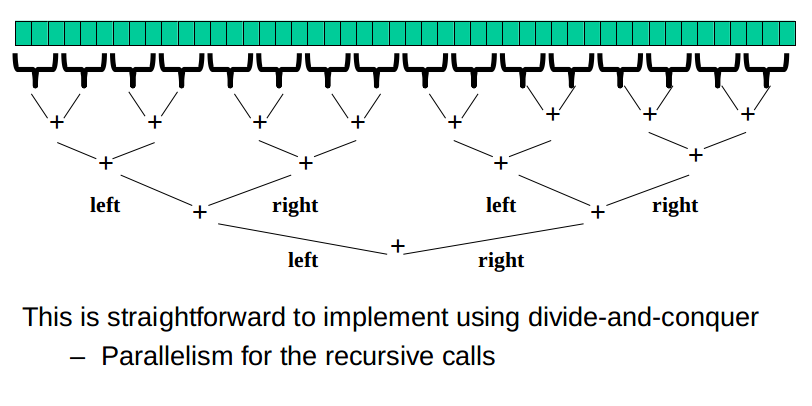
程式碼示例
我們以計算10000個數字和為例說明Fork/Join使用方法:
public class Sum extends RecursiveTask<Long>
{
/**
* {變數說明}
*/
private static final long serialVersionUID = 1L;
private static final Long THRESHOLD = 100L;
private Long start;
private Long end;
public Sum(Long start, Long end)
{
this 程式碼比較簡單,Sum繼承了RecursiveTask,RecursiveTask如上面所說,會返回結果,此處我們是計算和,所以需要將計算結果返回;
程式碼主要邏輯:如果待計算集合小於100時,則迴圈求和即可,反之,則將任務拆分為兩個子任務(fork),然後再將兩個任務結果合併(join),最終返回兩個任務的合併結果。
測試:
public class CommonTest
{
public static void main(String[] args) throws Exception
{
ForkJoinPool pool = new ForkJoinPool();
Future<Long> result = pool.submit(new Sum(0L, 10000L));
// pool.shutdown();
System.out.println(result.get());
}
}使用起來是不是很簡單,這就是JDK的Fork/Join模式。
注意:
ForkJoinPool為我們提供了shutdown()和shutdownNow()方法。
其中執行shutdown()方法之後,ForkJoinPool 不再接受新的任務,但是已經提交的任務可以繼續執行,此時如果再提交任務,則丟擲異常:java.util.concurrent.RejectedExecutionException。
而執行shotdownNow()方法後,則ForkJoinPool立即停止執行,同時丟擲異常:java.util.concurrent.CancellationException。
後記
從上面我們可知,將一個任務拆分為多個子任務去執行,可以很好的提升執行效率,但是並不是拆分的子任務越多執行效率越快,因為拆分子任務也是基於多執行緒思想執行,而系統中建立執行緒本來就是一種比較消耗時間和系統資源的。那麼,在需要拆分任務的時候,應該拆分多少個任務才合理呢?參考如下演算法:
常見方法——計算密集型,設為CPU個數+1;IO密集型,設為2*CPU個數+1
精確計算——( IO等待時間/CPU計算時間 + 1 )* CPU個數