
mysql知識盤點【貳】_InnoDB引擎索引
本文主要基於Mysql資料庫的InnoDB引擎介紹下其索引的實現。
索引結構
在B+Tree的每個葉子節點增加一個指向相鄰葉子節點的指標,就形成了帶有順序訪問指標的B+Tree。做這個優化的目的是為了提高區間訪問的效能,當進行範圍查詢時只需順著節點和指標順序遍歷就可以一次性訪問到所有資料節點,極大提到了區間查詢效率。
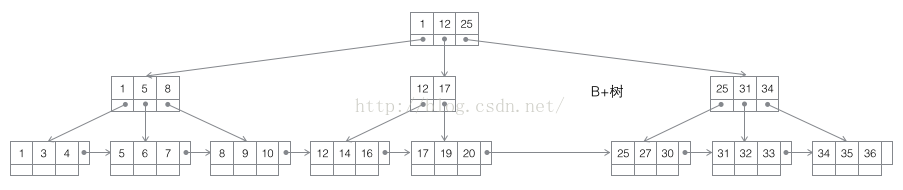
一般來說,由於索引本身也很大,不可能全部儲存在記憶體中,因此索引往往以索引檔案的形式儲存的磁碟上。這樣的話,索引查詢過程中就要產生磁碟I/O消耗,索引的結構組織要儘量減少查詢過程中磁碟I/O的存取次數。為了提高查詢效能,磁碟往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個位元組,磁碟也會從這個位置開始,順序向後讀取一定長度的資料放入記憶體。
這樣做的理論依據是電腦科學的區域性性原理:
當一個數據被用到時,其附近的資料也通常會馬上被使用。
頁(page)是InnoDB儲存引擎管理資料庫的最小磁碟單位,InnoDB中的頁大小為16KB,且不可以更改。上面說的預讀的長度一般為頁的整倍數。
聚簇索引
在InnoDB中,表資料檔案本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域儲存了完整的資料記錄。這個索引的key是資料表的主鍵,因此InnoDB表資料檔案本身就是主索引,稱為聚簇索引。
因為InnoDB的資料檔案本身要按主鍵聚集,所以InnoDB要求表必須有主鍵。如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識資料記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含欄位作為主鍵,這個欄位長度為6個位元組,型別為長整形。
表中的聚簇索引(clustered index)就是一級索引。除此之外,表上的其他非聚簇索引都是二級索引,又叫輔助索引(secondary indexes)。
那麼InnoDB與MyISAM在索引實現上有何區別呢?
1.InnoDB的資料檔案本身就是索引檔案,而MyISAM為另做儲存;
2.InnoDB的輔助索引data域儲存相應記錄主鍵的值,而MyISAM儲存的是地址;
索引覆蓋
覆蓋索引的優勢,在於可以從索引中直接獲取查詢結果並返回,不需要回表查詢。通常使用滿足如下條件:
1.select查詢的返回列包含在索引列中;
2.有where條件時,where條件中要包含索引列或複合索引的前導列;
3.查詢結果的總欄位長度可以接受;
不能使用索引的情況
1.查詢條件與聯合索引列順序不匹配;
2.查詢條件沒有使用索引第一列;
3.字首模糊匹配;
4.範圍列後面的列無法用到索引;
5.對欄位進行了函式計算;
不適合建索引
1.表記錄比較少;
2.區別度比較低;