
負載均衡之加權輪詢演算法
在介紹加權輪詢演算法(WeightedRound-Robin)之前,首先介紹一下輪詢演算法(Round-Robin)。
一:輪詢演算法(Round-Robin)
輪詢演算法是最簡單的一種負載均衡演算法。它的原理是把來自使用者的請求輪流分配給內部的伺服器:從伺服器1開始,直到伺服器N,然後重新開始迴圈。
演算法的優點是其簡潔性,它無需記錄當前所有連線的狀態,所以它是一種無狀態排程。
假設有N臺伺服器:S = {S1, S2, …, Sn},一個指示變數i表示上一次選擇的伺服器ID。變數i被初始化為N-1。該演算法的虛擬碼如下:
j = i; do { j = (j + 1) mod n; i = j; return Si; } while (j != i); return NULL;
輪詢演算法假設所有伺服器的處理效能都相同,不關心每臺伺服器的當前連線數和響應速度。當請求服務間隔時間變化比較大時,輪詢演算法容易導致伺服器間的負載不平衡。所以此種均衡演算法適合於伺服器組中的所有伺服器都有相同的軟硬體配置並且平均服務請求相對均衡的情況。
二:加權輪詢演算法(WeightedRound-Robin)
輪詢演算法並沒有考慮每臺伺服器的處理能力,實際中可能並不是這種情況。由於每臺伺服器的配置、安裝的業務應用等不同,其處理能力會不一樣。所以,加權輪詢演算法的原理就是:根據伺服器的不同處理能力,給每個伺服器分配不同的權值,使其能夠接受相應權值數的服務請求。
首先看一個簡單的Nginx負載均衡配置。
http {
upstream cluster {
server a weight=1;
server b weight=2;
server c weight=4;
}
...
} 按照上述配置,Nginx每收到7個客戶端的請求,會把其中的1個轉發給後端a,把其中的2個轉發給後端b,把其中的4個轉發給後端c。
加權輪詢演算法的結果,就是要生成一個伺服器序列。每當有請求到來時,就依次從該序列中取出下一個伺服器用於處理該請求。比如針對上面的例子,加權輪詢演算法會生成序列{c, c, b, c, a, b, c}。這樣,每收到7個客戶端的請求,會把其中的1個轉發給後端a,把其中的2個轉發給後端b,把其中的4個轉發給後端c。收到的第8個請求,重新從該序列的頭部開始輪詢。
總之,加權輪詢演算法要生成一個伺服器序列,該序列中包含n個伺服器。n是所有伺服器的權重之和。在該序列中,每個伺服器的出現的次數,等於其權重值。並且,生成的序列中,伺服器的分佈應該儘可能的均勻。比如序列{a, a, a, a, a, b, c}中,前五個請求都會分配給伺服器a,這就是一種不均勻的分配方法,更好的序列應該是:{a, a, b, a, c, a, a}。
下面介紹兩種加權輪詢演算法:
1:普通加權輪詢演算法
這種演算法的原理是:在伺服器陣列S中,首先計算所有伺服器權重的最大值max(S),以及所有伺服器權重的最大公約數gcd(S)。
index表示本次請求到來時,選擇的伺服器的索引,初始值為-1;current_weight表示當前排程的權值,初始值為max(S)。
當請求到來時,從index+1開始輪詢伺服器陣列S,找到其中權重大於current_weight的第一個伺服器,用於處理該請求。記錄其索引到結果序列中。
在輪詢伺服器陣列時,如果到達了陣列末尾,則重新從頭開始搜尋,並且減小current_weight的值:current_weight -= gcd(S)。如果current_weight等於0,則將其重置為max(S)。
該演算法的實現程式碼如下:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
typedef struct
{
int weight;
char name[2];
}server;
int getsum(int *set, int size)
{
int i = 0;
int res = 0;
for (i = 0; i < size; i++)
res += set[i];
return res;
}
int gcd(int a, int b)
{
int c;
while(b)
{
c = b;
b = a % b;
a = c;
}
return a;
}
int getgcd(int *set, int size)
{
int i = 0;
int res = set[0];
for (i = 1; i < size; i++)
res = gcd(res, set[i]);
return res;
}
int getmax(int *set, int size)
{
int i = 0;
int res = set[0];
for (i = 1; i < size; i++)
{
if (res < set[i]) res = set[i];
}
return res;
}
int lb_wrr__getwrr(server *ss, int size, int gcd, int maxweight, int *i, int *cw)
{
while (1)
{
*i = (*i + 1) % size;
if (*i == 0)
{
*cw = *cw - gcd;
if (*cw <= 0)
{
*cw = maxweight;
if (*cw == 0)
{
return -1;
}
}
}
if (ss[*i].weight >= *cw)
{
return *i;
}
}
}
void wrr(server *ss, int *weights, int size)
{
int i = 0;
int gcd = getgcd(weights, size);
int max = getmax(weights, size);
int sum = getsum(weights, size);
int index = -1;
int curweight = 0;
for (i = 0; i < sum; i++)
{
lb_wrr__getwrr(ss, size, gcd, max, &(index), &(curweight));
printf("%s(%d) ", ss[index].name, ss[index].weight);
}
printf("\n");
return;
}
server *initServers(char **names, int *weights, int size)
{
int i = 0;
server *ss = calloc(size, sizeof(server));
for (i = 0; i < size; i++)
{
ss[i].weight = weights[i];
memcpy(ss[i].name, names[i], 2);
}
return ss;
}
int main()
{
int i = 0;
int weights[] = {1, 2, 4};
char *names[] = {"a", "b", "c"};
int size = sizeof(weights) / sizeof(int);
server *ss = initServers(names, weights, size);
printf("server is ");
for (i = 0; i < size; i++)
{
printf("%s(%d) ", ss[i].name, ss[i].weight);
}
printf("\n");
printf("\nwrr sequence is ");
wrr(ss, weights, size);
return;
}上面的程式碼中,演算法的核心部分就是wrr和lb_wrr__getwrr函式。在wrr函式中,首先計算所有伺服器權重的最大公約數gcd,權重最大值max,以及權重之和sum。
初始時,index為-1,curweight為0,然後依次呼叫lb_wrr__getwrr函式,得到本次選擇的伺服器索引index。
演算法的核心思想體現在lb_wrr__getwrr函式中。以例子說明更好理解一些:對於伺服器陣列{a(1), b(2), c(4)}而言,gcd為1,maxweight為4。
第1次呼叫該函式時,i(index)為-1,cw(current_weight)為0,進入迴圈後,i首先被置為0,因此cw被置為maxweight。從i開始輪詢伺服器陣列ss,第一個權重大於等於cw的伺服器是c,因此,i被置為2,並返回其值。
第2次呼叫該函式時,i為2,cw為maxweight。進入迴圈後,i首先被置為0,因此cw被置為cw-gcd,也就是3。從i開始輪詢伺服器陣列ss,第一個權重大於等於cw的伺服器還是c,因此,i被置為2,並返回其值。
第3次呼叫該函式時,i為2,cw為3。進入迴圈後,i首先被置為0,因此cw被置為cw-gcd,也就是2。從i開始輪詢伺服器陣列ss,第一個權重大於等於cw的伺服器是b,因此,i被置為1,並返回其值。
第4次呼叫該函式時,i為1,cw為2。進入迴圈後,i首先被置為2,從i開始輪詢伺服器陣列ss,第一個權重大於等於cw的伺服器是c,因此,i被置為2,並返回其值。
第5次呼叫該函式時,i為2,cw為2。進入迴圈後,i首先被置為0,因此cw被置為cw-gcd,也就是1。從i開始輪詢伺服器陣列ss,第一個權重大於等於cw的伺服器是a,因此,i被置為0,並返回其值。
第6次呼叫該函式時,i為0,cw為1。進入迴圈後,i首先被置為1,從i開始輪詢伺服器陣列ss,第一個權重大於等於cw的伺服器是b,因此,i被置為1,並返回其值。
第7次呼叫該函式時,i為1,cw為1。進入迴圈後,i首先被置為2,從i開始輪詢伺服器陣列ss,第一個權重大於等於cw的伺服器是c,因此,i被置為2,並返回其值。
經過7(1+2+4)次呼叫之後,每個伺服器被選中的次數正好是其權重值。上面程式的執行結果如下:
server is a(1) b(2) c(4)
wrr sequence is c(4) c(4) b(2) c(4) a(1) b(2) c(4)
如果有新的請求到來,第8次呼叫該函式時,i為2,cw為1。進入迴圈後,i首先被置為0,cw被置為cw-gcd,也就是0,因此cw被重置為maxweight。這種情況就跟第一次呼叫該函式時一樣了。因此,7次是一個輪迴,7次之後,重複之前的過程。
這背後的數學原理,自己思考了一下,總結如下:
current_weight的值,其變化序列就是一個等差序列:max, max-gcd, max-2gcd, …, 0(max),將current_weight從max變為0的過程,稱為一個輪迴。
針對每個current_weight,該演算法就是要把伺服器陣列從頭到尾掃描一遍,將其中權重大於等於current_weight的所有伺服器填充到結果序列中。掃描完一遍伺服器陣列之後,將current_weight變為下一個值,再一次從頭到尾掃描伺服器陣列。
在current_weight變化過程中,不管current_weight當前為何值,具有max權重的伺服器每次肯定會被選中。因此,具有max權重的伺服器會在序列中出現max/gcd次(等差序列中的項數)。
更一般的,當current_weight變為x之後,權重為x的伺服器,在current_weight接下來的變化過程中,每次都會被選中,因此,具有x權重的伺服器,會在序列中出現x/gcd次。所以,每個伺服器在結果序列中出現的次數,是與其權重成正比的,這就是符合加權輪詢演算法的要求了。
2:平滑的加權輪詢
上面的加權輪詢演算法有個缺陷,就是某些情況下生成的序列是不均勻的。比如針對這樣的配置:
http {
upstream cluster {
server a weight=5;
server b weight=1;
server c weight=1;
}
...
} 生成的序列是這樣的:{a,a, a, a, a, c, b}。會有5個連續的請求落在後端a上,分佈不太均勻。
在Nginx原始碼中,實現了一種叫做平滑的加權輪詢(smooth weighted round-robin balancing)的演算法,它生成的序列更加均勻。比如前面的例子,它生成的序列為{ a, a, b, a, c, a, a},轉發給後端a的5個請求現在分散開來,不再是連續的。
該演算法的原理如下:
每個伺服器都有兩個權重變數:
a:weight,配置檔案中指定的該伺服器的權重,這個值是固定不變的;
b:current_weight,伺服器目前的權重。一開始為0,之後會動態調整。
每次當請求到來,選取伺服器時,會遍歷陣列中所有伺服器。對於每個伺服器,讓它的current_weight增加它的weight;同時累加所有伺服器的weight,並儲存為total。
遍歷完所有伺服器之後,如果該伺服器的current_weight是最大的,就選擇這個伺服器處理本次請求。最後把該伺服器的current_weight減去total。
上述描述可能不太直觀,來看個例子。比如針對這樣的配置:
http {
upstream cluster {
server a weight=4;
server b weight=2;
server c weight=1;
}
...
} 按照這個配置,每7個客戶端請求中,a會被選中4次、b會被選中2次、c會被選中1次,且分佈平滑。我們來算算看是不是這樣子的。
initial current_weight of a, b, c is {0, 0, 0}
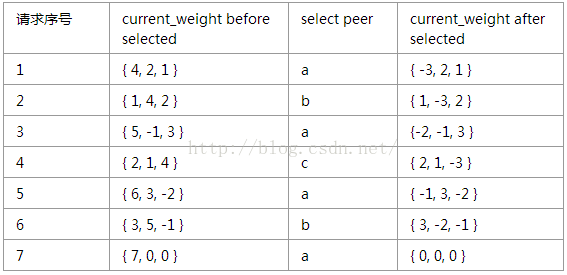
通過上述過程,可得以下結論:
a:7個請求中,a、b、c分別被選取了4、2、1次,符合它們的權重值。
b:7個請求中,a、b、c被選取的順序為a, b,a, c, a, b, a,分佈均勻,權重大的後端a沒有被連續選取。
c:每經過7個請求後,a、b、c的current_weight又回到初始值{0, 0,0},因此上述流程是不斷迴圈的。
根據該演算法實現的程式碼如下:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
typedef struct
{
int weight;
int cur_weight;
char name[3];
}server;
int getsum(int *set, int size)
{
int i = 0;
int res = 0;
for (i = 0; i < size; i++)
res += set[i];
return res;
}
server *initServers(char **names, int *weights, int size)
{
int i = 0;
server *ss = calloc(size+1, sizeof(server));
for (i = 0; i < size; i++)
{
ss[i].weight = weights[i];
memcpy(ss[i].name, names[i], 3);
ss[i].cur_weight = 0;
}
return ss;
}
int getNextServerIndex(server *ss, int size)
{
int i ;
int index = -1;
int total = 0;
for (i = 0; i < size; i++)
{
ss[i].cur_weight += ss[i].weight;
total += ss[i].weight;
if (index == -1 || ss[index].cur_weight < ss[i].cur_weight)
{
index = i;
}
}
ss[index].cur_weight -= total;
return index;
}
void wrr_nginx(server *ss, int *weights, int size)
{
int i = 0;
int index = -1;
int sum = getsum(weights, size);
for (i = 0; i < sum; i++)
{
index = getNextServerIndex(ss, size);
printf("%s(%d) ", ss[index].name, ss[index].weight);
}
printf("\n");
}
int main()
{
int i = 0;
int weights[] = {4, 2, 1};
char *names[] = {"a", "b", "c"};
int size = sizeof(weights) / sizeof(int);
server *ss = initServers(names, weights, size);
printf("server is ");
for (i = 0; i < size; i++)
{
printf("%s(%d) ", ss[i].name, ss[i].weight);
}
printf("\n");
printf("\nwrr_nginx sequence is ");
wrr_nginx(ss, weights, size);
return;
}
上述程式碼的執行結果如下:
server is a(4) b(2) c(1)
wrr_nginx sequence is a(4) b(2) a(4) c(1) a(4) b(2) a(4)
如果伺服器配置為:{a(5),b(1), c(1)},則執行結果如下:
server is a(5) b(1) c(1)
wrr_nginx sequence is a(5) a(5) b(1) a(5) c(1) a(5) a(5)
可見,該演算法生成的序列確實更加均勻。
該演算法背後的數學原理,實在沒想出來,google也沒查到相關論證……,等待後續查證了。
三:健康檢查
負載均衡演算法,一般要伴隨健康檢查演算法一起使用。健康檢查演算法的作用就是對所有的伺服器進行存活和健康檢測,看是否需要提供給負載均衡做選擇。如果一臺機器的服務出現了問題,健康檢查就會將這臺機器從服務列表中去掉,讓負載均衡演算法看不到這臺機器的存在。
具體在加權輪詢演算法中,當健康檢查演算法檢測出某伺服器的狀態發生了變化,比如從UP到DOWN,或者反之時,就會更新權重,重新計算結果序列。
參考: