
二、Hadoop大資料處理架構
一、概述
Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺。是一個能夠對大量資料進行分散式處理的軟體框架。由Java開發,但開發其應用可以使用多種語言,C,C++,跨平臺性非常好。
兩大核心:解決了分散式儲存和分散式處理兩大問題
- HDFS(Hadoop Distributed File System)
- MapRedue
Hadoop 2.0 (Apache免費開源,企業版可以選擇Cloudera,更方面都更優異(安裝,計算等))
- MapReduce(離線計算,批處理,基於磁碟),Spark(與MapReduce類似,基於記憶體,所以效能更優)
- YARN(資源分配,CPU,記憶體等等)
- HDFS(分散式儲存)
下面是更詳細的Hadoop生態系統
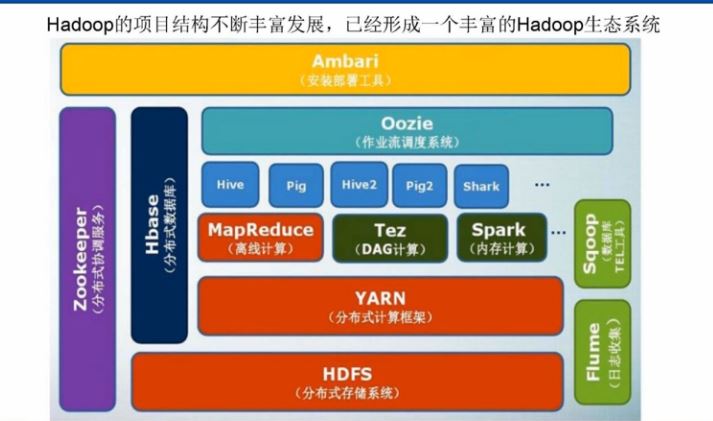
相關推薦
二、Hadoop大資料處理架構
一、概述 Hadoop是Apache軟體基金會旗下的一個開源分散式計算平臺。是一個能夠對大量資料進行分散式處理的軟體框架。由Java開發,但開發其應用可以使用多種語言,C,C++,跨平臺性非常好。 兩大核心:解決了分散式儲存和分散式處理兩大問題 HDFS(Hadoop Distributed Fi
大資料技術原理與應用 第二章 大資料處理架構Hadoop 學習指南
本指南介紹Linux的選擇方案,並詳細指引讀者根據自己選擇的Linux系統安裝Hadoop。請務必仔細閱讀完廈門大學林子雨編著的《大資料技術原理與應用》第2章節,再結合本指南進行學習。Hadoop是基於Java語言開發的,具有很好跨平臺的特性。Hadoop的所要求系統環境適用於Windows,Linux,Ma
0基礎搭建Hadoop大資料處理-程式設計
Hadoop的程式設計可以是在Linux環境或Winows環境中,在此以Windows環境為示例,以Eclipse工具為主(也可以用IDEA)。網上也有很多開發的文章,在此也參考他們的內容只作簡單的介紹和要點總結。 Hadoop是一個強大的並行框架,它允許任務在
Hadoop大資料平臺架構與實踐
一、什麼是Apache Hadoop? 1.1 定義和特性 可靠的、可擴充套件的、分散式計算開源軟體。 Apache Hadoop軟體庫是一個框架,允許使用簡單的程式設計模型,在計算機叢集分散式地處理大型資料集。 它可以從單個伺服器擴充套件到數千臺機器,每個機
Spark、Hadoop大資料平臺搭建
下載安裝包 Spark 分散式計算 spark-2.3.2-bin-hadoop2.7,安裝包大小:220M 支援Hadoop 2.7以後的版本 Scala Scala環境,Spark的開發語言 scala-2.12.8.tgz,安裝包大小:20M Hadoo
hadoop大資料處理平臺與案例
大資料可以說是從搜尋引擎誕生之處就有了,我們熟悉的搜尋引擎,如百度搜索引擎、360搜尋引擎等可以說是大資料技處理技術的最早的也是比較基礎的一種應用。大概在2015年大資料都還不是非常火爆,2015年可以說是大資料的一個分水嶺。隨著網際網路技術的快速發展,大資料也隨之迎來它的發
hadoop大資料平臺架構之DKhadoop詳解
大資料的時代已經來了,資訊的爆炸式增長使得越來越多的行業面臨這大量資料需要儲存和分析的挑戰。Hadoop作為一個開源的分散式並行處理平臺,以其高拓展、高效率、高可靠等優點越來越受到歡迎。這同時也帶動了hadoop商業版的發行。這裡就通過大快DKhadoop為大家詳細介紹一下h
大資料初學者福利:一片文章教你搭建Hadoop大資料處理環境
由於Hadoop需要執行在Linux環境中,而且是分散式的,因此個人學習只能裝虛擬機器,本文都以VMware Workstation為準,安裝CentOS7,具體的安裝此處不作過多介紹,只作需要用到的知識介紹。 VMware的安裝,裝好一個虛擬機器後利用複製虛擬機器的方式建立後面幾個虛擬機器,省
《資料演算法-Hadoop/Spark大資料處理技巧》讀書筆記(一)——二次排序
寫在前面: 在做直播的時候有同學問Spark不是用Scala語言作為開發語言麼,的確是的,從網上查資料的話也會看到大把大把的用Scala編寫的Spark程式,但是仔細看就會發現這些用Scala寫的文章
Hadoop大資料通用處理平臺
1.簡介 Hadoop是一款開源的大資料通用處理平臺,其提供了分散式儲存和分散式離線計算,適合大規模資料、流式資料(寫一次,讀多次),不適合低延時的訪問、大量的小檔案以及頻繁修改的檔案。 *Hadoop由HDFS、YARN、MapReduce組成。 Hadoop的特點:
Hadoop Streaming 做大資料處理詳解
-------------------------------------------------------------------------- 以下內容摘自寒小陽老師大資料課程內容 -----------------------------
大資料處理為何選擇Spark,而不是Hadoop
一.基礎知識1.SparkSpark是一個用來實現快速而通用的叢集計算的平臺。在速度方面,Spark擴充套件了廣泛使用的MapReduce計算模型,而且高效地支援更多計算模式,包括互動式查詢和流處理。Spark專案包含多個緊密整合的元件。Spark的核心是一個對由很多計算任務組成的、執行在多個工作機器或者是一
《資料演算法:Hadoop_Spark大資料處理技巧》艾提拉筆記.docx 第1章二次排序:簡介 19 第2章二次排序:詳細示例 42 第3章 Top 10 列表 54 第4章左外連線 96 第5
《資料演算法:Hadoop_Spark大資料處理技巧》艾提拉筆記.docx 第1章二次排序:簡介 19 第2章二次排序:詳細示例 42 第3章 Top 10 列表 54 第4章左外連線 96 第5章反轉排序 127 第6章
大資料處理基礎之利用hadoop寫的簡單mapreduce案例
案例: 需要處理的資料: 13877779999 bj zs 2145 13766668888 sh ls 1028 13766668888 sh ls 9987 13877779999 bj zs 5678 13544445555 sz ww 10577 1387777999
大資料處理的關鍵技術(二)
我們在上一篇文章中給大家介紹了大資料處理的兩個關鍵技術,分別是大資料的採集技術以及大資料的預處理技術。在這篇文章中我們會給大家介紹大資料儲存及管理以及大資料的展現和應用技術,希望這篇文章能夠給大家帶來幫助。 首先說說大資料的儲存以及管理技術,儲存的意義我們就不說了,是一個非常重要的技術,大資料儲存與管理
hadoop大資料工程師、資料開發工程師、資料倉庫工程師 面試題目分享
僅限於工作年限1-3年 一、HIVE崗 1.order by,distribute by,sortby的區別 點選開啟連結 2.內部表、外部表的區別及使用場景 點選開啟連結 3.講一下hadoop生態圈的元件,說一下你對hadoop的認識程度(需要理解並背下來) 點
(二)大資料處理:基於MapReduce的大圖劃分演算法綜述
【宣告:鄙人菜鳥一枚,寫的都是初級部落格,如遇大神路過鄙地,請多賜教;內容有誤,請批評指教,如有雷同,屬我偷懶轉運的,能給你帶來收穫就是我的部落格價值所在。】 今天一位同事跟我談起Hadoop,剛好這期部落格我也正準備寫點這方面相關的綜述,就跟他聊了聊。
《資料演算法-Hadoop/Spark大資料處理技巧》讀書筆記(四)——移動平均
移動平均:對時序序列按週期取其值的平均值,這種運算被稱為移動平均。典型例子是求股票的n天內的平均值。 移動平均的關鍵是如何求這個平均值,可以使用Queue來實現。 public class MovingAverageDriver { public
這份書單,給那些想學Hadoop大資料、人工智慧的人
一、簡單科普類 (文末附下載連結) 1、《人工智慧:李開復談AI如何重塑個人、商業與社會的未來圖譜2》 作者:李開復,王詠剛 推薦理由:文章寫得一般,但李開復和王永剛老師總結的還可以,算國內比較簡單的一本AI科普作品 圖書簡介:人工智慧被寫入2017年政府工作報告,智
搭建大資料處理叢集(Hadoop,Spark,Hbase)
搭建Hadoop叢集 配置每臺機器的 /etc/hosts保證每臺機器之間可以互訪。 120.94.158.190 master 120.94.158.191 secondMaster 1、建立hadoop使用者 先建立had