如何通過Scrapy簡單高效地部署和監控分散式爬蟲專案!這才是大牛
阿新 • • 發佈:2018-12-26

動圖展示
叢集多節點部署和執行爬蟲專案:
進群:960410445 即可獲取數十套PDF!
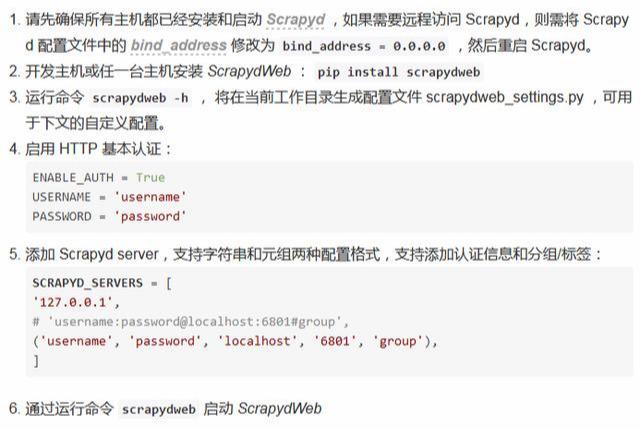
安裝和配置
私信菜鳥 菜鳥帶你玩爬蟲!007即可.
訪問 Web UI
通過瀏覽器訪問 http://127.0.0.1:5000,輸入認證資訊登入 。
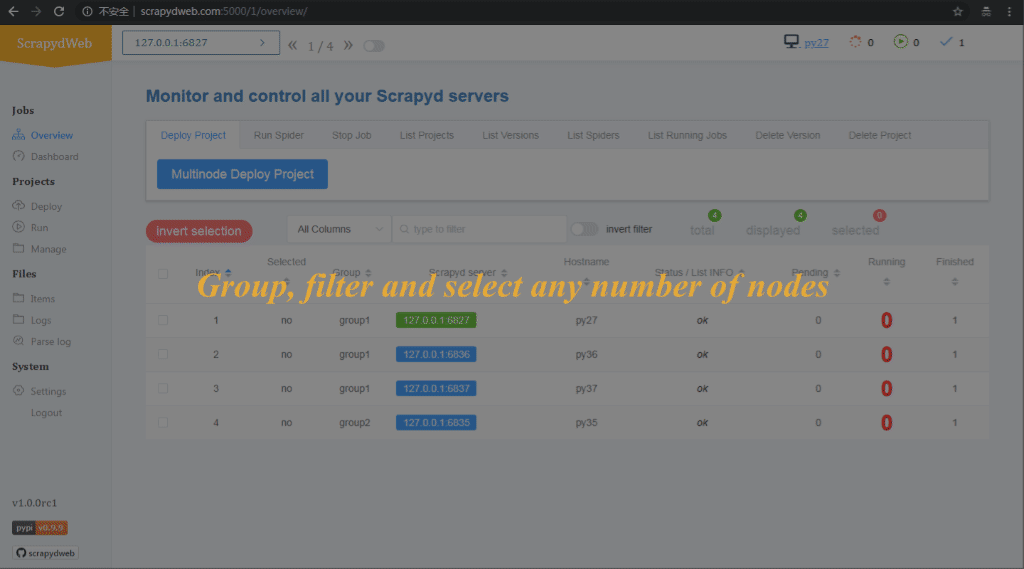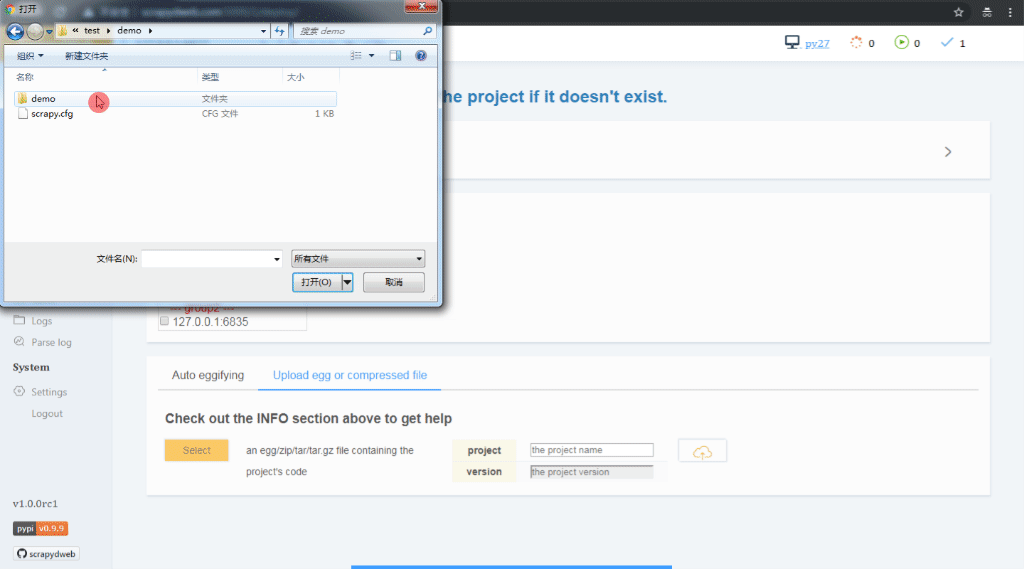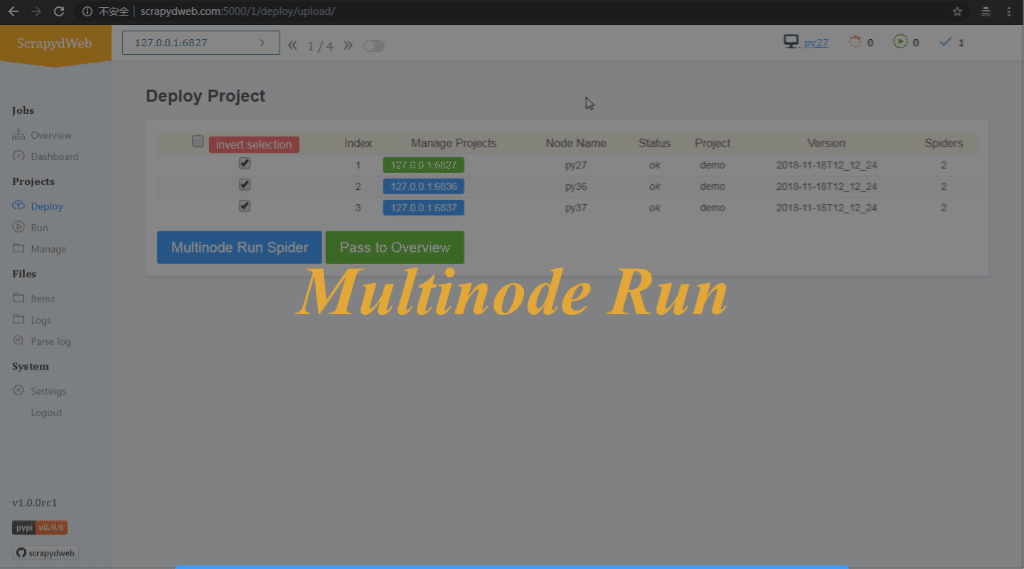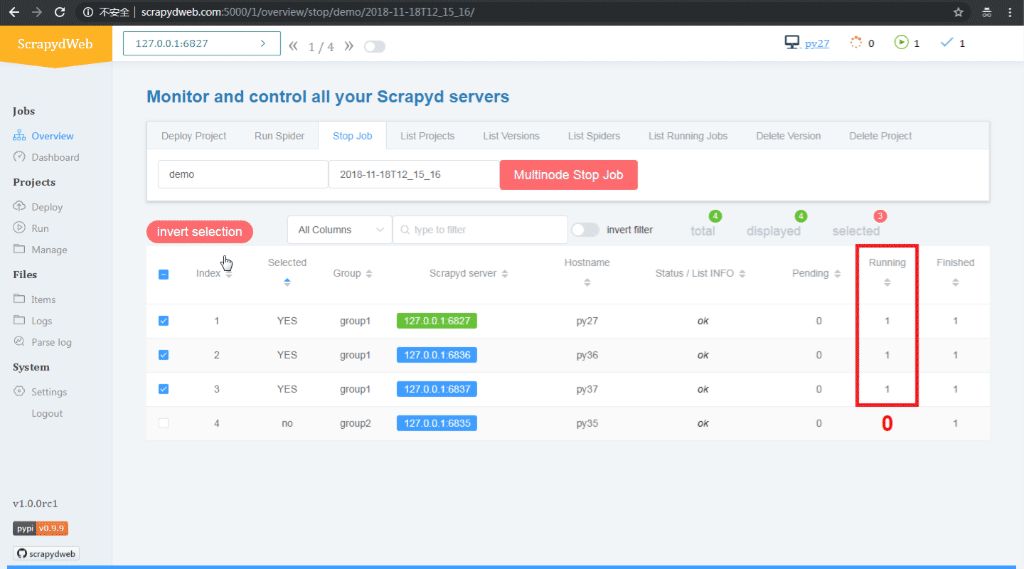
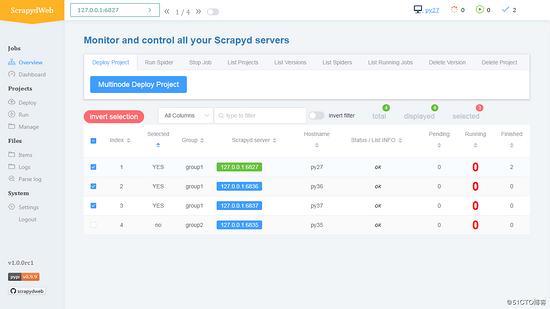
- Overview 頁面自動輸出所有 Scrapyd server 的執行狀態
- 通過分組和過濾可以自由選擇若干臺 Scrapyd server,呼叫 Scrapyd 提供的所有 HTTP JSON API,實現 一次操作,批量執行
部署專案
- 支援指定若干臺 Scrapyd server 部署專案
- 通過配置 SCRAPY_PROJECTS_DIR 指定 Scrapy 專案開發目錄, ScrapydWeb 將自動列出該路徑下的所有專案,選擇專案後即可自動打包和部署指定專案:
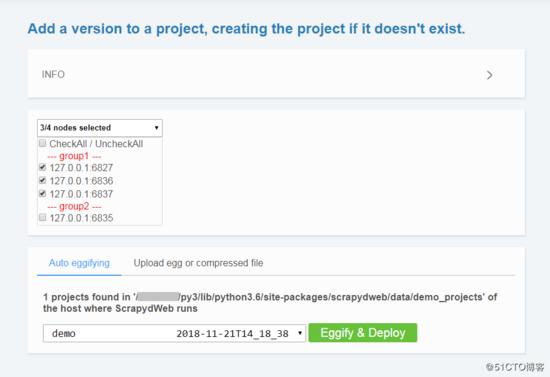
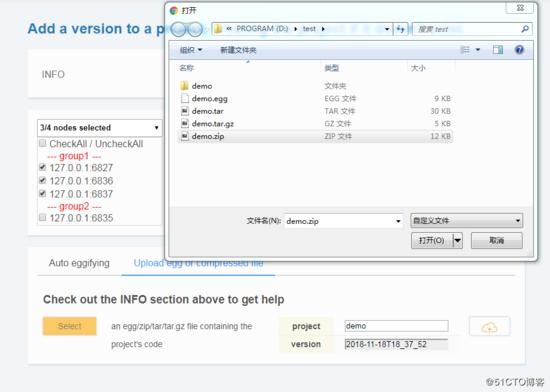
- 如果 ScrapydWeb 執行在遠端伺服器上,除了通過當前開發主機上傳常規的 egg 檔案,也可以將整個專案資料夾新增到 zip/tar/tar.gz 壓縮檔案後直接上傳即可,無需手動打包:)
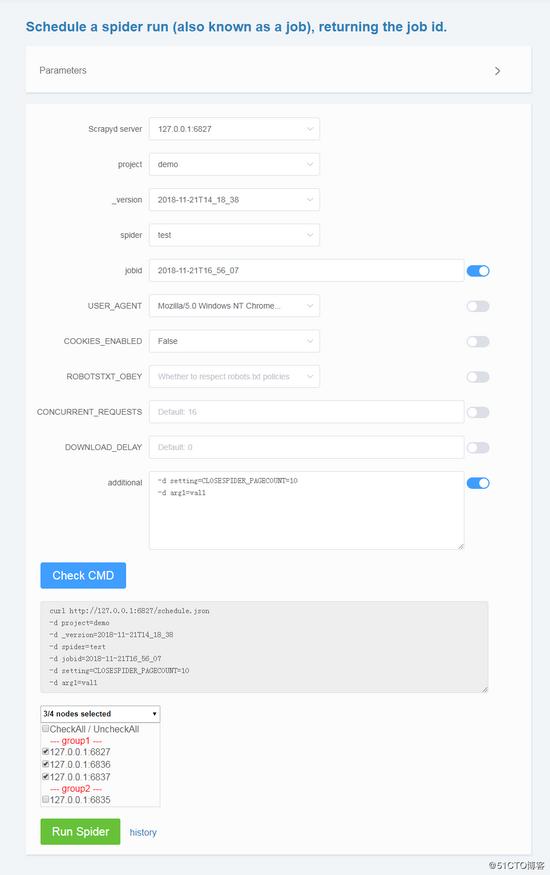
執行爬蟲
- 通過下拉框直接選擇 project,version 和 spider
- 支援傳入 Scrapy settings 和 spider arguments
- 同樣支援指定若干臺 Scrapyd server 執行爬蟲
日誌分析和視覺化
- 預設情況下, ScrapydWeb 將在後臺定時自動讀取和分析 Scrapy log 檔案並生成 Stats 頁面
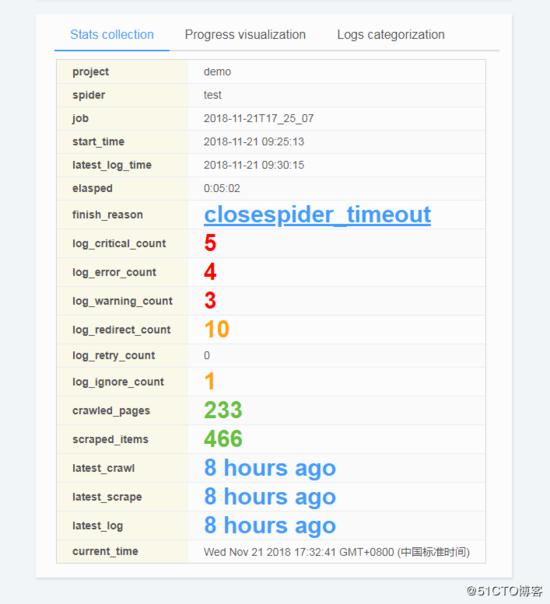
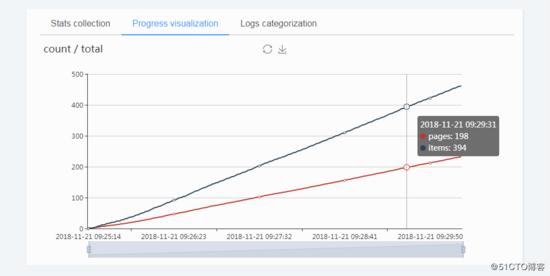
- 爬蟲進度視覺化
郵件通知
基於後臺定時讀取和分析 Scrapy log 檔案, ScrapydWeb 將在滿足特定觸發器時傳送通知郵件 ,郵件正文包含當前執行任務的統計資訊。
1.新增郵箱帳號:
SMTP_SERVER = 'smtp.qq.com' SMTP_PORT = 465 SMTP_OVER_SSL = True SMTP_CONNECTION_TIMEOUT = 10 FROM_ADDR = '[email protected]' EMAIL_PASSWORD = 'password' TO_ADDRS = ['[email protected]']
2.設定郵件工作時間和基本觸發器,以下示例代表:每隔1小時或某一任務完成時,並且當前時間是工作日的9點,12點和17點, ScrapydWeb 將會發送通知郵件。
EMAIL_WORKING_DAYS = [1, 2, 3, 4, 5] EMAIL_WORKING_HOURS = [9, 12, 17] ON_JOB_RUNNING_INTERVAL = 3600 ON_JOB_FINISHED = True
3.除了基本觸發器, ScrapydWeb 還提供了多種觸發器用於處理不同型別的 log ,包括 'CRITICAL', 'ERROR', 'WARNING', 'REDIRECT', 'RETRY' 和 'IGNORE'等。
LOG_CRITICAL_THRESHOLD = 3 LOG_CRITICAL_TRIGGER_STOP = True LOG_CRITICAL_TRIGGER_FORCESTOP = False # ... LOG_IGNORE_TRIGGER_FORCESTOP = False
以上示例代表:當發現3條或3條以上的 critical 級別的 log 時, ScrapydWeb 自動停止當前任務 ,如果當前時間在郵件工作時間內,則同時傳送通知郵件。
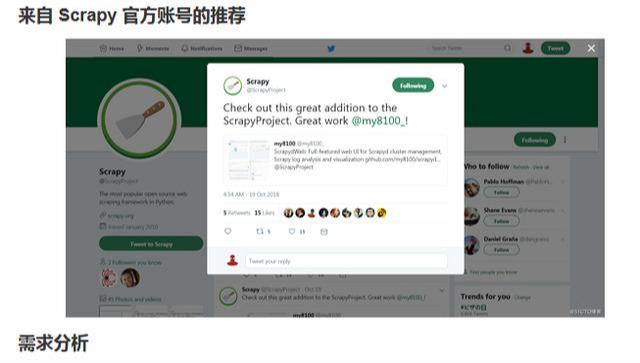
GitHub 開源
活捉幾隻官方大佬,趕緊前去圍觀吧,別忘了 Star 噢!
my8100 / scrapydweb