
邊學邊敲邊記爬蟲系列(六):CSS選擇器實戰訓練
阿新 • • 發佈:2018-12-26

一、 前言
上一篇文章Xpath實戰訓練中給大家講解並帶著大家實戰訓練了Xpath,爬取了伯樂線上文章的基本資訊,並且介紹scrapy裡的shell除錯模式使用,還是很實用的哈。
本篇將給大家講解CSS選擇器,以及一起實戰練習,牢記基礎語法知識。
二、CSS選擇器簡介
1.維基百科看CSS
層疊樣式表(英語:Cascading Style Sheets,簡寫CSS),又稱串樣式列表、級聯樣式表、串接樣式表、
階層式樣式表,一種用來為結構化文件(如HTML文件或XML應用)新增樣式(字型、間距和顏色等)的計算機
語言,由W3C定義和維護。目前最新版本是CSS2.1,為W3C的推薦標準。CSS3現在已被大部分現代瀏覽器支援
,而下一版的CSS4仍在開發中。 2.百度百科看CSS選擇器
要使用css對HTML頁面中的元素實現一對一,一對多或者多對一的控制,這就需要用到CSS選擇器。
HTML頁面中的元素就是通過CSS選擇器進行控制的。
每一條css樣式定義由兩部分組成,形式如下:[code] 選擇器{樣式} [/code] 在{}之前的部分就是“選擇
器”。 “選擇器”指明瞭{}中的“樣式”的作用物件,也就是“樣式”作用於網頁中的哪些元素。3.CSS選擇器常用型別
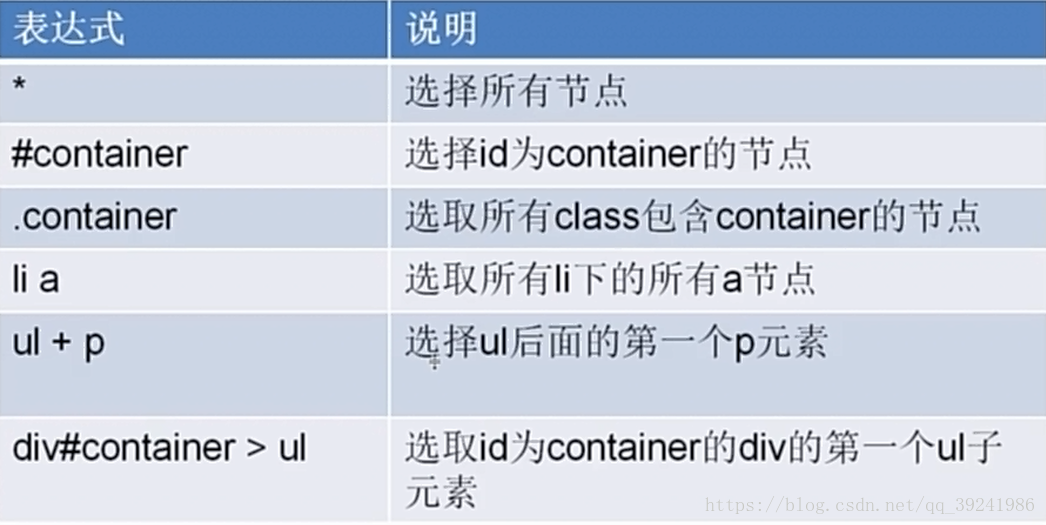
常用的5大CSS選擇器:
# 1.元素選擇器:又稱為標籤選擇器,根據標籤名來固定樣式作用範圍。
eg.對頁面所有p標籤樣式限定:
p{
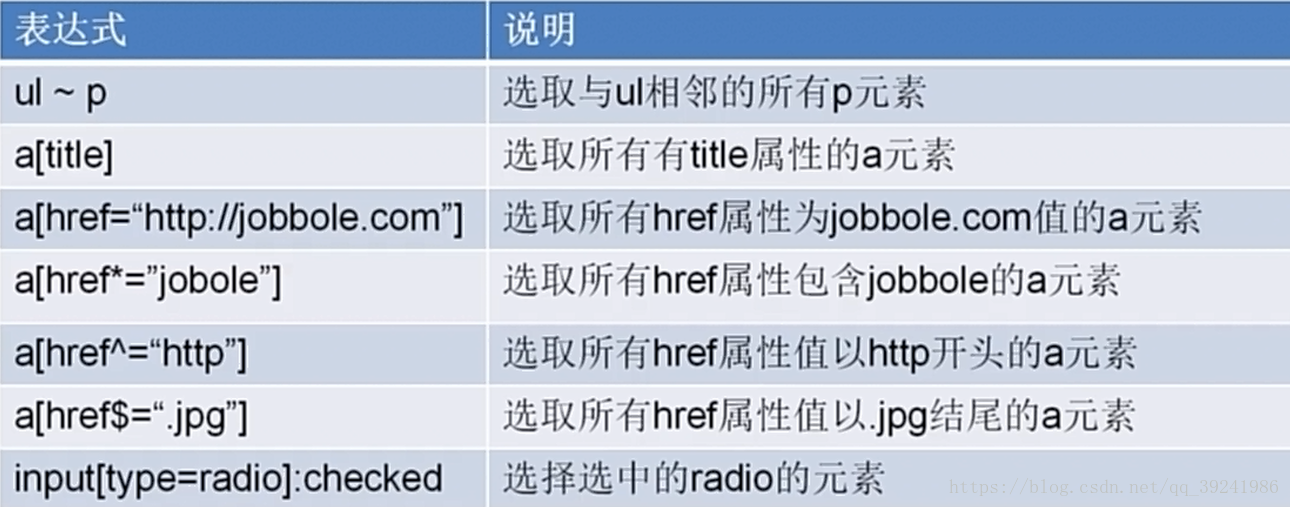
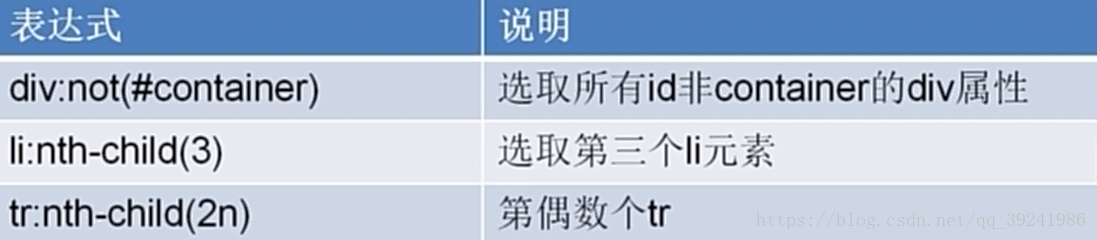
font-size:12 4.CSS選擇器常用語法
三、看程式碼,邊學邊敲邊記CSS選擇器
1.cmd下進入虛擬環境並且利用scrapy shell除錯
C:\Users\82055\Desktop>workon spiderenv
(spiderenv) C:\Users\82055\Desktop>scrapy shell http://python.jobbole.com/89196/2.在cmd下利用shell模式獲取文章資訊
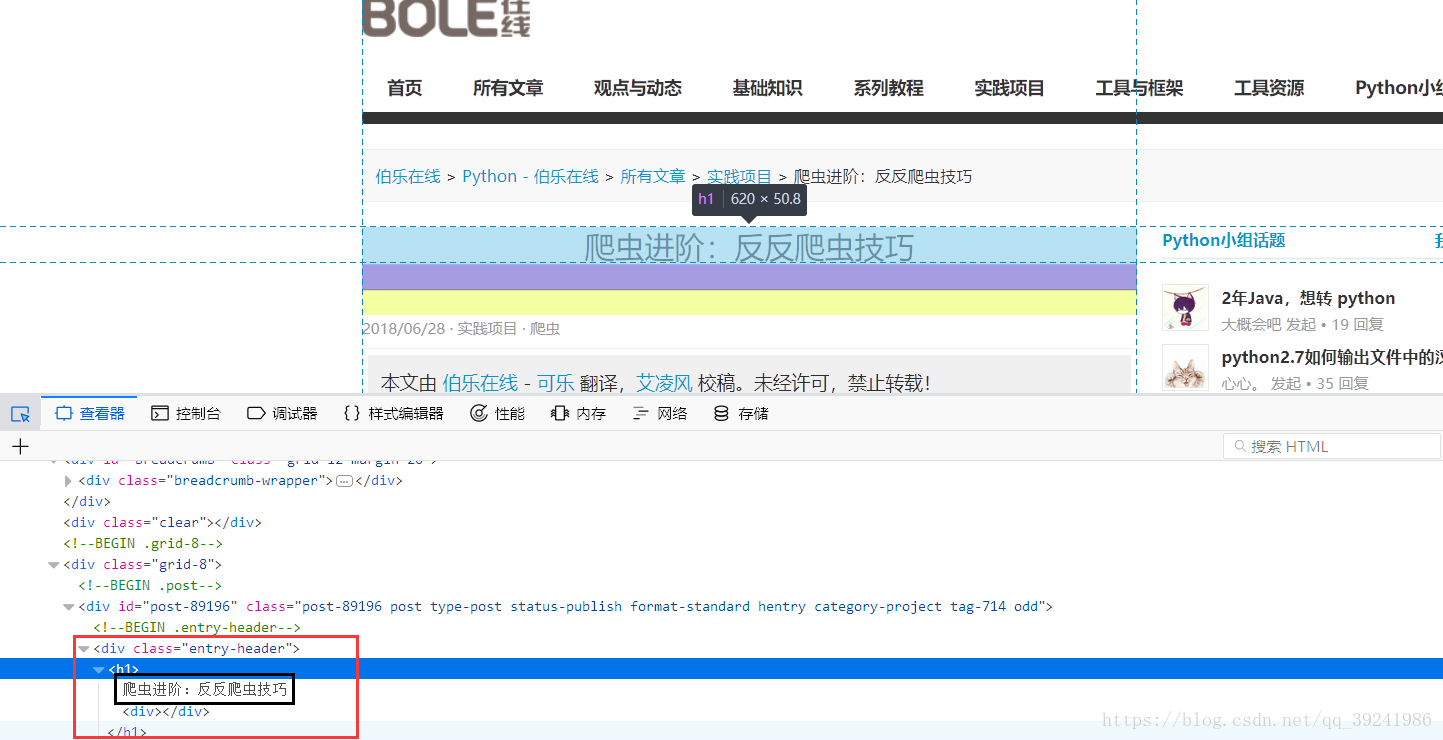
通過分析我們可以看出,文章標題是在class為entry-header的div下的h1標籤下(頁面查詢知entry-header類名全域性唯一)。
(2)通過類選擇器和後代選擇器綜合運用,取出文章標題
>>> response.css(".entry-header h1").extract()
['<h1>爬蟲進階:反反爬蟲技巧</h1>']我們發現文章標題並沒被完全取出,還是被h1標籤包裹著,有兩種方法獲取文字:
- 方法一:正則表示式獲取(麻煩)
>>> title = response.css(".entry-header h1").extract()[0]
>>> reg_01 = "<h1>(.*?)</h1>"
>>> title = re.findall(reg_01,title)[0]
>>> title
'爬蟲進階:反反爬蟲技巧'- 方法二:偽類選擇器(簡單)
>>> title = response.css(".entry-header h1 ::text").extract()[0]
>>> title
'爬蟲進階:反反爬蟲技巧'
# title = response.css(".entry-header h1 ::text").extract()[0]方法二是不是超級簡單,瞬間愛死CSS了。
(3)我們繼續獲取其他資料(複習鞏固一下CSS的用法)
- 獲取文章釋出時間
'''
預備小知識:
1.str.strip():可以去除str裡左右兩端的空格和\n,\r。
2.str.replace("a","b"):將str裡所有的a由b代替。
'''
# 文章釋出時間
>>> data_r = response.css(".entry-meta-hide-on-mobile::text").extract()[0]
>>> data_r
'\r\n\r\n 2018/06/28 · '
>>> data_r = data_r.strip()
>>> data_r
'2018/06/28 ·'
>>> data_time = data_r.replace('·','').strip()
>>> data_time
'2018/06/28'
# data_r = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip()
# data_time = data_r.replace('·','').strip()- 獲取文章點贊數、收藏數、評論數
# 點贊數:h10下id為89196votetotal,因為頁面內該id值唯一,故可以直接用id選擇器
>>> response.css("#89196votetotal::text").extract()[0]
'2'
# praise_number = int(response.css("#89196votetotal::text").extract()[0])
# 收藏數:a:nth-child(2)表示選取a標籤的第二個元素
>>> response.css("span.btn-bluet-bigger:nth-child(2)::text").extract()[0]
' 6 收藏'
>>> import re
>>> reg_02 = '.*(\d+).*'
>>> collection_str = response.css("span.btn-bluet-bigger:nth-child(2)::text").extract()[0]
>>> re.findall(reg_02,collection_str)[0]
'6'
# collection_str = response.css("span.btn-bluet-bigger:nth-child(2)::text").extract()[0]
# reg_02 = '.*(\d+).*'
# collection_number = int(re.findall(reg_02,collection_str)[0])
# 評論數:X先生這次選擇的又是沒有評論的,可謂良苦用心,只為了讓大家自己多動動腦袋,多想想,
# 哈哈哈
>>> response.css("span.hide-on-480::text").extract()[0]
' 評論'
# 如果有評論的話,和收藏數一樣,用正則表示式匹配數字即可,自己找篇有評論的試試吧~(4)詳解CSS選擇器獲取文章簡介、文章型別獲取
- 文章簡介獲取
從上面可以看到,文章的簡介內容放在了: class為entry的div的第二子類(blockquote標籤),
他(blockquote)的第一個子類(p標籤)中,所以我們推匯出圖上的CSS選擇器,程式碼如下:
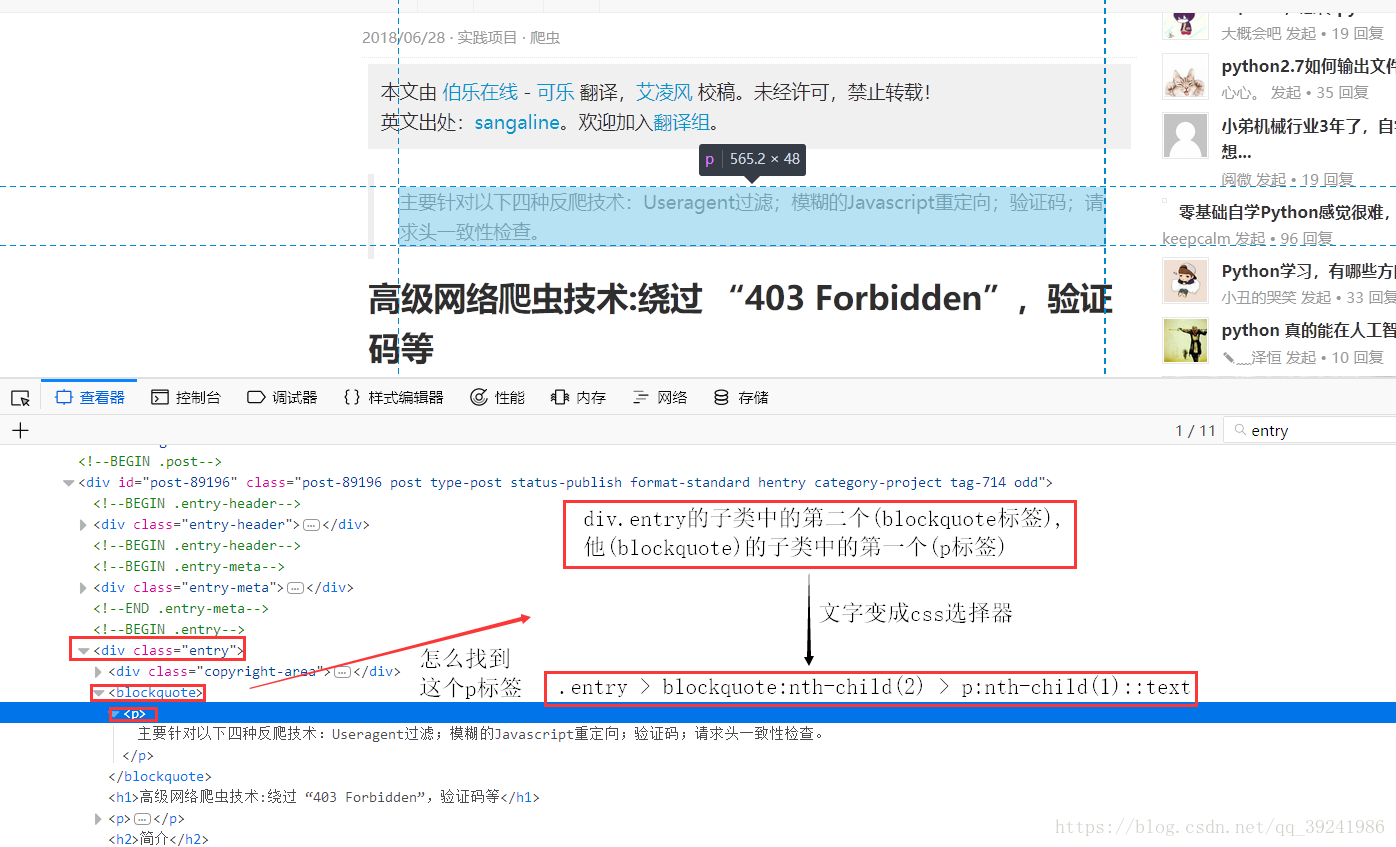
>>> response.css(".entry > blockquote:nth-child(2) > p:nth-child(1)::text").extract()[0]
'主要針對以下四種反爬技術:Useragent過濾;模糊的Javascript重定向;驗證碼;請求頭一致性檢查。'
# summary = response.css(".entry > blockquote:nth-child(2) > p:nth-child(1)::text").extract()[0]- 文章分類
從上面可以看出文章型別分為兩部分:前面+後面,前面型別(實踐專案):在class為entry-meta-hide-on-mobile的p標籤的後代中的第一個a標籤中,後面型別(爬蟲):在class為entry-meta-hide-on-mobile的p標籤的後代中的第二個a標籤中,所以我們推匯出圖上的CSS選擇器,程式碼如下:
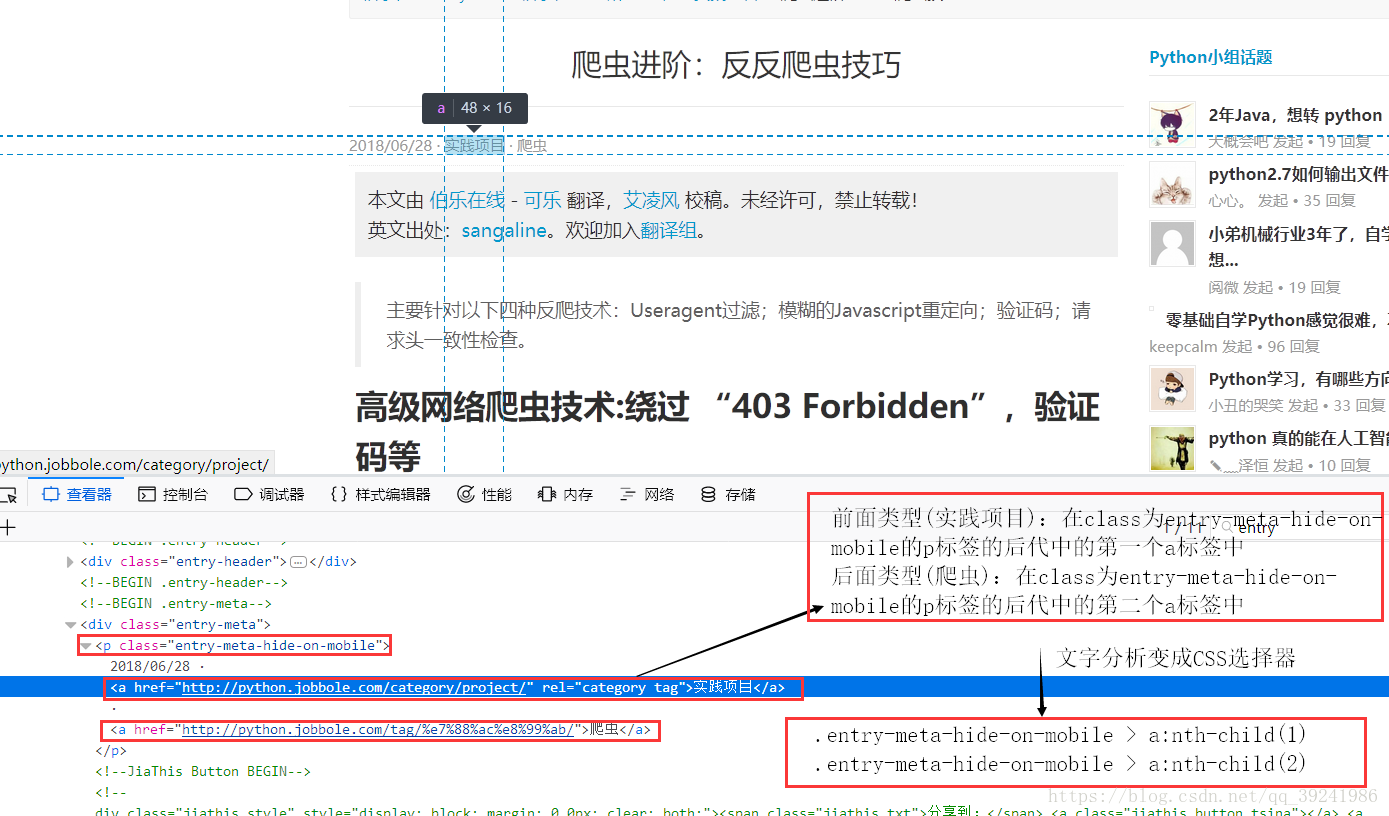
>>> response.css(".entry-meta-hide-on-mobile > a:nth-child(1)::text").extract()[0]
'實踐專案'
>>> response.css(".entry-meta-hide-on-mobile > a:nth-child(2)::text").extract()[0]
'爬蟲'
# type_01 = response.css(".entry-meta-hide-on-mobile > a:nth-child(1)::text").extract()[0]
# type_02 = response.css(".entry-meta-hide-on-mobile > a:nth-child(2)::text").extract()[0]
# article_type = type_01 + "·" + type_023.現在jobbole.py中的程式碼及執行結果
程式碼:
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://python.jobbole.com/89196/']
def parse(self, response):
# CSS選擇器實戰
# 文章標題
title = response.css(".entry-header h1 ::text").extract()[0]
# 釋出日期
data_r = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip()
data_time = data_r.replace('·','').strip()
# 文章分類
type_01 = response.css(".entry-meta-hide-on-mobile > a:nth-child(1)::text").extract()[0]
type_02 = response.css(".entry-meta-hide-on-mobile > a:nth-child(2)::text").extract()[0]
article_type = type_01 + "·" + type_02
# 文章簡介
summary = response.css(".entry > blockquote:nth-child(2) > p:nth-child(1)::text").extract()[0]
# 點贊數
praise_number = int( response.css("#89196votetotal::text").extract()[0])
# 收藏數
collection_str = response.css("span.btn-bluet-bigger:nth-child(2)::text").extract()[0]
reg_02 = '.*?(\d+).*'
collection_number = int(re.findall(reg_02,collection_str)[0])
print("文章標題:"+title)
print("釋出日期:"+data_time)
print("文章分類:"+article_type)
print("文章簡介:"+summary)
print("點贊數:"+str(praise_number))
print("收藏數:"+str(collection_number))執行結果:
文章標題:爬蟲進階:反反爬蟲技巧
釋出日期:2018/06/28
文章分類:實踐專案·爬蟲
文章簡介:主要針對以下四種反爬技術:Useragent過濾;模糊的Javascript重定向;驗證碼;請求頭一致性檢查。
點贊數:2
收藏數:6四、後言
學完這一期,大家也許覺得好像和之前Xpath實戰沒有什麼區別,但是我想告訴大家的是:Xpath和CSS選擇器的確有相同功能,但實現的原理是不同的,一般來說大家掌握一種就好了,那為什麼還要給大家介紹兩種呢?如果大家兩篇都有看的話,就會發現有些地方使用CSS選擇器會更加簡單,而有些地方又用Xpath似乎更好,而且對於前端有優勢的同學,使用CSS選擇器的話學起來就更比啦!
公佈個好訊息:公眾號:極簡XksA,讀者數破千啦~今天晚上20:00第一期贈書活動將出結果,九月初即將有第二期贈書活動,希望大家多多支援,互相學習交流,一起進步。
