
邊學邊敲邊記之爬蟲系列(九):Item+Pipeline資料儲存

一、寫在前面
好久沒更新了,快半個月了,也少有讀者催著更新,於是乎自己就拖啊,為公眾號出路想方設法,著實是有點迷失自我,廢話不多說了。
今天是爬蟲系列第9篇,上一篇Scrapy系統爬取伯樂線上中我們已經利用Scrapy獲取到了伯樂線上網站所有文章的基本資料,但我們沒有做儲存操作,本篇,我們就好好講講怎麼利用Scrapy框架知識進行儲存–Item做資料結構+Pipeline操作資料庫。
二、你不得不知道的 Knowledge
1. 本篇涉及到的英文單詞
1. item 英 [ˈaɪtəm] 美 [ˈaɪtəm] n.專案;條,條款;一則;一件商品(或物品) adv.又,同上 2.crawl 英 [krɔ:l] 美 [krɔl] vi.爬行;緩慢行進;巴結 n.緩慢的爬行;〈美俚〉跳舞,自由式游泳;養魚(龜)池 3.pipeline 英 [ˈpaɪplaɪn] 美 [ˈpaɪpˌlaɪn] n.管道;輸油管道;渠道,傳遞途徑 vt.(通過管道)運輸,傳遞;為…安裝管道 4.meta 英 ['metə] 美 ['metə] abbr.(Greek=after or beyond) (希臘語)在…之後或超出;[辨證法]元語言
2.Item作用
Item主要用於定義爬取的資料結構,自己指定欄位儲存資料,統一處理,建立Item需要繼承scrapy.Item類,並且定義型別為scrapy.Field,不用區分資料型別,資料型別取決於賦值時原始資料的資料型別,它的使用方法和字典類似。
3.Pipeline作用
當Item在Spider中被收集之後,它將會被傳遞到Item Pipeline,Pipeline主要作用是將return的items寫入到資料庫、檔案等持久化模組。
4.Scrapy中Request函式的mate引數作用
Request中meta引數的作用是傳遞資訊給下一個函式,使用過程可以理解成把需要傳遞的資訊賦值給這個叫meta的變數,但meta只接受字典型別的賦值,因此要把待傳遞的資訊改成"字典”的形式,如果想在下一個函式中取出 value,只需得到上一個函式的meta[key]即可。
三、看程式碼,邊學邊敲邊記Scrapy Item和Pipeline應用
1. 目前專案目錄
2.前情回顧
實在是本系列上一篇(Scrapy系統爬取伯樂線上)距離現在太遠久了,簡單和大家提醒一下上一篇我們做了什麼吧:
1.批量、翻頁爬取
2.已經爬取到資料基本介紹,見下面資料表
| 變數中文名 | 變數名 | 值型別 |
|---|---|---|
| 文章標題 | title | str |
| 釋出日期 | create_time | str |
| 文章分類 | article_type | str |
| 點贊數 | praise_number | int |
| 收藏數 | collection_number | int |
| 評論數 | comment_number | int |
3.在Item.py中新建一個JobboleArticleItem類,用來存放文章資訊
class JobboleArticleItem(scrapy.Item):
front_img = scrapy.Field() # 封面圖
title = scrapy.Field() # 標題
create_time = scrapy.Field() # 釋出時間
url = scrapy.Field() # 當前頁url
article_type =scrapy.Field() # 文章分類
praise_number = scrapy.Field() # 點贊數
collection_number = scrapy.Field() # 收藏數
comment_number = scrapy.Field() # 評論數
4.增加文章封面圖獲取
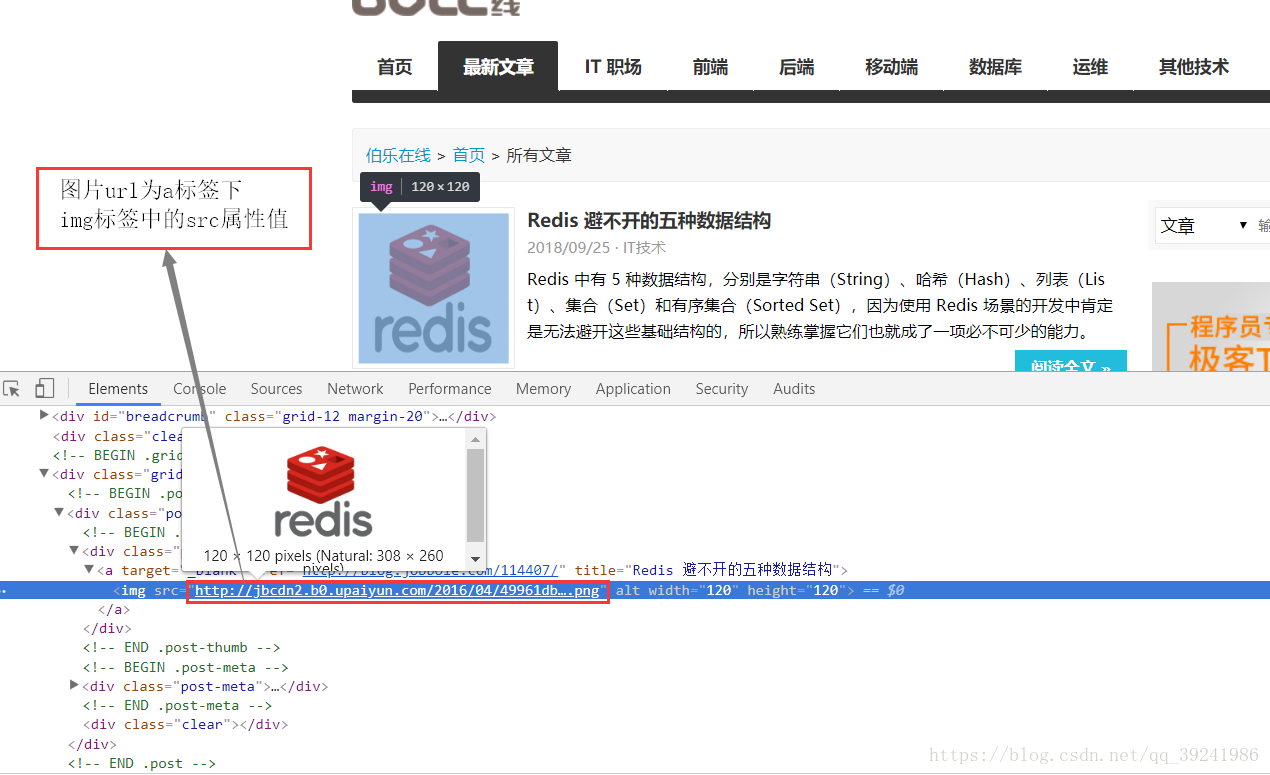
(1)頁面分析
(2)jobbole.py中修改parse函式
我們通過Request函式的mate引數傳遞獲取到的image_url,
def parse(self, response):
# 1.獲取單頁面a標籤內容,返回Selector物件
post_urls = response.xpath('//*[@id="archive"]/div/div[1]/a')
# 2.獲取文章url、封面圖url、下載頁面內容和圖片
for post_node in post_urls:
# 2.1 獲取單頁面文章url
image_url = post_node.css("img::attr(src)").extract_first("")
# 2.2 獲取單頁面文章url
post_url = post_node.css("::attr(href)").extract_first("")
# 2.3 提交下載
yield Request(url= parse.urljoin(response.url,post_url),meta={"front_img":image_url},callback= self.parse_detail)
# 3.獲取翻頁url和翻頁下載
next_url = response.css(".next::attr(href)").extract()
if next_url != []:
next_url = next_url[0]
yield Request(url= parse.urljoin(response.url,next_url),callback= self.parse)
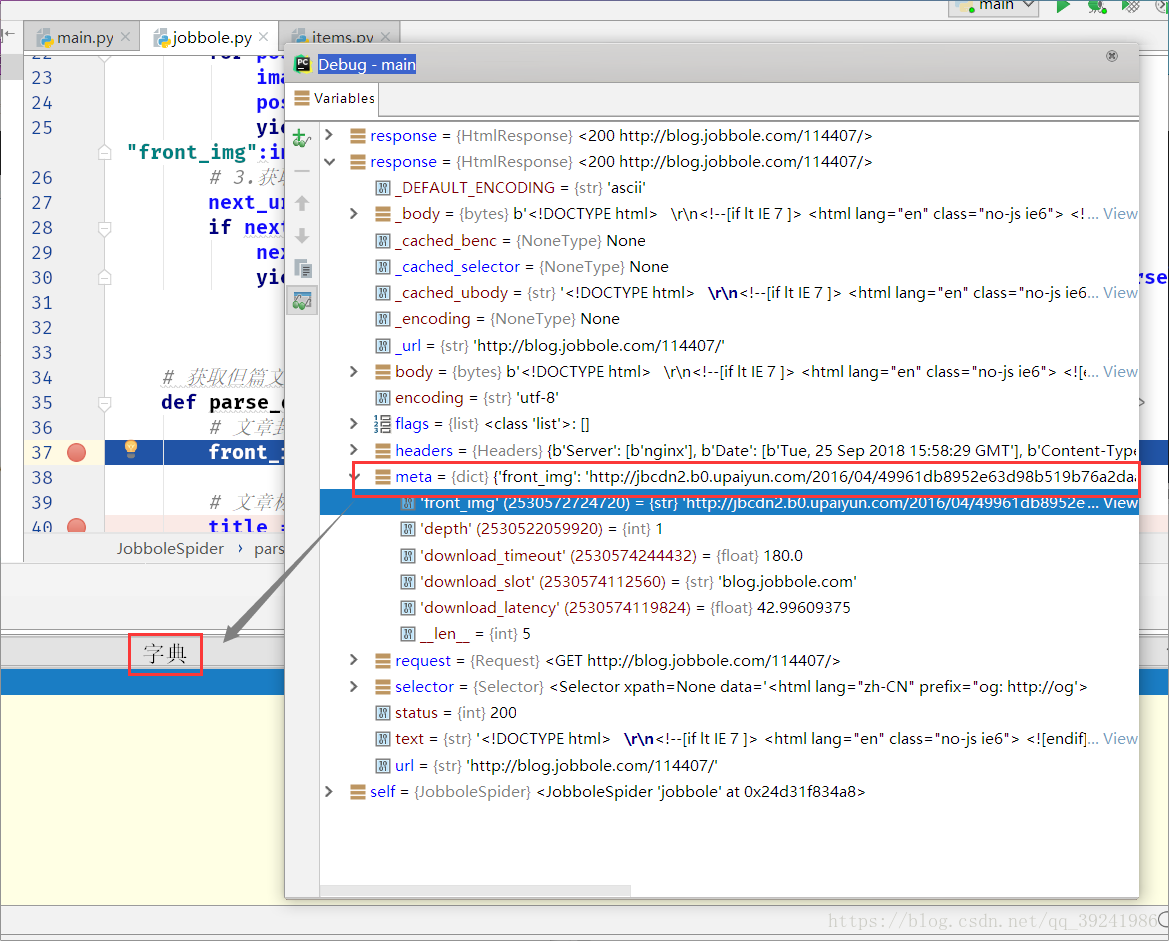
(3)Debug除錯
Debug結果我們可以看出,mate的值成功隨response傳入到parse_detail函式中,那麼我們就可以在parse_detail函式中解析獲取到front_img。
(4)補全parse_detail函式程式碼
# 初始化一個item物件
article_item = JobboleArticleItem()
# 文章封面圖
front_img = response.mate.get("front_img","")
·
·
·
# 資料儲存到Item中
article_item['title'] = title
article_item['create_time'] = create_time
article_item['article_type'] = article_type
article_item['praise_number'] = praise_number
article_item['collection_number'] = collection_number
article_item['comment_number'] = comment_number
article_item['front_img'] = front_img
article_item['url'] = response.url
# 將item傳遞到Pipeline中
yield article_item
至此Item相關程式碼功能就寫好了,後面我們對在Pipeline中進行實際資料儲存操作。
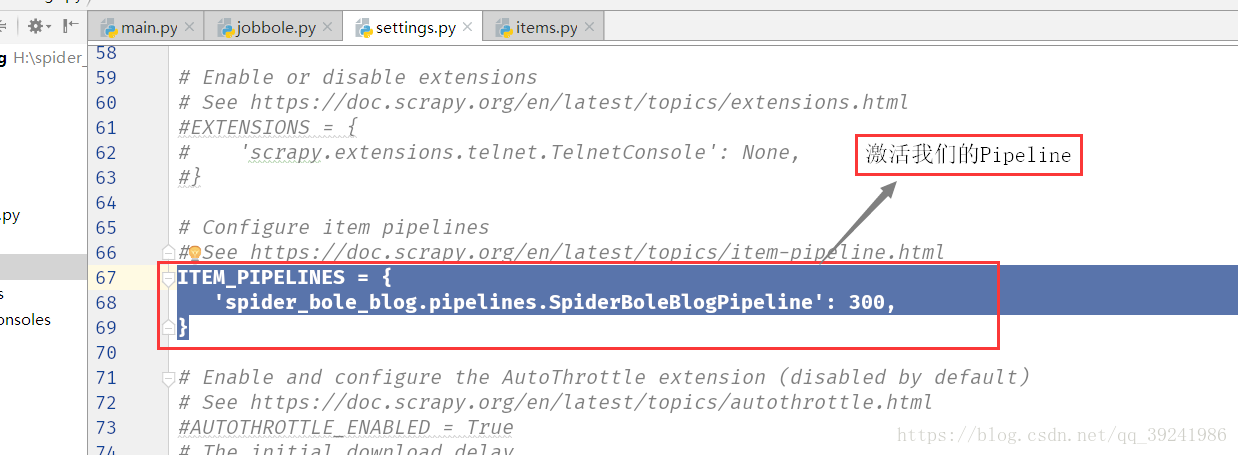
(5)啟用Pipeline
修改setting.py,啟用Pipeline
在setting.py檔案下找到第67-69行,去除註釋即可。(或者直接Ctrl+F 搜尋ITEM_PIPELINES,找到相應位置,去除註釋即可)
ITEM_PIPELINES = {
key : value
}
key : 表示pipeline中定義的類路徑
value : 表示這個pipeline執行的優先順序,
value值越小,從jobbole.py傳過
來的Item越先進入這個Pipeline。
上面操作我們就激活了Pipeline,接下來我們可以Debug一下,看看效果:
果然,Debug後Item傳入了Pipeline,後面我們可以處理資料、儲存資料。
(6)在Pipeline 中進行資料儲存操作(MySql)

- 建立表格
CREATE TABLE `bole_db`.`article` (
`id` INT UNSIGNED NOT NULL AUTO_INCREMENT,
`title` VARCHAR(100) NULL,
`create_time` VARCHAR(45) NULL,
`article_type` VARCHAR(50) NULL,
`praise_number` INT NULL,
`collection_number` INT NULL,
`comment_number` INT NULL,
`url` VARCHAR(100) NULL,
`front_img` VARCHAR(150) NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8
COMMENT = '伯樂線上文章資訊';
- 儲存資料
在Pipelien中建立一個數據庫操作類,並配置到setting中。
pipeline.py中:
class MysqlPipeline(object):
def __init__(self):
# 資料庫連線
self.conn = pymysql.connect(host="localhost", port=3306, user="root", password="root", charset="utf8",
database="bole_db")
self.cur = self.conn.cursor()
# 插入資料
def sql_insert(self,sql):
self.cur.execute(sql)
self.conn.commit()
def process_item(self, item, spider):
# 存入mysql資料庫
sql_word = "insert into article (title,create_time,article_type,praise_number,collection_number,comment_number,url,front_img) values ('{0}','{1}','{2}','{3}','{4}','{5}','{6}','{7}','{8}')".format(item["title"],item["create_time"],item["article_type"],item["praise_number"],item["collection_number"],item["comment_number"],item["url"],item["front_img"])
self.sql_insert(sql_word)
return item
setting.py中:
# 第67行開始
ITEM_PIPELINES = {
'spider_bole_blog.pipelines.SpiderBoleBlogPipeline': 300,
'spider_bole_blog.pipelines.MysqlPipeline':100
}
- 執行結果
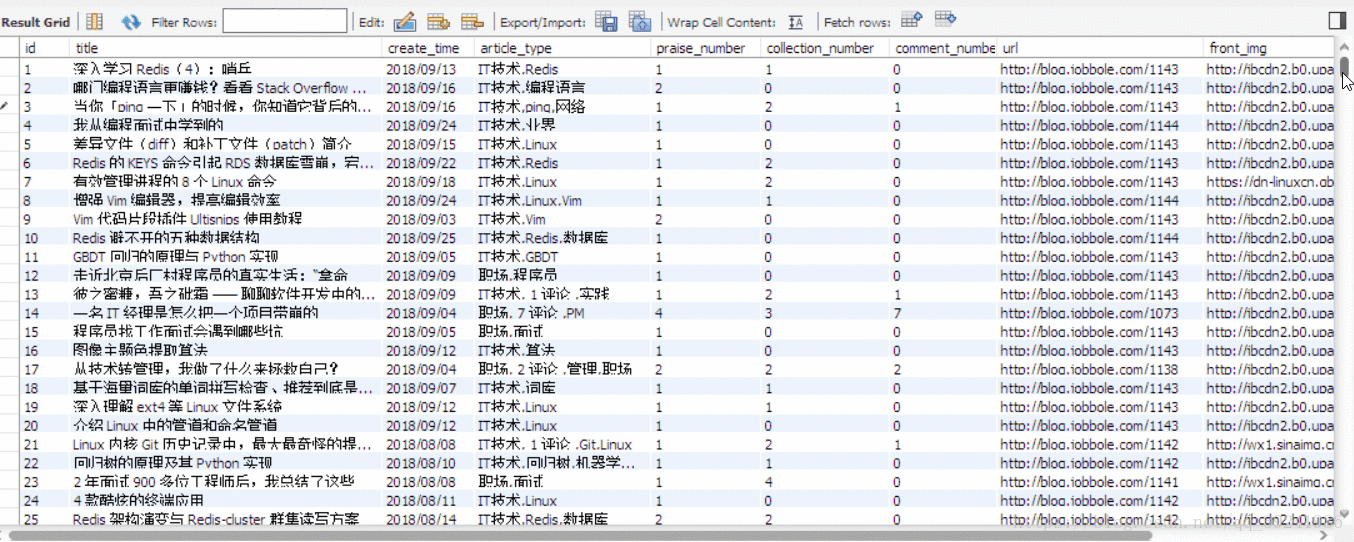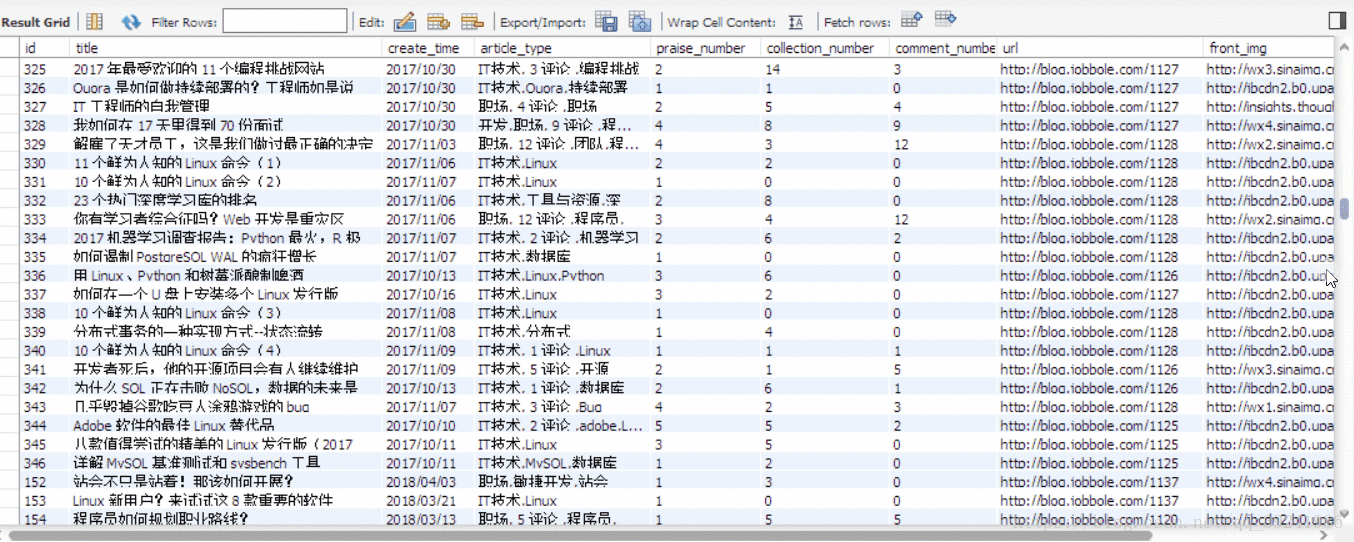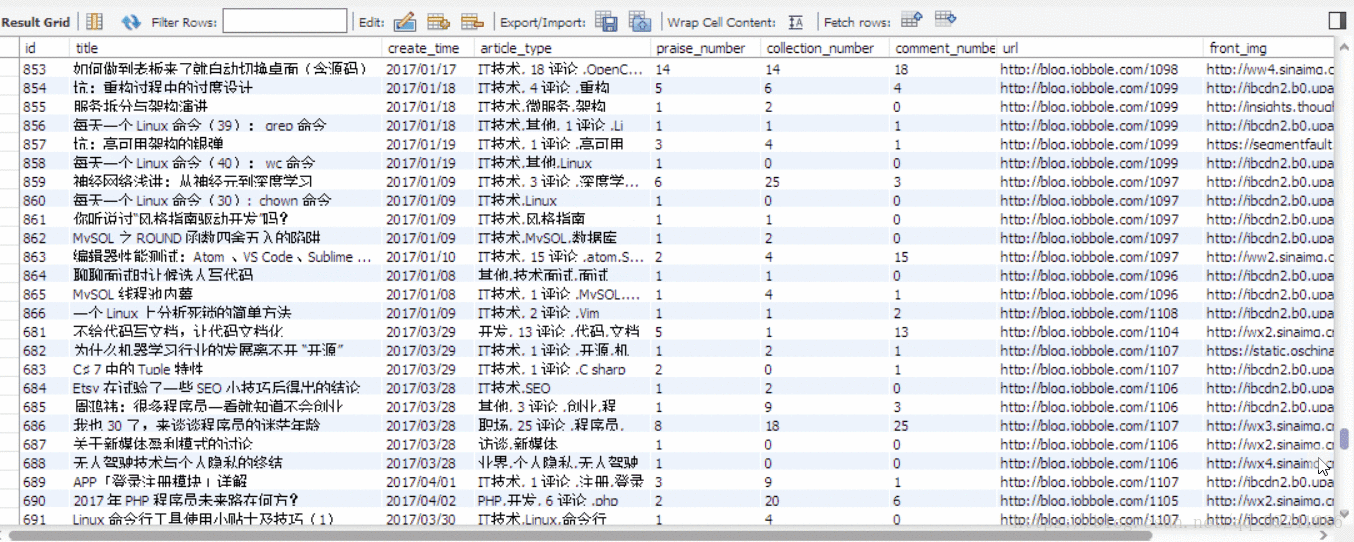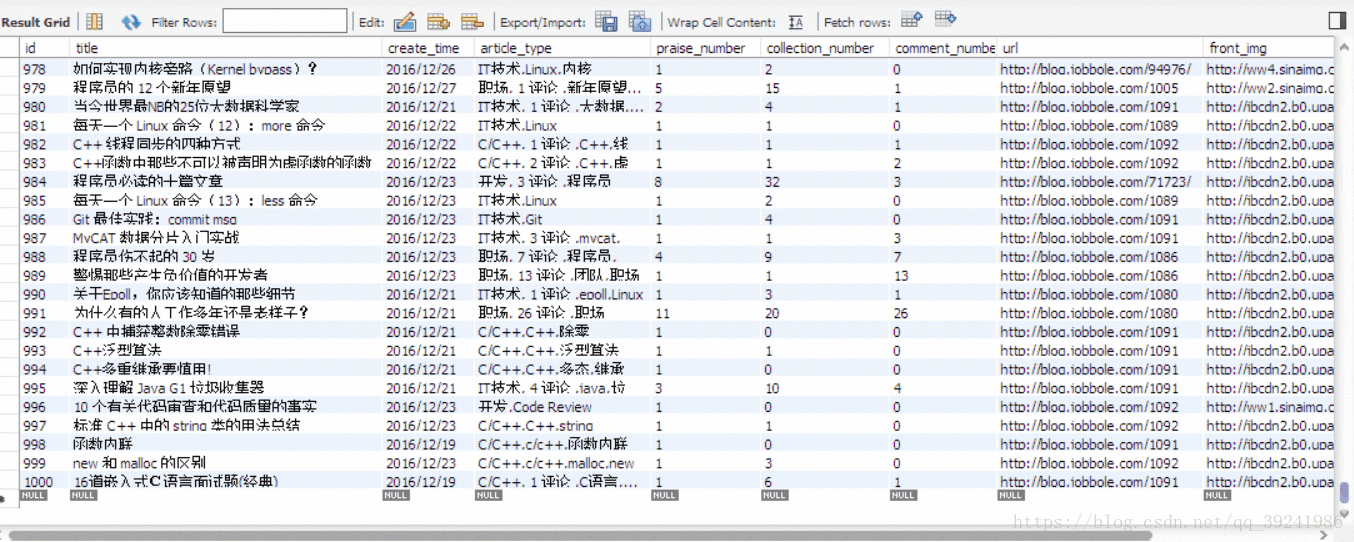
我僅僅運行了1分鐘,就爬下來並存儲了1000條資料,而且沒有被反爬掉,可以看出Scrapy框架的強大。
四、後言
這個系列的確是太久沒更新了,給大家回顧一下之前講了些什麼吧
Scrapy學習專欄