
zab協議理解
阿新 • • 發佈:2018-12-26
- ZAB協議是專門為zookeeper實現分散式協調功能而設計。zookeeper主要是根據ZAB協議是實現分散式系統資料一致性。
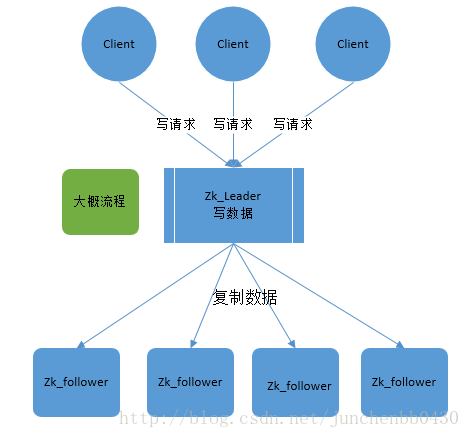
- zookeeper根據ZAB協議建立了主備模型完成zookeeper叢集中資料的同步。這裡所說的主備系統架構模型是指,在zookeeper叢集中,只有一臺leader負責處理外部客戶端的事物請求(或寫操作),然後leader伺服器將客戶端的寫操作資料同步到所有的follower節點中。
- ZAB的協議核心是在整個zookeeper叢集中只有一個節點即Leader將客戶端的寫操作轉化為事物(或提議proposal)。Leader節點再資料寫完之後,將向所有的follower節點發送資料廣播請求(或資料複製),等待所有的follower節點反饋。在ZAB協議中,只要超過半數follower節點反饋OK,Leader節點就會向所有的follower伺服器傳送commit訊息。即將leader節點上的資料同步到follower節點之上。
- ZAB協議中主要有兩種模式,第一是訊息廣播模式;第二是崩潰恢復模式
訊息廣播模式
- 在zookeeper叢集中資料副本的傳遞策略就是採用訊息廣播模式。zookeeper中資料副本的同步方式與二階段提交相似但是卻又不同。二階段提交的要求協調者必須等到所有的參與者全部反饋ACK確認訊息後,再發送commit訊息。要求所有的參與者要麼全部成功要麼全部失敗。二階段提交會產生嚴重阻塞問題。
- ZAB協議中Leader等待follower的ACK反饋是指”只要半數以上的follower成功反饋即可,不需要收到全部follower反饋”
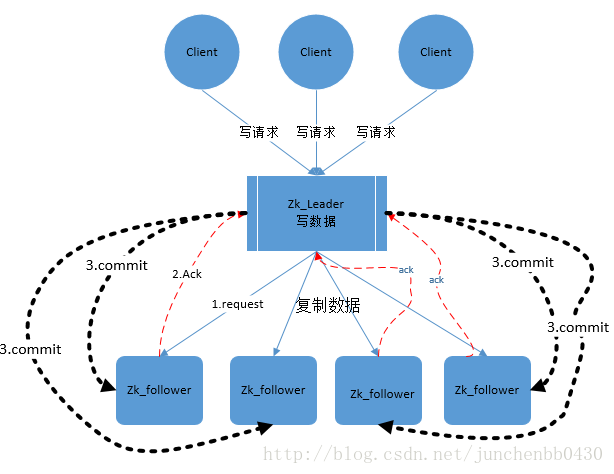
- 圖中展示了訊息廣播的具體流程圖
- zookeeper中訊息廣播的具體步驟如下:
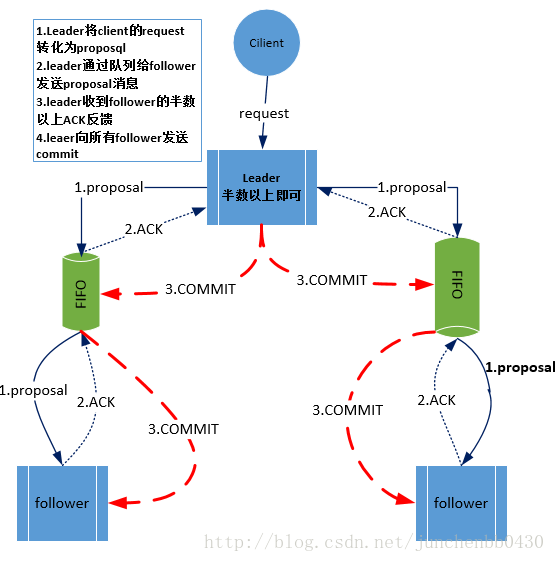
4.1. 客戶端發起一個寫操作請求
4.2. Leader伺服器將客戶端的request請求轉化為事物proposql提案,同時為每個proposal分配一個全域性唯一的ID,即ZXID。
4.3. leader伺服器與每個follower之間都有一個佇列,leader將訊息傳送到該佇列
4.4. follower機器從佇列中取出訊息處理完(寫入本地事物日誌中)畢後,向leader伺服器傳送ACK確認。
4.5. leader伺服器收到半數以上的follower的ACK後,即認為可以傳送commit
4.6. leader向所有的follower伺服器傳送commit訊息。 - zookeeper採用ZAB協議的核心就是隻要有一臺伺服器提交了proposal,就要確保所有的伺服器最終都能正確提交proposal。這也是CAP/BASE最終實現一致性的一個體現。
- leader伺服器與每個follower之間都有一個單獨的佇列進行收發訊息,使用佇列訊息可以做到非同步解耦。leader和follower之間只要往佇列中傳送了訊息即可。如果使用同步方式容易引起阻塞。效能上要下降很多。
崩潰恢復
- zookeeper叢集中為保證任何所有程序能夠有序的順序執行,只能是leader伺服器接受寫請求,即使是follower伺服器接受到客戶端的請求,也會轉發到leader伺服器進行處理。
- 如果leader伺服器發生崩潰,則zab協議要求zookeeper叢集進行崩潰恢復和leader伺服器選舉。
- ZAB協議崩潰恢復要求滿足如下2個要求:
3.1. 確保已經被leader提交的proposal必須最終被所有的follower伺服器提交。
3.2. 確保丟棄已經被leader出的但是沒有被提交的proposal。 - 根據上述要求,新選舉出來的leader不能包含未提交的proposal,即新選舉的leader必須都是已經提交了的proposal的follower伺服器節點。同時,新選舉的leader節點中含有最高的ZXID。這樣做的好處就是可以避免了leader伺服器檢查proposal的提交和丟棄工作。
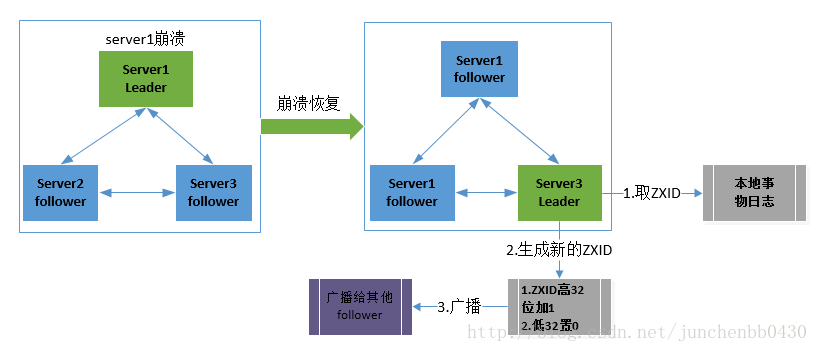
- leader伺服器發生崩潰時分為如下場景:
5.1. leader在提出proposal時未提交之前崩潰,則經過崩潰恢復之後,新選舉的leader一定不能是剛才的leader。因為這個leader存在未提交的proposal。
5.2 leader在傳送commit訊息之後,崩潰。即訊息已經發送到佇列中。經過崩潰恢復之後,參與選舉的follower伺服器(剛才崩潰的leader有可能已經恢復執行,也屬於follower節點範疇)中有的節點已經是消費了佇列中所有的commit訊息。即該follower節點將會被選舉為最新的leader。剩下動作就是資料同步過程。
資料同步
- 在zookeeper叢集中新的leader選舉成功之後,leader會將自身的提交的最大proposal的事物ZXID傳送給其他的follower節點。follower節點會根據leader的訊息進行回退或者是資料同步操作。最終目的要保證叢集中所有節點的資料副本保持一致。
- 資料同步完之後,zookeeper叢集如何保證新選舉的leader分配的ZXID是全域性唯一呢?這個就要從ZXID的設計談起。
2.1 ZXID是一個長度64位的數字,其中低32位是按照數字遞增,即每次客戶端發起一個proposal,低32位的數字簡單加1。高32位是leader週期的epoch編號,至於這個編號如何產生(我也沒有搞明白),每當選舉出一個新的leader時,新的leader就從本地事物日誌中取出ZXID,然後解析出高32位的epoch編號,進行加1,再將低32位的全部設定為0。這樣就保證了每次新選舉的leader後,保證了ZXID的唯一性而且是保證遞增的。
ZAB協議原理
- ZAB協議要求每個leader都要經歷三個階段,即發現,同步,廣播。
- 發現:即要求zookeeper叢集必須選擇出一個leader程序,同時leader會維護一個follower可用列表。將來客戶端可以這follower中的節點進行通訊。
- 同步:leader要負責將本身的資料與follower完成同步,做到多副本儲存。這樣也是體現了CAP中高可用和分割槽容錯。follower將佇列中未處理完的請求消費完成後,寫入本地事物日誌中。
- 廣播:leader可以接受客戶端新的proposal請求,將新的proposal請求廣播給所有的follower。
Zookeeper設計目標
- zookeeper作為當今最流行的分散式系統應用協調框架,採用zab協議的最大目標就是建立一個高可用可擴充套件的分散式資料主備系統。即在任何時刻只要leader發生宕機,都能保證分散式系統資料的可靠性和最終一致性。
- 深刻理解ZAB協議,才能更好的理解zookeeper對於分散式系統建設的重要性。以及為什麼採用zookeeper就能保證分散式系統中資料最終一致性,服務的高可用性。