
Zookeeper-ZAB協議
1.ZAB協議的核心
在一個zk叢集中,只有一個leader節點可以將客戶端的寫請求轉化為事務或提議proposal,leader節點寫完資料庫,
把proposal訊息傳送到leader和follower直接的通訊佇列中去,follower節點處理完leader節點發送的proposal訊息後,
給leader節點返回ACK訊息確認,當leader節點接收到半數以上的follower返回的ACK訊息後,leader節點就向所有的
follower節點發送commit訊息。
2.ZAB協議的兩種模式
1.崩潰恢復模式
2.訊息廣播模式
3.zookeeper 中的ZXID
1.為了保證zookeeper事務的順序一致性,zxid採用的時遞增的事id(zxid)來標識事務
2.zxid有64位組成
---高32位是epoch編號(用來標識leader的週期變化,即每次新選舉出leader,epoch編號自動加1)
---低32位用於遞增計數 (每次新選出leader時,清零)
4.崩潰恢復模式
1.崩潰恢復模式需要解決兩個問題
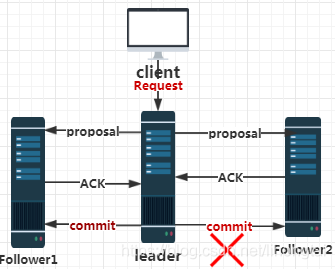
A:已經被處理的訊息不能丟失-產生的原因如下圖所示
當leader節點在向follower節點發送commit訊息的時候,只有follower1 訊息傳送成功後,leader節點直接崩潰,
還沒有向follower2節點發送commit訊息。
也就是說當zk叢集恢復使用(選出新的leader)後,老leader節點最後提交到follower1節點的訊息不能丟失
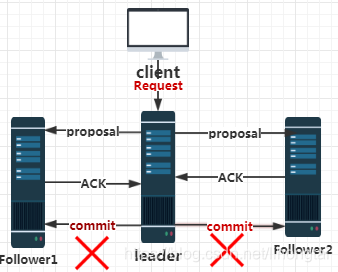
B:被丟棄的訊息不能再次出現-客戶端只能重新發一次請求 -產生的原因如下圖所示
當leader節點向所有的follower節點發送commit訊息之前,leader節點直接崩潰,也就是說,
所有的follower節點都沒有同步到leader節點最後崩潰前處理的客戶端請求的資料。
就是說當老leader節點可以使用,加入新的leader領導的叢集中作為follower節點使用的時候,
老leader節點最後處理的客戶端請求需要丟棄
2 .崩潰恢復的解決方案
A:針對第一個問題,選出叢集中擁有最高zxid編號事務proposal機器之一,作為新的leader節點
B:針對第二個問題,當老的leader作為新的follower節點加入叢集時,新的leader把老的leader中所
有舊的epoch號標記的未被提交的事務proposal清除
5.訊息廣播模式
1.訊息廣播模式流程圖
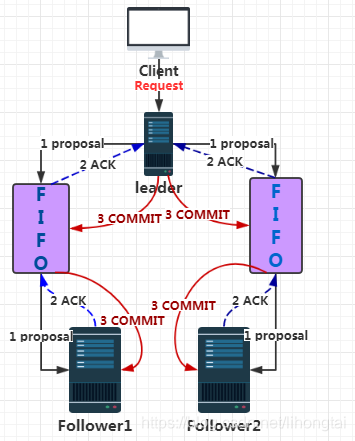
2.訊息廣播模式的步驟
- 客戶端發起一個寫操作請求
- Leader伺服器將客戶端的request請求轉化為事物proposql提案,同時為每個proposal分配一個全域性唯一的ID,即ZXID。
- leader伺服器與每個follower之間都有一個佇列,leader將訊息傳送到該佇列
- follower機器從佇列中取出訊息處理完(寫入本地事物日誌中)畢後,向leader伺服器傳送ACK確認。
- leader伺服器收到半數以上的follower的ACK後,即認為可以傳送commit
- leader向所有的follower伺服器傳送commit訊息。
3. leader節點和每個follower節點之間都有一個佇列進行收發訊息
使用佇列訊息可以做到非同步解耦。leader和follower之間只要往佇列中傳送了訊息即可。
如果使用同步方式容易引起阻塞。效能上要下降很多。
6.ZAB協議的原理-每個leader都要經歷3個階段
1.發現 -即每個ZK叢集必須選舉出一個leader節點;每個leader節點維護一個follower列表,將來客戶端可以和這些節點通訊
2.同步 - 即leader節點負責把本身的資料同步到所有的follower節點上去,做到多副本儲存;follower將佇列中未處理完的
請求消費完成後,寫入本地事物日誌中。
3.廣播 - 即leader可以接受客戶端新的proposal請求,將新的proposal請求廣播給所有的follower
7.zookeeper滿足CAP理論的CP理論
原因:可以從ZAB協議的崩潰恢復模式的第二個問題來回答,即當老的leader節點作為follower節點加入
新的leader領導的叢集中去的時候,新的leader會把老的leader節點中未提交的事務proposal丟棄,
這樣就犧牲了一定的可用性