
Spark troubleshooting shuffle定址 以及 解決JVM GC導致拉取檔案失敗
阿新 • • 發佈:2018-12-26
shuffle定址圖
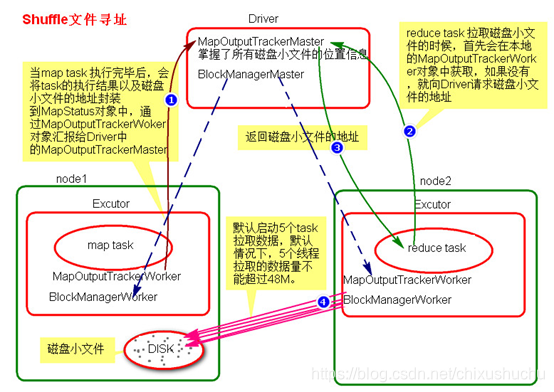
shuffle檔案定址基礎知識
MapOutputTracker
spark架構中的一個主從模組
Driver端主物件MapOutputTrackerMaster
Executor端從物件MapOutputTrackerWorker
BlockManager
也是spark架構中的一個模組,也是主從架構
Driver端主物件 BlockManagerMaster
Executor端BlockManagerWorker
無論driver端還是worker端BlockManager端都有四個物件
① DiskStore:負責磁碟的管理。
② MemoryStore
③ ConnectionManager:負責連線其他的 BlockManagerWorker。
④ BlockTransferService:負責資料的傳輸。
shuffle檔案定址流程
- map task執行過程,會將task的執行情況和磁碟小檔案地址封裝到MapStatus物件中,通過MapOutPutTrackerWorker物件向Driver端的MapOutPutTrackerMaster彙報 Driver端就掌握了所有哦磁碟小檔案地址
- reduce task執行之前,會通過Executor中MapOutPutTrackerWorker向Driver端的MapOutPutTrackerMaster獲取磁碟小檔案地址值
- 獲取到磁碟小檔案地址以後會通過BlockManager中的ConnectionManager連線資料所在節點ConnectionManager,然後通過BlockTransferService進行資料的傳輸。
- BlockTransferService預設啟動5個task去節點拉取資料。預設情況下,5個task拉取資料量不能超過48M。
官網引數
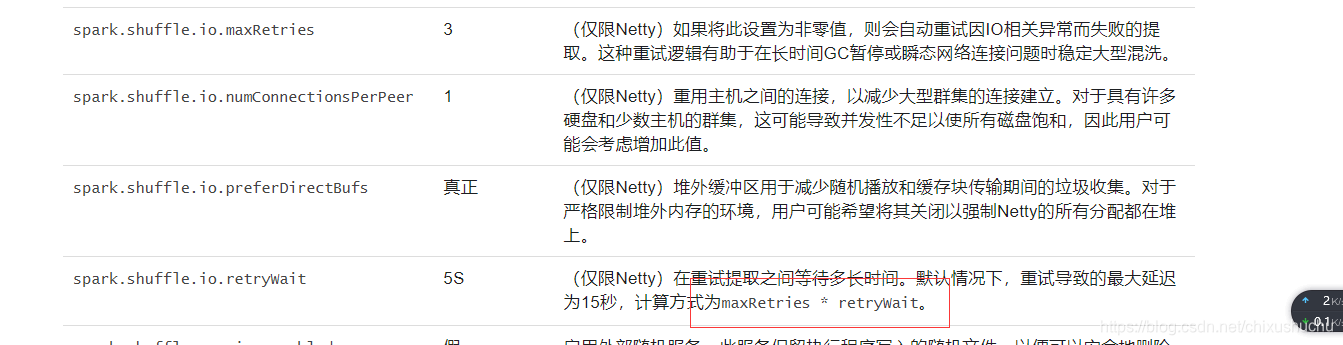
如何調節引數
根據以上分析 在拉取資料過程中如果小檔案所在executor正好在執行GC (minor GC或者 full GC)總之一旦發生GC那麼BlockManager也就結束了,無法進行網路傳輸資料,如果一直無法拉取 可能會出現shuffle file not found 但是,可能下一個stage又重新提交了stage或task以後,再執行就沒有問題了,因為可能第二次就沒有碰到JVM在gc了。
那麼可以適當調大引數
spark.shuffle.io.maxRetries 60
spark.shuffle.io.retryWait 60s
最多可以忍受1個小時沒有拉取到shuffle file。只是去設定一個最大的可能的值。full gc不可能1個小時都沒結束吧。
這樣呢,就可以儘量避免因為gc導致的shuffle file not found,無法拉取到的問題