
Infobright高效能資料倉庫
1. 概述
Infobright是一款基於獨特的專利知識網格技術的列式資料庫。Infobright簡單易用,快速安裝部署,使用中無需複雜操作,能大幅度減少管理工作;在應對50TB甚至更多資料量進行多併發複雜查詢時,更能夠顯示出令人驚歎的速度。相比於MySQL,其查詢速度提升了數倍甚至數十倍,在同類產品中單機效能處於領先地位。為企業劇增的資料規模、增長的客戶需求以及較高的使用者期望提供了全面的解決方案。
Infobright是開源的MySQL資料倉庫解決方案,引入了列儲存方案,高強度的資料壓縮,優化的統計計算(類似sum/avg/group by之類), infobright 是基於mysql的,但不裝mysql亦可,因為它本身就自帶了一個。mysql可以粗分為邏輯層和物理儲存引擎,infobright主要實現的就是一個儲存引擎,但因為它自身儲存邏輯跟關係型資料庫根本不同,所以,它不能像InnoDB那樣直接作為外掛掛接到mysql,它的邏輯層是mysql的邏輯 層加上它自身的優化器。2. Infobright特徵
優點:
1)大資料量查詢效能強勁、穩定:查詢效能高,如百萬、千萬、億級記錄數條件下,同等的SELECT查詢語句,速度比MyISAM、InnoDB等普通的MySQL儲存引擎快5~60倍。高效查詢主要依賴特殊設計的儲存結構對查詢的優化,但這裡優化的效果還取決於資料庫結構和查詢語句的設計。
2)儲存資料量大:TB級資料大小,幾十億條記錄。資料量儲存主要依賴自己提供的高速資料載入工具(百G/小時)和高資料壓縮比(>10:1)
3)高資料壓縮比:號稱平均能夠達到 10:1 以上的資料壓縮率。甚至可以達到40:1,極大地節省了資料儲存空間。高資料壓縮比主要依賴列式儲存和
patent-pending 的靈活壓縮演算法。
4)基於列儲存:無需建索引,無需分割槽。即使資料量十分巨大,查詢速度也很快。用於資料倉庫,處理海量資料沒一套可不行。不需要建索引,就避免了維護索引及索引隨著資料膨脹的問題。把每列資料分塊壓縮存放,每塊有知識網格節點記錄塊內的統計資訊,代替索引,加速搜
索。
5)快速響應複雜的聚合類查詢:適合複雜的分析性SQL查詢,如SUM, COUNT, AVG, GROUP BY
限制:
1)不支援資料更新:社群版Infobright只能使用“LOAD DATA INFILE”的方式匯入資料,不支援INSERT、UPDATE、DELETE。
這使對資料的修改變得很困難,這樣就限制了它作為實時資料服務的資料倉庫來使用。使用者要麼忍受資料的非實時或非精確,這樣對最(較)新資料的分析準確性就降低了許多;要麼將它作為歷史庫來使用,帶來的問題是實時庫用什麼?很多使用者選擇資料倉庫系統,不是因為儲存空間不夠,而是資料載入效能和查詢效能無法滿足要求。
2)不支援高併發:只能支援10多個併發查詢
雖然單庫 10 多個併發對一般的應用來說也足夠了,但較低的機器利用率對投資者來說總是一件不爽的事情,特別是在併發小請求較多的情況下。
3). 沒有提供主從備份和橫向擴充套件的功能。
如果沒有主從備份,想做備份的話,也可以主從同時載入資料,但只能校驗最終的資料一致性,這會使得從機在資料載入時停服務的時間較長;橫向擴充套件方面,倒不是 Infobright 的錯,它本身就不是分散式的儲存系統,但如果把它搞成一個分散式的系統,應該是一件比較好玩的事情。
與MySQL對比:
1、infobright適用於資料倉庫場合:即非事務、非實時、非多併發;分析為主;存放既定的事實(基本不會再變),例如日誌,或彙總的大量的
資料。所以它並不適合於應對來自網站使用者的請求。實際上它取一條記錄比mysql要慢很多,但它取100W條記錄會比mysql快。
2、mysql的總資料檔案佔用空間通常會比實際資料多,因為它還有索引。infobright的壓縮能力很強大,按列按不同型別的資料來壓縮。
3、服務形式與介面跟mysql一致,可以用類似mysql的方式啟用infobright服務,然後原來連線mysql的應用程式都可以以類似的 方式連線與查詢infobright。這對熟練mysql者來說是個福音,學習成本基本為0。
infobright有兩個釋出版:開源的ICE及閉源商用的IEE。ICE提供了足夠用的功能,但不能 INSERT,DELETE,UPDATE,只能LOAD DATA INFILE。IEE除提供更充分的功能外,據說查詢速度也要更快。
3. 架構
基於MySQL的內部架構 – Infobright採取與MySQL相似的內部架構
下面是Infobright的架構圖:
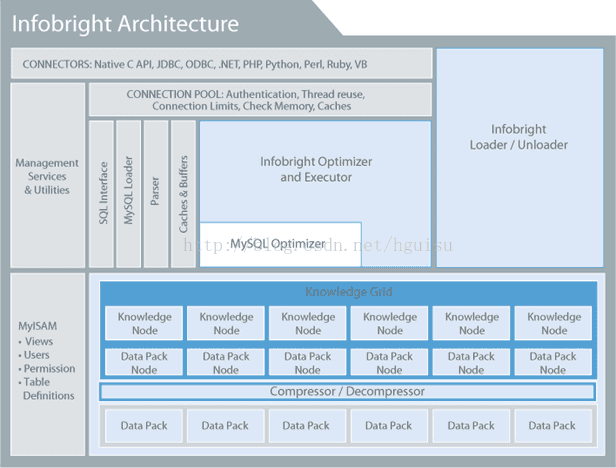
灰色部分是mysql原有的模組,白色與藍色部分則是 infobright自身的。 系統結構分析: 跟mysql一樣的兩層結構: 上面一層是邏輯層,處理查詢邏輯(服務及應用管理),下面一層是儲存引擎。 一邏輯層: 邏輯層右端的loader與unloader是infobright的資料匯入匯出模組,也即處理SQL語句裡LOAD DATA INFILE … 與SELECT … INTO FILE任務,由於infobright面向的是海量資料環境,所以這個資料匯入匯出模組是一個獨立的服務,並非直接使用mysql的模組。邏輯層的infobright優化器包在mysql查詢優化器的外面,如下面將會提到的,因為它的儲存層有一些特殊結構,所以查詢優化方式也跟 mysql有很大差異。
二儲存引擎: Infobright的預設儲存引擎是brighthouse,但是Infobright還可以支援其他的儲存引擎,比如MyISAM、MRG_MyISAM、Memory、CSV。Infobright通過三層來組織資料,分別是DP(Data Pack)、DPN(Data Pack Node)、KN(Knowledge Node)。而在這三層之上就是無比強大的知識網路(Knowledge Grid)。 Data Pack(資料塊)壓縮層:儲存引擎最底層是一個個的Data Pack(資料塊)。每一個Pack裝著某一列的64K個元素,所有資料按照這樣的形式打包儲存,每一個數據塊進行型別相關的壓縮(即根據不同資料型別採 用不同的壓縮演算法),壓縮比很高。它上層的壓縮器與解壓縮器就做了這個事情。 壓縮層再向上就是infobright最重要的概念:Knowledge Grid(知識網格)這也是infobright放棄索引卻能應用於大量資料查詢的基礎。它包含兩類結點:
1)Data Pack Node(資料塊節點):Data Pack Node和Data Pack是一一對應的關係。DPN記錄著每一個DP裡面儲存和壓縮的一些統計資料,包括最大值(max)、最小值(min)、null的個數、單元總數count、sum。avg等等。至不同值的量等等;Knowledge Node則儲存了一些更高階的統計資訊,以及與其它表的連線資訊,這裡面的資訊有些是資料載入時已經算好的,有些是隨著查詢進行而計算的,所以說是具備一 定的“智慧”的。
2)Knowledge Node裡面儲存著指向DP之間或者列之間關係的一些元資料集合,比如值發生的範圍(MIin_Max)、列資料之間的關聯。大部分的KN資料是裝載資料的時候產生的,另外一些事是查詢的時候產生。
Knowledge Grid構架是Infobright高效能的重要原因。
Knowledge Grid可分為四部分,DPN、Histogram、CMAP、P-2-P。
DPN如上所述。Histogram用來提高數字型別(比如date,time,decimal)的查詢的效能。Histogram是裝載資料的時候就產生的。DPN中有mix、max,Histogram中把Min-Max分成1024段,如果Mix_Max範圍小於1024的話,每一段就是就是一個單獨的值。這個時候KN就是一個數值是否在當前段的二進位制表示。

Histogram的作用就是快速判斷當前DP是否滿足查詢條件。如上圖所示,比如select id from customerInfo where id>50 and id<70。那麼很容易就可以得到當前DP不滿足條件。所以Histogram對於那種數字限定的查詢能夠很有效地減少查詢DP的數量。
CMAP是針對於文字型別的查詢,也是裝載資料的時候就產生的。CMAP是統計當前DP內,ASCII在1-64位置出現的情況。如下圖所示
比如上面的圖說明了A在文字的第二個、第三個、第四個位置從來沒有出現過。0表示沒有出現,1表示出現過。查詢中文字的比較歸根究底還是按照位元組進行比較,所以根據CMAP能夠很好地提高文字查詢的效能。
Pack-To-Pack是Join操作的時候產生的,它是表示join的兩個DP中操作的兩個列之間關係的點陣圖,也就是二進位制表示的矩陣。
4. 資料型別
Infobright裡面支援所有的MySQL原有的資料型別。其中Integer型別比其他資料型別更加高效。儘可能使用以下的資料型別: TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT DECIMAL(儘量減少小數點位數) DATE ,TIME 效率比較低的、不推薦使用的資料型別有: BINARY VARBINARY FLOAT DOUBLE VARCHAR TINYTEXT TEXT Infobright資料型別使用的一些經驗和注意點: (1)Infobright的數值型別的範圍和MySQL有點不一樣,比如Infobright的Int的最小值是-2147483647,而MySQl的Int最小值應該是-2147483648。其他的數值型別都存在這樣的問題。 (2)能夠使用小資料型別就使用小資料型別,比如能夠使用SMALLINT就不適用INT,這一點上Infobright和MySQL保持一致。 (3)避免效率低的資料型別,像TEXT之類能不用就不用,像FLOAT儘量用DECIMAL代替,但是需要權衡畢竟DECIMAL會損失精度。 (4)儘量少用VARCHAR,在MySQL裡面動態的Varchar效能就不強,所以儘量避免VARCHAR。如果適合的話可以選擇把VARCHAR改成CHAR儲存甚至專程INTEGER型別。VARCHAR的優勢在於分配空間的長度可變,既然Infobright具有那麼優秀的壓縮效能,個人認為完全可以把VARCHAR轉成CHAR。CHAR會具有更好的查詢和壓縮效能。 (5)能夠使用INT的情況儘量使用INT,很多時候甚至可以把一些CHAR型別的資料往整型轉化。比如搜尋日誌裡面的客戶永久id、客戶id等等資料就可以用BIGINT儲存而不用CHAR儲存。其實把時間分割成year、month、day三列儲存也是很好的選擇。在我能見到的系統裡面時間基本上是使用頻率最高的欄位,提高時間欄位的查詢效能顯然是非常重要的。當然這個還是要根據系統的具體情況,做資料分析時有時候很需要MySQL的那些時間函式。 (6)varchar和char欄位還可以使用comment lookup,comment lookup能夠顯著地提高壓縮比率和查詢效能。5. 工作原理
粗糙集(Rough Sets)是Infobright的核心技術之一。Infobright在執行查詢的時候會根據知識網路(Knowledge Grid)把DP分成三類:
相關的DP(Relevant Packs),滿足查詢條件限制的DP
不相關的DP(Irrelevant Packs),不滿足查詢條件限制的DP
可疑的DP(Suspect Packs),DP裡面的資料部分滿足查詢條件的限制
下面是一個案例:
如圖所示,每一列總共有5個DP,其中限制條件是A>6。所以A1、A2、A4就是不相關的DP,A3是相關的DP,A5是可疑的DP。那麼執行查詢的時候只需要計算B5中滿足條件的記錄的和然後加上Sum(B3),Sum(B3)是已知的。此時只需要解壓縮B5這個DP。從上面的分析可以知道,Infobright能夠很高效地執行一些查詢,而且執行的時候where語句的區分度越高越好。where區分度高可以更精確地確認是否是相關DP或者是不相關DP亦或是可以DP,儘可能減少DP的數量、減少解壓縮帶來的效能損耗。在做條件判斷的使用,一般會用到上一章所講到的Histogram和CMAP,它們能夠有效地提高查詢效能。
多表連線的的時候原理也是相似的。先是利用Pack-To-Pack產生join的那兩列的DP之間的關係。
比如:SELECT MAX(X.D) FROM T JOIN X ON T.B = X.C WHERE T.A > 6。Pack-To-Pack產生T.B和X.C的DP之間的關係矩陣M。假設T.B的第一個DP和X.C的第一個DP之間有元素交叉,那麼M[1,1]=1,否則M[1,1]=0。這樣就有效地減少了join操作時DP的數量。
前面降到了解壓縮,順便提一提DP的壓縮。每個DP中的64K個元素被當成是一個序列,其中所有的null的位置都會被單獨儲存,然後其餘的non-null的資料會被壓縮。資料的壓縮跟資料的型別有關,infobright會根據資料的型別選擇壓縮演算法。infobright會自適應地調節演算法的引數以達到最優的壓縮比。
6. 壓縮比例
Infobright號稱資料壓縮比率是10:1到40:1。前面我們已經說過了Infobright的壓縮是根據DP裡面的資料型別,系統自動選擇壓縮演算法,並且自適應地調節演算法的引數以達到最優的壓縮比。
先看看在我的實驗環境下的壓縮比率,如下圖所示:
相信讀者可以很清楚地看到,整體的壓縮比率是20.302。但是這裡有一個誤區,這裡的壓縮比率指的是資料庫中的原始資料大小/壓縮後的資料大小,而不是文字檔案的物理資料大小/壓縮後的資料大小。很明顯前者會比後者大出不少。在我的實驗環境下,後者是7:1左右。一般來說文字資料存入資料庫之後大小會比原來的文字大不少,因為有些欄位被設定了固定長度,佔用了比實際更多的空間。還有就是資料庫裡面會有很多的統計資訊資料,其中就包括索引,這些統計資訊資料佔據的空間絕對不小。Infobright雖然沒有索引,但是它有KN資料,通常情況下KN資料大小佔資料總大小的1%左右。
既然Infobright會根據具體的資料型別進行壓縮,那我們就看看不同的資料型別具有什麼樣的壓縮比率。如下表所示:
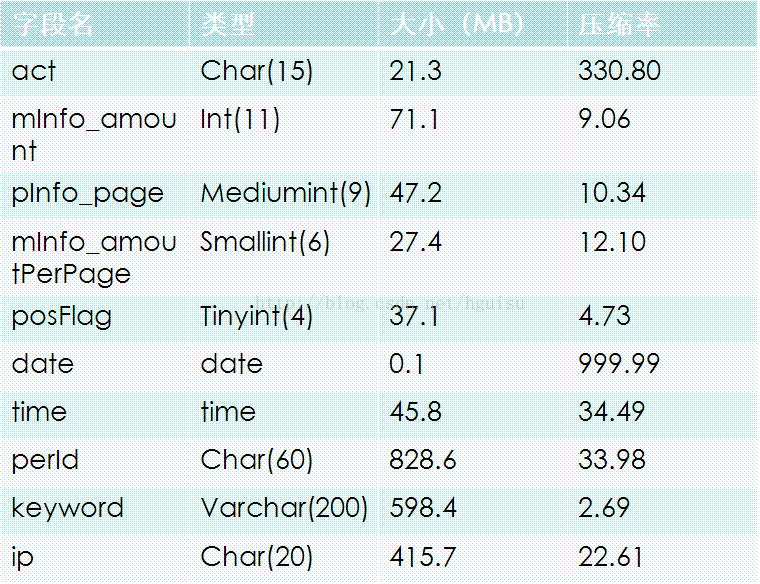
首先看看Int型別的壓縮比率,結果是壓縮比率上Int<mediumint<smallint。細心地讀者會很容易發現tinyint的壓縮比率怎麼會比int還小。資料壓縮比率除了和資料型別有關之外,還和資料的差異性有特別大關係,這是顯而易見。posFlag只有0,1,-1三種可能,這種資料顯然不可能取得很好的壓縮比率。
再看看act欄位,act欄位使用了comment lookup,比簡單的char型別具有更佳的壓縮比率和查詢效能。comment lookup的原理其實比較像點陣圖索引。對於comment lookup的使用下一章節將細細講述。
在所有的欄位當中date欄位的壓縮比率是最高的,最後資料的大小隻有0.1M。varchar的壓縮比率就比較差了,所以除非必要,不然不建議使用varchar。
上面的資料很清楚地展示了Infobright強大的壓縮效能。在此再次強調,資料的壓縮不只是和資料型別有關,資料的差異程度起了特別大的作用。在選擇欄位資料型別的時候,個人覺得效能方面的考慮應該擺在第一位。比如上面表中一些欄位的選擇就可以優化,ip可以改為bigint型別,date甚至可以根據需要拆分成year/month/day三列。
6. comment lookup的使用
comment lookup只能顯式地使用在char或者varchar上面。Comment Lookup可以減少儲存空間,提高壓縮率,對char和varchar欄位採用comment lookup可以提高查詢效率。
Comment Lookup實現機制很像點陣圖索引,實現上利用簡短的數值型別替代char欄位已取得更好的查詢效能和壓縮比率。CommentLookup的使用除了對資料型別有要求,對資料也有一定的要求。一般要求資料類別的總數小於10000並且當前列的單元數量/類別數量大於10。Comment Lookup比較適合年齡,性別,省份這一型別的欄位。
comment lookup使用很簡單,在建立資料庫表的時候如下定義即可:
act char(15) comment 'lookup',
part char(4) comment 'lookup',
7. 查詢優化
(1)配置環境
在Linux下面,Infobright環境的配置可以根據README裡的要求,配置brighthouse.ini檔案。
(2) 選取高效的資料型別
參見前面章節。
(3)使用comment lookup
參見前面章節。
(4)儘量有序地匯入資料
前面分析過Infobright的構架,每一列分成n個DP,每個DPN列面儲存著DP的一些統計資訊。有序地匯入資料能夠使不同的DP的DPN內的資料差異化更明顯。比如按時間date順序匯入資料,那麼前一個DP的max(date)<=下一個DP的min(date),查詢的時候就能夠減少可疑DP,提高查詢效能。換句話說,有序地匯入資料就是使DP內部資料更加集中,而不再那麼分散。
(5)使用高效的查詢語句。
這裡涉及的內容比較多了,總結如下:
儘量不適用or,可以採用in或者union取而代之
減少IO操作,原因是infobright裡面資料是壓縮的,解壓縮的過程要消耗很多的時間。
查詢的時候儘量條件選擇差異化更明顯的語句
Select中儘量使用where中出現的欄位。原因是Infobright按照列處理的,每一列都是單獨處理的。所以避免使用where中未出現的欄位可以得到較好的效能。
限制在結果中的表的數量,也就是限制select中出現表的數量。
儘量使用獨立的子查詢和join操作代替非獨立的子查詢
儘量不在where裡面使用MySQL函式和型別轉換符
儘量避免會使用MySQL優化器的查詢操作
使用跨越Infobright表和MySQL表的查詢操作
儘量不在group by 裡或者子查詢裡面使用數學操作,如sum(a*b)。
select裡面儘量剔除不要的欄位。
Infobright執行查詢語句的時候,大部分的時間都是花在優化階段。Infobright優化器雖然已經很強大,但是編寫查詢語句的時候很多的細節問題還是需要程式設計師注意。
7. 資料匯入
對於DW系統而言,龐大資料的遷移成本很高;所以匯入和匯出的速率及容忍性也是考量資料倉庫產品的重要標準。Infobright基於MySQL所以在資料格式上有比較成型的解決辦法,IB原廠對速率進行了優化。在4.0企業版中推出了DLP分散式匯入選件,極大的減少了遷移時間,目前世界最大的光通訊提供商JDSU也選用了IB產品,並以DLP為主要選件進行配置。
1、簡介
IB提供了專用的高效能loader,不同於傳統的mysql。IB loader是為了提高匯入速度而設計的,所以僅支援特有的mysql loader語法,而且只支援匯入格式化的變數和文字原始檔.IEE版也支援mysqlloader和insert語句。infobright對txt的格式有非常嚴格的要求,格式不對是不能匯入資料的。
2、預設Loader
1)ICE僅支援IB lorder
2)IEE預設使用的是是mysql loader,它能更多的容錯,但速度稍慢。為了最快的匯入,使用IB loader,做以下環境的設定
匯入步驟:
1)、建表:
mysql>
- createtable example2 (
- id intnotnull,
- textfield varchar(20) notnull,
- number intnotnull
- )engine=birghthouse;
2)、建立txt/csv資料:
txt/csv內容: 1,"one,two or three",1234 注意: (1)“”是為了將列區分開, (2)每行寫好後必須回車,不然導不進去。 3)、將txt匯入到infobright:
mysql> load data infile 'F:\\in2.txt' into table example2 fields terminated by ',' enclosed by '"';
Mysql>
set @bh_dataformat = ‘txt_variable’;
–使用IB loader來匯入CSV格式的變數定長文字
set @bh_dataformat = ‘binary’;
–二進位制檔案
set @bh_dataformat = ‘mysql’;
–使用mysql loader
3,IB loader語法
IB僅支援load data infile,其他的mysql匯入方式不支援
LOAD DATA INFILE ‘/full_path/file_name’
INTO TABLE tbl_name
[FIELDS
[TERMINATED BY 'char']
[ENCLOSED BY 'char']
[ESCAPED BY 'char']
];
匯入前關閉
set AUTOCOMMIT=0;
完成後
COMMIT;
set AUTOCOMMIT=1;
4,區域分隔符
.區域分隔符是可選的,預設設定為
CLAUSE DEFAULT VALUE
FIELDS TERMINATED BY ‘;’ (semicolon)
FIELDS ENCLOSED BY ‘”‘ (double quote)
FIELDS ESCAPED BY ” (none)
5,匯入經驗
a. 當匯入表格列數很多時,修改brighthouse.ini中LoaderMainHeapSize
b 使用併發匯入
c 容忍性排序為txt_variables<binary<mysql
d bh_loader不支援多分隔符
e 大量資料時,DLP是必要選擇
1.妥善處理字符集,在匯入和遷移時,儘量將所有%character%均改為與原庫相同的字符集2.選擇合適分隔符,infobright自己預設預設loader為bh_loader,僅支援單個位元組分隔符,不支援如’,,’ ‘||’等
3.IEE企業版還可以使用MySQL_loader,基本上和MySQL一樣,具備所有功能,使用前set @bh_dataformat=’mysql’;
4.遺留問題:
a.白髮漁樵江楮上
今天在試用infobright-4.0.4版本的時候,load data 的時候出現錯誤“ERROR 1598 (HY000): Binary logging not possible. Message: Statement cannot be logged to the binary log in row-based nor statement-based format”,當然可用“SET SQL_LOG_BIN = 0”不記錄日誌,但是我豈不是用不了複製了?
b.stronghearted:infobright匯入資料時,選latin1,剛才選gbk,中文總是亂碼。
stronghearted:回覆@W維西:匯出innodb的表是gbk,如果建IB的表是gbk,匯入的中文會是亂碼。選latin1就正確
W維西:Hi,做了個測試,兩邊GBK在我這邊比較正常,請看http://t.cn/akbcDH 可能還是字符集的問題,所有的變數都要改下:)
mysql資料匯入到infobright中
mysql資料匯入到infobright中1,在mysql中建一張表:
- createtable t_mis(
- uid mediumint notnull,
- cid smallintnotnull,
- rating tinyint notnull)engine=MyISAM;
插入資料:
insert into t_mis(uid,cid,rating) values('70000','3600','5');
2,將資料匯出csv檔案:
select * from t_mis into outfile 'F:\\mytable.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\n';
3,在infobright中建一個表:
- createtable t_ib(
- uid mediumint notnull,
- cis smallintnotnull,
- rating tinyint notnull)engine=brighthouse;
4,匯入csv到表t_ib中:
load data infile 'F:\\mytable.csv' into table t_ib fields terminated by ',' optionally enclosed by '"' lines terminated by '\n';