
降低模型“過擬合”、“欠擬合”風險的方法
過擬合:指模型對於訓練資料擬合呈過當的情況,反映到評估指標上,是模型在訓練集上表現很好,但在測試集和新資料上表現較差,在模型訓練過程中,表現為訓練誤差持續下降,同時測試誤差出現持續增長的情況。
欠擬合:指模型對於訓練資料擬合不足的情況,表現為模型在訓練集和測試集表現都不好。
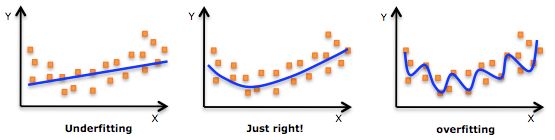
如上圖所示,從左至右,依次為欠擬合、正常模型、過擬合情況,欠擬合情況中,擬合藍線沒有很好地捕捉到資料的特徵,不能很好地擬合數據;過擬合的模型過於複雜,把噪聲資料的特徵也學習到模型中,導致模型泛化能力下降。
1 降低“過擬合”風險策略
1.1 獲取更多的訓練資料
使用更多的訓練資料是解決過擬合問題的最有效手段,因為更多的樣本能夠讓模型學習到更多更有效的特徵,減小噪聲的影響,一般通過以下3個手段獲取更多資料:
1.1.1 增加實驗資料
增加實驗資料來擴充訓練資料,例如,影象分類問題,多拍幾張物體的照片,但是在大多數情況下,大幅增加實驗資料很困難,而且我們不清楚多少資料才能足夠。
1.1.2 資料增廣(Data Augmentation)
通過一定規則擴充資料,例如,影象分類問題,可以通過對現有影象進行平移、旋轉、縮放等方式生成新的圖片,以擴充訓練資料。
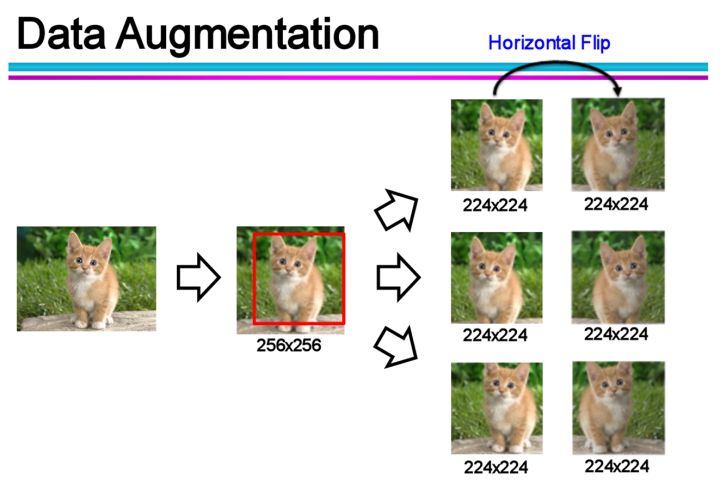
1.1.3 合成數據
使用生成對抗網路(Generative Adversarial Network,GAN)來合成大量的新訓練資料。
1.2 調整模型
在資料較少時,模型過於複雜是產生過擬合的主要因素,適當降低模型複雜度可以避免模型擬合過多的取樣噪聲。
1.2.1 調整模型結構
神經網路模型:減少網路層數、隱層神經元數量等;
決策樹模型:降低樹的深度、進行剪枝等。
1.2.2 早停(Early stopping)
將資料分成訓練集和驗證集,訓練集用來計算梯度、更新超引數,驗證集用來估計誤差,若訓練集誤差降低但驗證集誤差升高,則停止訓練。
1.2.3 正則化(regularzation)
基本思想為,在損失函式中一個用於描述網路複雜度的部分,即結構風險項,在模型訓練過程中限制權重增大。以L2正則化為例:
其中, 為經驗風險,即實際輸出與樣本之間的誤差, 為網路權重, 為零本數量, 為正則化係數,用於對經驗風險與結構風險這兩項進行折中。
1.3 增加噪聲
1.3.1 在輸入中加噪聲
噪聲會隨著網路傳播,按照權值的平方放大,並傳播到輸出層,對誤差(經驗風險)產生影響。

在輸入中加高斯噪聲,會在輸出中生成 的干擾項。訓練時,減小誤差,同時也會對噪聲產生的干擾項進行懲罰,達到減小權值的平方的目的,與L2正則效果類似。
1.3.2 在權值上加噪聲
在初始化網路的時候,用0均值的高斯分佈作為初始化。Alex Graves 的手寫識別 RNN 就是用了這個方法《A novel connectionist system for unconstrained handwriting recognition》。
1.3.3 對網路的響應加噪聲
如在前向傳播過程中,讓部分神經元輸出變為binary或random,這種做法會打亂網路的訓練過程,讓訓練更慢,但據Hinton說,在測試集上效果會有顯著提升。
1.4 整合學習
把多個模型整合在一起,來降低單一模型的過擬合風險。
1.4.1 Boosting
Boosting的工作機制如下:
- 從初始訓練集訓練出一個基學習器;
- 根據基學習器的表現對訓練樣本分佈進行調整,使先前基學習器做錯的訓練樣本在後續受到更多的關注;
- 基於調整後的樣本分佈來訓練下一個基學習器;
- 如此重複,直至基學習器數目達到事先指定的值 ;
- 最終,將這 個基學習器進行加權結合。
1.4.2 Bagging
Bagging的工作機制如下:
- 使用自助取樣法,生成 個訓練樣本集;
- 基於每個取樣集訓練出一個基學習器;
- 最後,將這些基學習器的預測結果進行結合,例如,對於分類問題,使用簡單投票法進行結合,對於迴歸問題,使用簡單平均法進行結合;
1.5 Dropout
以神經網路模型為例,在訓練過程中,每次以一定概率隨機忽略的部分隱層節點,這是一種非常高效的方法。
1.6 Batch Normalization
以神經網路為例,在網路的每一層輸入的時候,又插入了一個歸一化層,也就是先做一個歸一化處理,然後再進入網路的下一層。
Batch Normalization可以加快網路收斂速度,降低過擬合風險,具體實現如下圖所示:

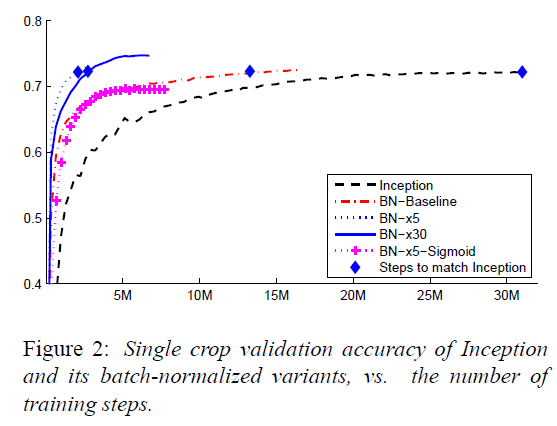

可以看出,使用Batch Normalization之後,模型收斂速度提升非常明顯,同時,測試正確率也有所提升。
2 降低“欠擬合”風險策略
2.1 新增新特徵
當特徵不足或現有特徵與樣本標籤的相關性不強時,模型容易出現欠擬合。
- 可以通過挖掘“上下文特徵”、“ID類特徵”、“組合特徵”等新的特徵;
- 利用一些模型幫助完成特徵工程,如因子分解機、梯度提升決策樹、Deep-crossing等。
2.2 增加模型複雜度
簡單模型的學習能力較差,通過增加模型的複雜度可以使模型擁有更加強大的擬合能力。
2.2.1 調整模型結構
對於線性模型,新增高次項;
對於神經網路模型,增加網路層數或神經元數量。
2.2.2 減小正則化係數
對於有正則化項的模型,可以通過減小正則化係數,來降低對模型複雜度的懲罰力度,進而提升模型的擬合能力。