
Java網路爬蟲crawler4j學習筆記 UrlResolver類
阿新 • • 發佈:2018-12-26
原始碼
package edu.uci.ics.crawler4j.url;
// 將相對地址轉化為絕對地址(具體內容參考文件http://www.faqs.org/rfcs/rfc1808.html)
public final class UrlResolver {
/**
* Class <tt>Url</tt> represents a Uniform Resource Locator.
*
* @author Martin Tamme
*/
// 一般的超連結格式 <scheme>://<net_loc>/<path>;<params>?<query>#<fragment> 測試
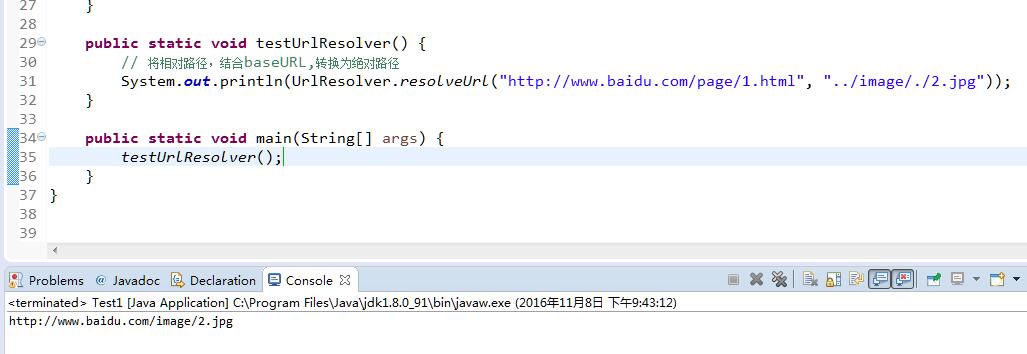
分析
UrlResolver是一個比較複雜的類,要想根本理解程式碼,需要詳細閱讀理解文件(RFC1808)。主要包含兩個功能函式:
1.private static Url parseUrl(final String spec)
將字串格式的連結轉換為標準格式的URL,標準格式為:
<scheme>://<net_loc>/<path>;<params>?<query>#<fragment>具體的演算法步驟請參考RFC1808.
2.private static Url resolveUrl(final Url baseUrl, final String relativeUrl)
結合標準格式的baseUrl和字串格式的relativeUrl得到其所對應的標準格式的絕對路徑,用於爬取過程中的URL去重。