基於scrapy的分散式爬蟲抓取新浪微博個人資訊和微博內容存入MySQL
為了學習機器學習深度學習和文字挖掘方面的知識,需要獲取一定的資料,新浪微博的大量資料可以作為此次研究歷程的物件
一、環境準備
python 2.7 scrapy框架的部署(可以檢視上一篇部落格的簡要操作,傳送門:點選開啟連結) mysql的部署(需要的資源百度網盤連結:點選開啟連結) heidiSQL資料庫視覺化 本人的系統環境是 win 64位的 所以以上環境都是需要相容64位的二、scrapy元件和資料流介紹

1、Scrapy architecture
元件Scrapy Engine
引擎負責控制資料流在系統中所有元件中流動,並在相應動作發生時觸發事件。
排程器(Scheduler)
排程器從引擎接受request並將他們入隊,以便之後引擎請求他們時提供給引擎。
下載器(Downloader)
下載器負責獲取頁面資料並提供給引擎,而後提供給spider。
Spiders
Spider是Scrapy使用者編寫用於分析response並提取item(即獲取到的item)或額外跟進的URL的類。 每個spider負責處理一個特定(或一些)網站。Item PipelineItem Pipeline負責處理被spider提取出來的item。典型的處理有清理、 驗證及持久化(例如存取到資料庫中)。
下載器中介軟體(Downloader middlewares)
下載器中介軟體是在引擎及下載器之間的特定鉤子(specific hook),處理Downloader傳遞給引擎的response。 其提供了一個簡便的機制,通過插入自定義程式碼來擴充套件Scrapy功能。更多內容請看 下載器中介軟體(Downloader Middleware) 。
Spider中介軟體(Spider middlewares)
Spider中介軟體是在引擎及Spider之間的特定鉤子(specific hook),處理spider的輸入(response)和輸出(items及requests)。 其提供了一個簡便的機制,通過插入自定義程式碼來擴充套件Scrapy功能。更多內容請看 Spider中介軟體(Middleware) 。
2、資料流(Data flow)
Scrapy中的資料流由執行引擎控制,其過程如下:
1.引擎開啟一個網站(open a domain),找到處理該網站的Spider並向該spider請求第一個要爬取的URL(s)。
2.引擎從Spider中獲取到第一個要爬取的URL並在排程器(Scheduler)以Request排程。
3.引擎向排程器請求下一個要爬取的URL。
4.排程器返回下一個要爬取的URL給引擎,引擎將URL通過下載中介軟體(請求(request)方向)轉發給下載器(Downloader)。
5.一旦頁面下載完畢,下載器生成一個該頁面的Response,並將其通過下載中介軟體(返回(response)方向)傳送給引擎。
6.引擎從下載器中接收到Response並通過Spider中介軟體(輸入方向)傳送給Spider處理。
7.Spider處理Response並返回爬取到的Item及(跟進的)新的Request給引擎。
8.引擎將(Spider返回的)爬取到的Item給Item Pipeline,將(Spider返回的)Request給排程器。
9.(從第二步)重複直到排程器中沒有更多地request,引擎關閉該網站。
以上元件和資料流的部分是參考別的的介紹,覺得描述的挺好,比較容易理解整個框架的結構。下面是乾貨:
三、scrapy工程物件
在你需要建立工程的目錄底下啟動cmd命令(按住shift鍵右鍵選擇在此處開啟命令視窗) 執行:scrapy startproject weibo 會在當前目錄下生成scrapy框架的目錄結構: 本人用的IDE是pycharm ,用IDE開啟工程,工程最終的目錄結構如圖所示: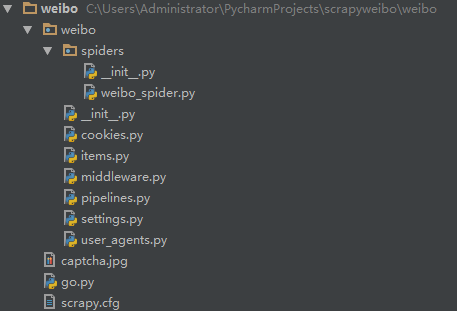
1、item.py的內容:
# encoding=utf-8
from scrapy.item import Item, Field
class InformationItem(Item):
#關注物件的相關個人資訊
_id = Field() # 使用者ID
Info = Field() # 使用者基本資訊
Num_Tweets = Field() # 微博數
Num_Follows = Field() # 關注數
Num_Fans = Field() # 粉絲數
HomePage = Field() #關注者的主頁
class TweetsItem(Item):
#微博內容的相關資訊
_id = Field() # 使用者ID
Content = Field() # 微博內容
Time_Location = Field() # 時間地點
Pic_Url = Field() # 原圖連結
Like = Field() # 點贊數
Transfer = Field() # 轉載數
Comment = Field() # 評論數定義了兩個類,InformationItem獲取關注列表使用者的個人資訊,TweetsItem獲取微博內容
2、weibo_spider.py的內容:
# coding=utf-8
from scrapy.spider import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from weibo.items import InformationItem,TweetsItem
import re
import requests
from bs4 import BeautifulSoup
class Weibo(Spider):
name = "weibospider"
redis_key = 'weibospider:start_urls'
#可以從多個使用者的關注列表中獲取這些使用者的關注物件資訊和關注物件的微博資訊
start_urls = ['http://weibo.cn/0123456789/follow','http://weibo.cn/0123456789/follow']
#如果通過使用者的分組獲取關注列表進行抓取資料,需要調整parse中如id和nextlink的多個引數
#strat_urls = ['http://weibo.cn/attgroup/show?cat=user¤tPage=2&rl=3&next_cursor=20&previous_cursor=10&type=opening&uid=1771329897&gid=201104290187632788&page=1']
url = 'http://weibo.cn'
#group_url = 'http://weibo.cn/attgroup/show'
#把已經獲取過的使用者ID提前加入Follow_ID中避免重複抓取
Follow_ID = ['0123456789']
TweetsID = []
def parse(self,response):
#使用者關注者資訊
informationItems = InformationItem()
selector = Selector(response)
print selector
Followlist = selector.xpath('//tr/td[2]/a[2]/@href').extract()
print "輸出關注人ID資訊"
print len(Followlist)
for each in Followlist:
#選取href字串中的id資訊
followId = each[(each.index("uid")+4):(each.index("rl")-1)]
print followId
follow_url = "http://weibo.cn/%s" % followId
#通過篩選條件獲取需要的微博資訊,此處為篩選原創帶圖的微博
needed_url = "http://weibo.cn/%s/profile?hasori=1&haspic=1&endtime=20160822&advancedfilter=1&page=1" % followId
print follow_url
print needed_url
#抓取過資料的使用者不再抓取:
while followId not in self.Follow_ID:
yield Request(url=follow_url, meta={"item": informationItems, "ID": followId, "URL": follow_url}, callback=self.parse1)
yield Request(url=needed_url, callback=self.parse2)
self.Follow_ID.append(followId)
nextLink = selector.xpath('//div[@class="pa"]/form/div/a/@href').extract()
#查詢下一頁,有則迴圈
if nextLink:
nextLink = nextLink[0]
print nextLink
yield Request(self.url + nextLink, callback=self.parse)
else:
#沒有下一頁即獲取完關注人列表之後輸出列表的全部ID
print self.Follow_ID
#yield informationItems
def parse1(self, response):
""" 通過ID訪問關注者資訊 """
#通過meta把parse中的物件變數傳遞過來
informationItems = response.meta["item"]
informationItems['_id'] = response.meta["ID"]
informationItems['HomePage'] = response.meta["URL"]
selector = Selector(response)
#info = ";".join(selector.xpath('//div[@class="ut"]/text()').extract()) # 獲取標籤裡的所有text()
info = selector.xpath('//div[@class="ut"]/span[@class="ctt"]/text()').extract()
#用/分開把列表中的各個元素便於區別不同的資訊
allinfo = ' / '.join(info)
try:
#exceptions.TypeError: expected string or buffer
informationItems['Info'] = allinfo
except:
pass
#text2 = selector.xpath('body/div[@class="u"]/div[@class="tip2"]').extract()
num_tweets = selector.xpath('body/div[@class="u"]/div[@class="tip2"]/span/text()').extract() # 微博數
num_follows = selector.xpath('body/div[@class="u"]/div[@class="tip2"]/a[1]/text()').extract() # 關注數
num_fans = selector.xpath('body/div[@class="u"]/div[@class="tip2"]/a[2]/text()').extract() # 粉絲數
#選取'[' ']'之間的內容
if num_tweets:
informationItems["Num_Tweets"] = (num_tweets[0])[((num_tweets[0]).index("[")+1):((num_tweets[0]).index("]"))]
if num_follows:
informationItems["Num_Follows"] = (num_follows[0])[((num_follows[0]).index("[")+1):((num_follows[0]).index("]"))]
if num_fans:
informationItems["Num_Fans"] = (num_fans[0])[((num_fans[0]).index("[")+1):((num_fans[0]).index("]"))]
yield informationItems
#獲取關注人的微博內容相關資訊
def parse2(self, response):
selector = Selector(response)
tweetitems = TweetsItem()
#可以直接用request的meta傳遞ID過來更方便
IDhref = selector.xpath('//div[@class="u"]/div[@class="tip2"]/a[1]/@href').extract()
ID = (IDhref[0])[1:11]
Tweets = selector.xpath('//div[@class="c"]')
# 跟parse1稍有不同,通過for迴圈尋找需要的物件
for eachtweet in Tweets:
#獲取每條微博唯一id標識
mark_id = eachtweet.xpath('@id').extract()
print mark_id
#當id不為空的時候加入到微博獲取列表
if mark_id:
#去重操作,對於已經獲取過的微博不再獲取
while mark_id not in self.TweetsID:
content = eachtweet.xpath('div/span[@class="ctt"]/text()').extract()
timelocation = eachtweet.xpath('div[2]/span[@class="ct"]/text()').extract()
pic_url = eachtweet.xpath('div[2]/a[2]/@href').extract()
like = eachtweet.xpath('div[2]/a[3]/text()').extract()
transfer = eachtweet.xpath('div[2]/a[4]/text()').extract()
comment = eachtweet.xpath('div[2]/a[5]/text()').extract()
tweetitems['_id'] = ID
#把列表元素連線且轉存成字串
allcontents = ''.join(content)
#內容可能為空 需要先判定
if allcontents:
tweetitems['Content'] = allcontents
else:
pass
if timelocation:
tweetitems['Time_Location'] = timelocation[0]
if pic_url:
tweetitems['Pic_Url'] = pic_url[0]
# 返回字串中'[' ']'裡的內容
if like:
tweetitems['Like'] = (like[0])[((like[0]).index("[")+1):((like[0]).index("]"))]
if transfer:
tweetitems['Transfer'] = (transfer[0])[((transfer[0]).index("[")+1):((transfer[0]).index("]"))]
if comment:
tweetitems['Comment'] = (comment[0])[((comment[0]).index("[")+1):((comment[0]).index("]"))]
#把已經抓取過的微博id存入列表
self.TweetsID.append(mark_id)
yield tweetitems
else:
#如果selector語句找不到id 檢視當前查詢語句的狀態
print eachtweet
tweet_nextLink = selector.xpath('//div[@class="pa"]/form/div/a/@href').extract()
if tweet_nextLink:
tweet_nextLink = tweet_nextLink[0]
print tweet_nextLink
yield Request(self.url + tweet_nextLink, callback=self.parse2)
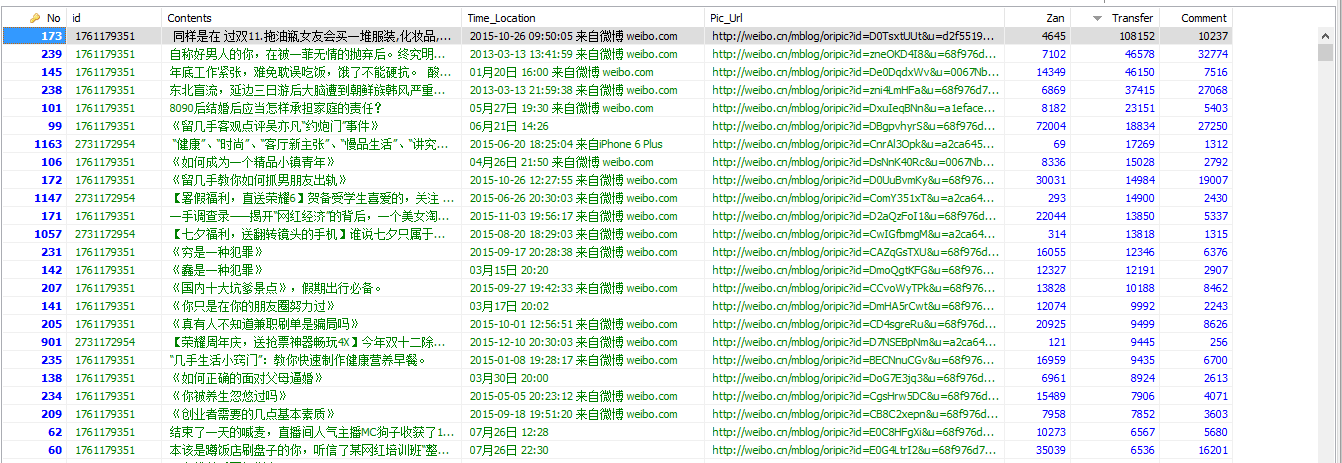
每個微博使用者都有唯一的標識uid,此uid是獲取需要物件的關鍵。修改start_url裡面的ID(0123456789),比如換成留幾手的ID(1761179351),即把地址換成你想獲取的使用者的關注人列表的資訊,可以對多個使用者的關注列表用redis_keyf方式進行分散式操作。內容比較多就不一一介紹,程式碼不理解的可以留言探討,本人也是模仿著別人的框架寫出來的程式碼,不是科班出身,程式碼寫的比較渣渣,大神可以幫忙指點一二。
3、獲取cookies模擬登陸微博:
# encoding=utf-8
import requests
from selenium import webdriver
import time
from PIL import Image
import urllib2
from bs4 import BeautifulSoup
import re
import urllib
在myAcount中輸入你自己擁有的微博賬號密碼,就可以模擬登陸微博啦: 這裡有兩種方式: 【1】模擬瀏覽器提交表單登陸(推薦) 【2】通過selenium WebDriver 方式登陸 驗證碼暫時還是先手動輸一下吧,還沒有找到快速有效的方式破解。 反正只要拿到cookie儲存下來就可以進行抓取操作啦。
4、資料管道pipeline存入MySQL資料庫:
# -*- coding: utf-8 -*-
import MySQLdb
from items import InformationItem,TweetsItem
DEBUG = True
if DEBUG:
dbuser = 'root'
dbpass = '123456'
dbname = 'tweetinfo'
dbhost = '127.0.0.1'
dbport = '3306'
else:
dbuser = 'XXXXXXXX'
dbpass = 'XXXXXXX'
dbname = 'tweetinfo'
dbhost = '127.0.0.1'
dbport = '3306'
class MySQLStorePipeline(object):
def __init__(self):
self.conn = MySQLdb.connect(user=dbuser, passwd=dbpass, db=dbname, host=dbhost, charset="utf8",
use_unicode=True)
self.cursor = self.conn.cursor()
#建立需要儲存資料的表
# 清空表(測試階段):
self.cursor.execute("truncate table followinfo;")
self.conn.commit()
self.cursor.execute("truncate table tweets;")
self.conn.commit()
def process_item(self, item, spider):
#curTime = datetime.datetime.now()
if isinstance(item, InformationItem):
print "開始寫入關注者資訊"
try:
self.cursor.execute("""INSERT INTO followinfo (id, Info, Num_Tweets, Num_Follows, Num_Fans, HomePage)
VALUES (%s, %s, %s, %s, %s, %s)""",
(
item['_id'].encode('utf-8'),
item['Info'].encode('utf-8'),
item['Num_Tweets'].encode('utf-8'),
item['Num_Follows'].encode('utf-8'),
item['Num_Fans'].encode('utf-8'),
item['HomePage'].encode('utf-8'),
)
)
self.conn.commit()
except MySQLdb.Error, e:
print "Error %d: %s" % (e.args[0], e.args[1])
elif isinstance(item, TweetsItem):
print "開始寫入微博資訊"
try:
self.cursor.execute("""INSERT INTO tweets (id, Contents, Time_Location, Pic_Url, Zan, Transfer, Comment)
VALUES (%s, %s, %s, %s, %s, %s, %s)""",
(
item['_id'].encode('utf-8'),
item['Content'].encode('utf-8'),
item['Time_Location'].encode('utf-8'),
item['Pic_Url'].encode('utf-8'),
item['Like'].encode('utf-8'),
item['Transfer'].encode('utf-8'),
item['Comment'].encode('utf-8')
)
)
self.conn.commit()
except MySQLdb.Error, e:
print "出現錯誤"
print "Error %d: %s" % (e.args[0], e.args[1])
return item
MySQL部署好之後只要輸入自己的使用者名稱密碼就可以存到資料庫當中去 因為我的建立表格沒有寫到pipeline中,就先自己建好資料庫和表格好了: 需要注意的是:為了讓mysql正常顯示中文,在建立資料庫的時候使用如下語句:
CREATE DATABASE tweetinfo DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;資料庫目錄結構:
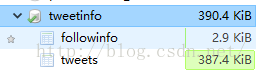
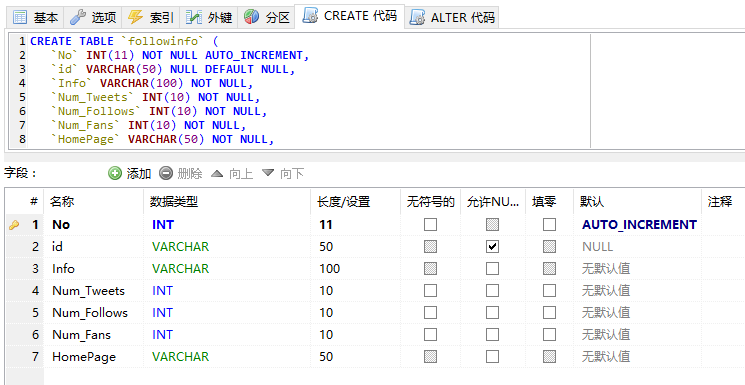
建立 表格followinfo
CREATE TABLE `followinfo` (
`No` INT(11) NOT NULL AUTO_INCREMENT,
`id` VARCHAR(50) NULL DEFAULT NULL,
`Info` VARCHAR(100) NOT NULL,
`Num_Tweets` INT(10) NOT NULL,
`Num_Follows` INT(10) NOT NULL,
`Num_Fans` INT(10) NOT NULL,
`HomePage` VARCHAR(50) NOT NULL,
PRIMARY KEY (`No`)
)
COLLATE='utf8_general_ci'
ENGINE=MyISAM
AUTO_INCREMENT=5
;
建立表格tweets
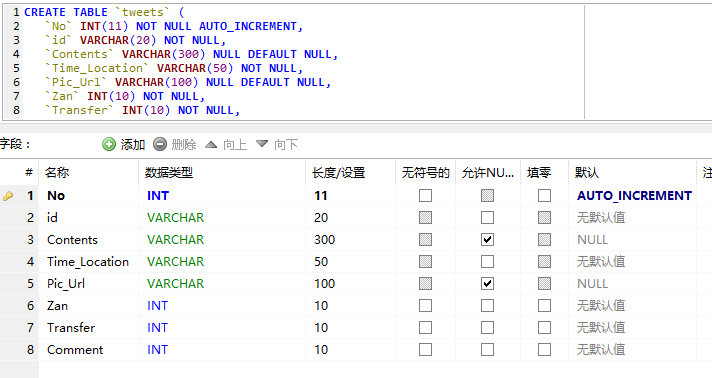
CREATE TABLE `tweets` (
`No` INT(11) NOT NULL AUTO_INCREMENT,
`id` VARCHAR(20) NOT NULL,
`Contents` VARCHAR(300) NULL DEFAULT NULL,
`Time_Location` VARCHAR(50) NOT NULL,
`Pic_Url` VARCHAR(100) NULL DEFAULT NULL,
`Zan` INT(10) NOT NULL,
`Transfer` INT(10) NOT NULL,
`Comment` INT(10) NOT NULL,
PRIMARY KEY (`No`)
)
COLLATE='utf8_general_ci'
ENGINE=MyISAM
AUTO_INCREMENT=944
;
5、中間組建middleware:
# encoding=utf-8
import random
from cookies import cookies
from user_agents import agents
class UserAgentMiddleware(object):
""" 換User-Agent """
def process_request(self, request, spider):
agent = random.choice(agents)
request.headers["User-Agent"] = agent
class CookiesMiddleware(object):
""" 換Cookie """
def process_request(self, request, spider):
cookie = random.choice(cookies)
request.cookies = cookie
6、設定相關settings:
# coding=utf-8
BOT_NAME = 'weibo'
SPIDER_MODULES = ['weibo.spiders']
NEWSPIDER_MODULE = 'weibo.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
'''