
資料庫分庫分表架構選型
隨著使用者量的增加和歷史資料的不斷積累,導致公司系統越來越卡,稍微複雜的查詢都是分鐘級,甚至有前端請求超時報錯的情況(2分鐘),所以這段時間一直在研究公司的資料庫架構。
我是一個地道的java程式設計師,由於我們公司沒有DBA,所以只能我來研究,這也是公司交給我的一個重要的任務,我利用做完手頭專案的空餘時間分析並研究了目前市場上很多的資料庫架構,進行一次總結、體會。
請謹記:
沒有最好的資料庫架構,只有適不適合的資料庫架構。
0 資料庫架構調整背景:
1、sql已經無法繼續優化
2、資料庫表結構設計已經無法繼續優化
3、已經做了讀寫分離,但是效能還是低
4、單日資料量50W左右,不超過100W(超過100W不建議使用本文的做法,後面會講到)
5、讀壓力遠大於寫壓力
6、對最近的1到2個月的資料操作頻繁、對最近半年的較頻繁
7、偶爾會對很久的歷史資料進行查詢(歷史資料不能刪)
8、無法避免會進行關聯查詢
9、分頁、排序等功能都必須正常使用
10、沒有專門的DBA,或者公司不想運維過於複雜的資料庫架構
如果你滿足以上需要,那恭喜你,這篇文章應該值得你參考。
為了不浪費大家寶貴的時間,我這篇文章採用倒敘的方法,第一章直接介紹架構調整後的終極版本,第二章開始介紹有哪些其他的架構都被pass掉了,讓大家更加認同“終極版本”。當然如果大家有其他想法或者意見都歡迎評論留言。
1 終極版本
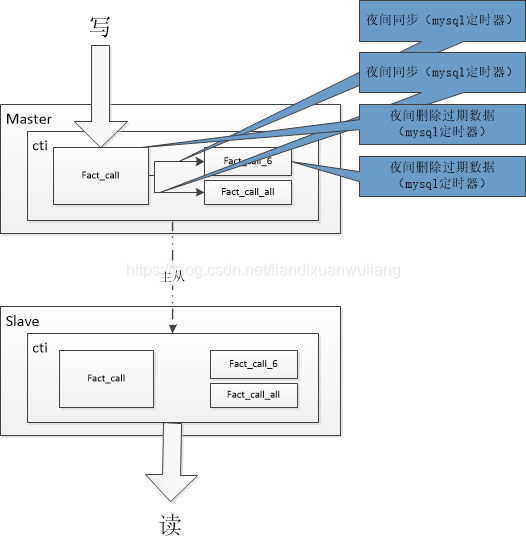
首先,解釋下上圖的含義:
- 圖中的master是mysql的寫庫、slave是mysql的讀庫;cti是資料庫的名字,fact_call表存最近2個月的資料,fact_call_6存最近6個月的資料,fact_call_all表存所有資料。
- fact_call_6和fact_call_all的資料每天從fact_call表同步過來,同步完畢後需要刪除fact_call表中超過2個月的資料,還需要刪除fact_call_6表中超過6個月的資料.
- 注意:需要限制查詢最近的超過2個月的資料(如果要查詢超過2個月的資料,則不能查今天的資料,因為今天的需要到晚上才能同步到fact_call_6表中)。
- 當然也可以設定為1個月的、2個月的、6個月的、永久的。主要思路是:不分表不分庫,做表的冗餘儲存
其次,mysql的指令碼:
- mysql的儲存過程指令碼
-- 建立同步的儲存過程
DELIMITER //
USE `cti`//
DROP PROCEDURE IF EXISTS pro_syn_data//
CREATE PROCEDURE pro_syn_data ()
BEGIN
INSERT INTO `fact_call_6` - mysql的定時器指令碼
-- 查詢mysql事件是否開啟
show variables like 'event_scheduler';
select @@event_scheduler;
-- 開啟mysql事件
SET GLOBAL event_scheduler = 1;
-- 建立定時同步的事件
DROP EVENT IF EXISTS `e_pro_syn_data`;
CREATE EVENT `e_pro_syn_data`
ON SCHEDULE EVERY 1 DAY STARTS '2018-11-12 00:00:01'
ON COMPLETION NOT PRESERVE ENABLE DO CALL pro_syn_data ();
-- 建立定時刪除的事件
DROP EVENT IF EXISTS `e_pro_clear_data`;
CREATE EVENT `e_pro_clear_data`
ON SCHEDULE EVERY 1 DAY STARTS '2018-11-12 02:00:00'
ON COMPLETION NOT PRESERVE ENABLE DO CALL pro_clear_data ();
再次,讀取分表資料的java的示例程式碼:
主要思路:在查詢fact_call等表前判斷應該查哪個表查。
核心程式碼:
(1)通過時間範圍確定表名
/**
* 確定從哪張表中讀取資料
* @param decisionTime 這是sql中最小的的report_time
* 例如:select * from fact_call where report_time > '2018-10-06 17:32:59' and report_time < '2018-11-06 17:32:59'
* 或者:select * from fact_call where report_time between '2018-10-06 17:32:59' and '2018-11-06 17:32:59'
* 那麼decisionTime應該是其中較小的值'2018-10-06 17:32:59'
* 注意:必須限制一次查詢的最大時間跨度不超過3個月
*/
public String decisionTableName(String decisionTime) {
try {
if (null!=decisionTime && !"".equals(decisionTime)) {
long decision = sdf.parse(decisionTime).getTime();
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.MONTH, -3);
long before_3 = calendar.getTimeInMillis();
calendar.add(Calendar.MONTH, -3);
long before_6 = calendar.getTimeInMillis();
if (decision > before_3) {
return "fact_call";
} else if (decision > before_6) {
return "fact_call_6";
} else {
return "fact_call_all";
}
}
}catch (Exception e) {
e.printStackTrace();
}
return "fact_call_all";
}
(2)mybatis的對映檔案,對錶名做判斷:
<select id="findAll" resultMap="base_result_map" parameterType="java.util.Map">
SELECT
*
FROM
<choose>
<when test="tableName=='fact_call'">
fact_call f
</when>
<when test="tableName=='fact_call_6'">
fact_call_6 f
</when>
<otherwise>
fact_call_all f
</otherwise>
</choose>
WHERE
1=1
<!-- and f.report_time < #{begin_time} and f.report_time > #{end_time}-->
and f.report_time between #{begin_time} and #{end_time}
limit #{index} , #{size}
</select>
最後,解釋為什麼這麼做:
優點:
1、不需要分庫(後面會介紹分庫的架構)
2、不依賴第三方程式(後面會介紹資料庫中介軟體的架構)
3、資料冗餘儘量少(後面會介紹一主多從的架構)
4、可靠性更高(後面會介紹使用mysql觸發器做實時同步的架構)
缺點:
1、資料冗餘為8個月資料(以空間換時間)
2、需要開啟mysql定時器功能(影響的效能很小,可忽略)
3、對程式設計師不透明(但是程式設計師自己程式碼判斷去哪個表中查,也很簡單)
4、單臺數據庫存在伺服器io限制(我們公司的資料庫查詢慢的問題不在於伺服器,在於單表過大)
最終完美上線
2 為什麼不使用mycat、Kingshard、Sharding-JDBC
1、為什麼不使用mycat
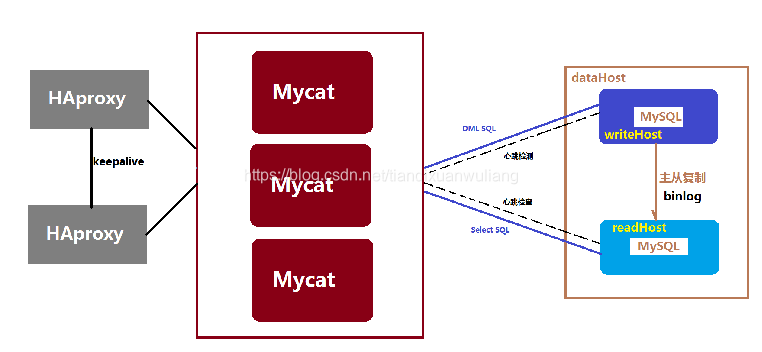
(注:上圖來源網路)
mycat功能很強大,即支援分庫也支援分表。支援取模、hash等不同的劃分策略。但是存在三點問題:
- 叢集搭建過於複雜,運維成本高,如果不搭建mycat叢集又會帶來單點故障問題;
- 我的需求對於最近資料和歷史資料是不同的,歷史資料可能1年也就查幾次,慢點無所謂
- 我必須要使用分頁、排序等功能
注:
但是大後期,也就是過了很多年後,當我們公司有了自己的DBA,當我們的日資料量超過100W,應該還是會採用分庫分表的辦法。(為什麼是100W呢?因為mysql innodb處理5000W資料量的單錶速度勉強可以接受,5000W/60天,約等於100W/天)。我們公司還處於早期階段,沒有DBA,公司想盡快提高資料庫效能,又不想搞得太複雜。
至於不使用Kingshard、Sharding-JDBC原因很多,一方面太麻煩了,Kingshard使用Go語言開發,難以維護。Sharding-JDBC對程式設計師不透明,我每個程式都一遍複雜的分庫分表,主要是複雜。
另外,從我需求的角度分析,我已經手動分表了,也不需要使用第三方來做讀寫分離。完全就沒必要使用資料庫中介軟體!
3 為什麼不使用一主多從
一主多從的架構,如下圖:
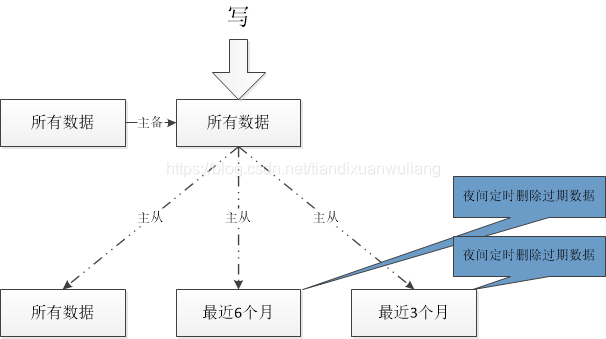
(上圖的最近3月,改為最近2月。)
上圖是分庫的,之前準備使用mybatis的多源資料庫自動切換的辦法,這樣可以避免使用資料庫中介軟體,也蠻簡單的,在每次查詢之前根據分庫的key來切換資料來源即可(感興趣的可以自己搜尋,我是已經實現過)。上圖的好處是可以把資料庫放在不同的伺服器上,但是缺點是違反了主從原則,運維管理也很麻煩。後來被pass掉了。
3 為什麼不使用mysql觸發器做實時同步
mysql觸發器實時同步的版本:
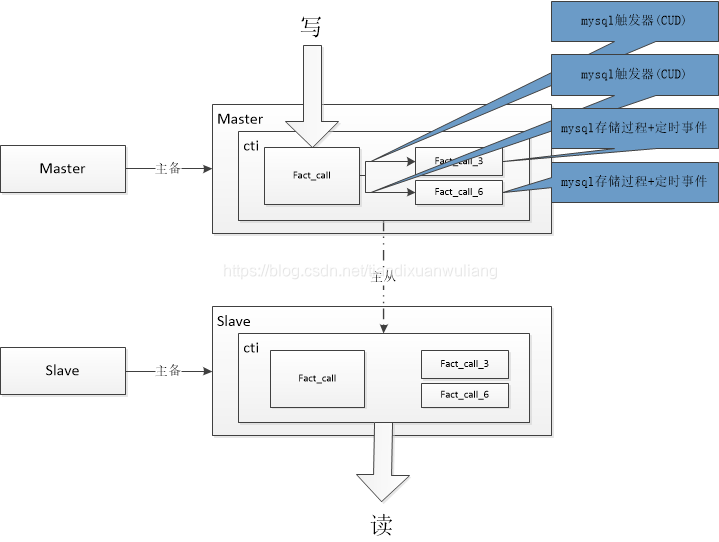
大家應該看出來了,終極版本中“需要限制查詢最近的超過2個月的資料(如果要查詢超過2個月的資料,則不能查今天的資料,因為今天的需要到晚上才能同步到fact_call_6表中)”,這個原因是因為,我做的不是實時同步,那麼為什麼不使用mysql觸發器做實時同步,原因很簡單,當資料庫操作過於頻繁時,mysql觸發器不可靠!
經過很久的while(true){分析、開會、討論},最終得出來了我們的“終極版本”。最終版本雖說看起來很簡單,也沒有使用什麼複雜的技術,但是能滿足我們的需求,最快的提升資料庫效能。就像:
以前:
客戶:我想查下我今天的資料,為什麼查不出來資料了,一查就報錯。
產品經理:沒辦法資料庫量太大了。
客戶:什麼?那也就是說我以後每天的資料都不能查了?
產品經理說:那我把兩年前的資料刪了吧?
客戶:刪資料?那怎麼行,萬一我們領導哪天要檢查、核實、取證怎麼辦,不能刪(其實他們永遠不會去查很久以前的資料,他們只是一聽到刪他們的資料他們就很慌)。
上線完畢,改動相對較小。只是多加了兩張表、對於要查fact_call表的程式稍微做了修改。
現在:
客戶:我今天的資料可以查,但是查以前的資料很慢,為什麼?
產品經理:誰叫你查以前的資料,查很久以前的資料,本來就慢…
客戶:哦,好吧…
我:(哈哈哈哈)
本文地址:https://blog.csdn.net/tiandixuanwuliang/article/details/84650061