
python資料分析:時間序列分析(Time series analysis)
何為時間序列分析:
時間序列經常通過折線圖繪製。時間序列用於統計,訊號處理,模式識別,計量經濟學,數學金融,天氣預報,地震預測,腦電圖,控制工程,天文學,通訊工程,以及主要涉及時間測量的任何應用科學和工程領域。
時間序列分析包括用於分析時間序列資料的方法,以便提取有意義的統計資料和資料的其他特徵。時間序列預測是使用模型根據先前觀察到的值預測未來值。雖然迴歸分析通常採用的方式是測試理論,即一個或多個獨立時間序列的當前值會影響另一個時間序列的當前值,但這種時間序列分析不稱為“時間序列分析”,其重點是比較不同時間點的單個時間序列或多個相關時間序列的值。中斷時間序列 分析是對單個時間序列的干預分析。
時間序列資料具有自然的時間順序。這使得時間序列分析不同於橫斷面研究,其中沒有觀察的自然順序(例如,通過參考其各自的教育水平來解釋人們的工資,其中個體的資料可以以任何順序輸入)。時間序列分析也不同於空間資料分析,其中觀測通常與地理位置相關(例如,通過位置來計算房價以及房屋的內在特徵)。一個隨機的時間序列的模型通常會反映出這樣一個事實,即與時間緊密相連的觀測結果將比進一步分開的觀察結果更加密切相關。此外,時間序列模型通常會利用時間的自然單向排序,因此給定時期的值將表示為從過去的值中獲得,而不是從未來的值中獲得(參見時間可逆性)。
時間序列分析可應用於實值,連續資料,離散 數字資料或離散符號資料(即字元序列,如英語中的字母和單詞)。
常用時間序列分析:
時間序列的常用演算法包括移動平均(MA, Moving Average)、指數平滑(ES, Exponen-tial Smoothing)、差分自迴歸移動平均模型(ARIMA , Auto-regressive Integrated Moving Average Model)三大主要類別,每個類別又可以細分和延伸出多種演算法。
當資料集規模較大、資料粒度豐富時,我們可以選擇多種時間序列的預測模式。時間序列的資料粒度可分為秒、分、小時、天、周、月、季度、年等,不同的粒度都可以用來做時間序列預測。
假如有3650天(完整10年)以每分鐘時間戳為粒度的資料,那麼這份資料集會有5256 000(60分鐘24小時
- 整合模式:將歷史資料按每天資料進行彙總,得到按天為粒度的共計3650條時間序列資料;然後應用所有資料集做時間序列分析,預測的時間序列專案為1(天)。
- 橫向模式:將歷史資料按每小時做彙總,得到按小時為粒度87600條時間序列資料;然後將要預測的1天劃分為24小時(即24個預測點),這樣會形成24個預測模型,每個模型只預測對應的小時點資料,預測的時間序列專案為1(小時);最後將預測得到的24個小時點的資料求和得到今天的總資料。
- 縱向模式:這種模式的粒度更細,無需對歷史資料做任何形式的彙總,這樣有525600條時間序列資料。將要預測的1天劃分為1440個分鐘點(60分鐘*24小時),這樣會形成1440個預測模型,每個模型只預測對應的分鐘點的資料,預測的時間序列專案為1(分鐘);最後將預測得到的1440個分鐘點的資料求和得到今天的總資料。
這三種方式的訓練集都是3650條,即按天為粒度的資料。橫向模式和縱向模式由於做更細的粒度切分,因此需要更多的模型,這意味著需要更多的時間來做訓練和預測。當第一種整合模式不能滿足需求或者預測結果不佳時,可以嘗試後兩種模式。
平穩性
平穩性是做時間序列分析的前提條件,所謂平穩通俗理解就是資料沒有隨著時間呈現明顯的趨勢和規律,例如劇烈波動、遞增、遞減等,而是相對均勻且隨機地分佈在均值附近。在ARIMA模型中的I就是對資料做差分以實現資料的平穩,而ARIMA關鍵引數p、d、q中的d即時間序列成為平穩時所做的差分次數。
如何判斷時間序列資料是否需要平穩性處理?一般有三種方法:
- 觀察法:通過輸出時間序列圖發現數據是否平穩。本示例中的adf_val函式便含有該方法。
- 自相關和偏相關法:通過觀察自相關和偏相關的係數分析資料是否平穩。
- ADF檢驗:通過ADF檢驗得到的顯著性水平分析資料是否平穩。本示例中的adf_val函式便有含有該方法。
實現資料的平穩有以下幾種方法:
- 對數法:對數處理可以減小資料的波動,使其線性規律更加明顯。但需要注意的是對數處理只能針對時間序列的值大於0的資料集。
- 差分法:一般來說,非純隨機的時間序列經一階差分或者二階差分之後就會變得平穩(statsmodels的ARIMA模型自動支援資料差分,但最大為2階差分)。
- 平滑法:根據平滑技術的不同,可分為移動平均法和指數平均法,這兩個都是最基本的時間序列方法。
- 分解法:將時序資料分離成不同的成分,包括成長期趨勢、季節趨勢和隨機成分等。
白噪聲
白噪聲(white noise)檢驗也稱為隨機性檢驗,用於檢驗時間序列的各項數值之間是否具有任何相關關係,白噪聲分佈是應用時間序列分析的前提。檢測時間序列是否屬於隨機性分佈,可通過圖形法和Ljung Box法檢驗。
- 圖形法:時間序列應該是圍繞均值隨機性上下分佈的狀態。
- Ljung Box法:是對時間序列是否存在滯後相關的一種統計檢驗,判斷序列總體的相關性或者說隨機性是否存在。
白噪聲檢驗通常和資料平穩性檢驗是協同進行資料檢驗的,這意味著如果平穩性檢驗通過,白噪聲檢驗一般也會通過。
python實現
import pandas as pd # pandas庫
import numpy as np # numpy庫
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf # acf和pacf展示庫
from statsmodels.tsa.stattools import adfuller # adf檢驗庫
from statsmodels.stats.diagnostic import acorr_ljungbox # 隨機性檢驗庫
from statsmodels.tsa.arima_model import ARMA # ARMA庫
import matplotlib.pyplot as plt # matplotlib圖形展示庫
import prettytable # 匯入表格庫
# 由於pandas判斷週期性時會出現warning,這裡忽略提示
import warnings
warnings.filterwarnings('ignore')
#### 讀取資料 ####
# 建立解析列的功能物件
date_parse = lambda dates: pd.datetime.strptime(dates, '%m-%d-%Y')
# 讀取資料
df = pd.read_table('https://raw.githubusercontent.com/ffzs/dataset/master/time_series.txt', delimiter='\t', index_col='date', date_parser=date_parse)
# 將列轉換為float32型別
ts_data = df['number'].astype('float32')
print ('data summary')
# 列印輸出時間序列資料概況
print (ts_data.describe())

# 多次用到的表格
def pre_table(table_name, table_rows):
'''
:param table_name: 表格名稱,字串列表
:param table_rows: 表格內容,巢狀列表
:return: 展示表格物件
'''
table = prettytable.PrettyTable() # 建立表格例項
table.field_names = table_name # 定義表格列名
for i in table_rows: # 迴圈讀多條資料
table.add_row(i) # 增加資料
return table
# 穩定性(ADF)檢驗
def adf_val(ts, ts_title, acf_title, pacf_title):
'''
:param ts: 時間序列資料,Series型別
:param ts_title: 時間序列圖的標題名稱,字串
:param acf_title: acf圖的標題名稱,字串
:param pacf_title: pacf圖的標題名稱,字串
:return: adf值、adf的p值、三種狀態的檢驗值
'''
plt.figure()
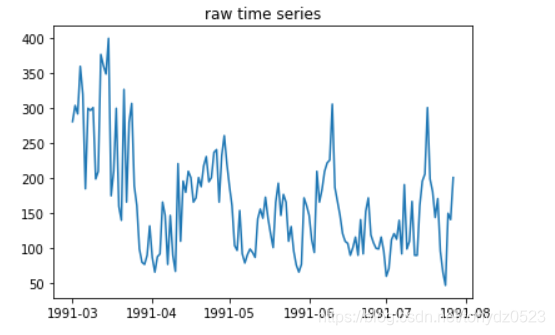
plt.plot(ts) # 時間序列圖
plt.title(ts_title) # 時間序列標題
plt.show()
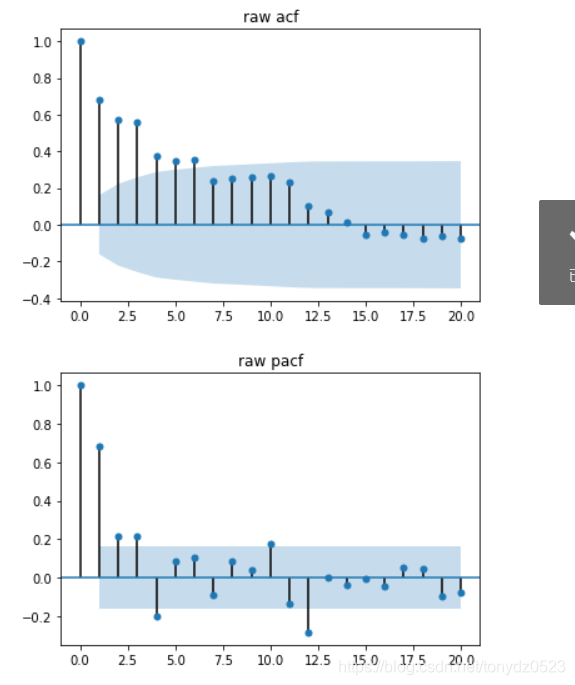
plot_acf(ts, lags=20, title=acf_title).show() # 自相關檢測
plot_pacf(ts, lags=20, title=pacf_title).show() # 偏相關檢測
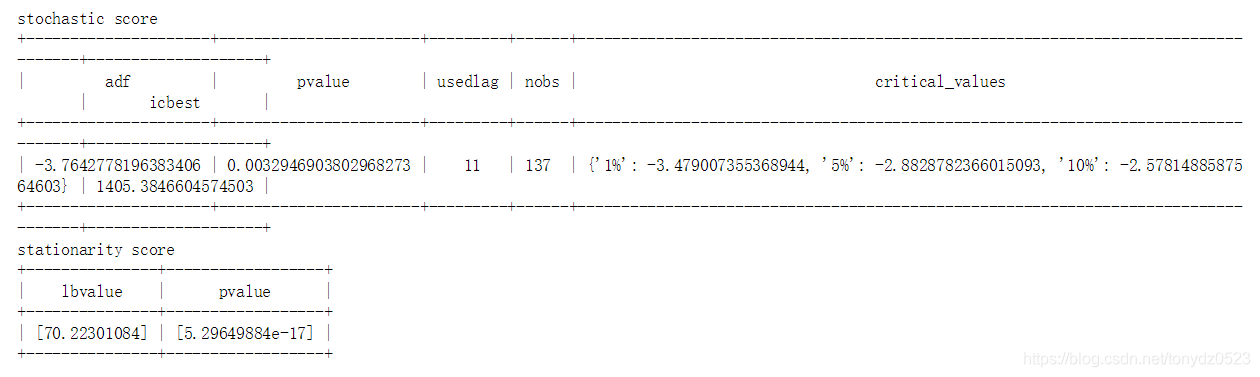
adf, pvalue, usedlag, nobs, critical_values, icbest = adfuller(ts) # 穩定性(ADF)檢驗
table_name = ['adf', 'pvalue', 'usedlag', 'nobs', 'critical_values', 'icbest'] # 表格列名列表
table_rows = [[adf, pvalue, usedlag, nobs, critical_values, icbest]] # 表格行資料,巢狀列表
adf_table = pre_table(table_name, table_rows) # 獲得平穩性展示表格物件
print ('stochastic score') # 列印標題
print (adf_table) # 列印展示表格
return adf, pvalue, critical_values, # 返回adf值、adf的p值、三種狀態的檢驗值
# 白噪聲(隨機性)檢驗
def acorr_val(ts):
'''
:param ts: 時間序列資料,Series型別
:return: 白噪聲檢驗的P值和展示資料表格物件
'''
lbvalue, pvalue = acorr_ljungbox(ts, lags=1) # 白噪聲檢驗結果
table_name = ['lbvalue', 'pvalue'] # 表格列名列表
table_rows = [[lbvalue, pvalue]] # 表格行資料,巢狀列表
acorr_ljungbox_table = pre_table(table_name, table_rows) # 獲得白噪聲檢驗展示表格物件
print ('stationarity score') # 列印標題
print (acorr_ljungbox_table) # 列印展示表格
return pvalue # 返回白噪聲檢驗的P值和展示資料表格物件
##### 原始資料檢驗 ####
# 穩定性檢驗
adf, pvalue1, critical_values = adf_val(ts_data, 'raw time series', 'raw acf', 'raw pacf')
# 白噪聲檢驗
pvalue2 = acorr_val(ts_data)
# 資料平穩處理
def get_best_log(ts, max_log=5, rule1=True, rule2=True):
'''
:param ts: 時間序列資料,Series型別
:param max_log: 最大log處理的次數,int型
:param rule1: rule1規則布林值,布林型
:param rule2: rule2規則布林值,布林型
:return: 達到平穩處理的最佳次數值和處理後的時間序列
'''
if rule1 and rule2: # 如果兩個規則同時滿足
return 0, ts # 直接返回0和原始時間序列資料
else: # 只要有一個規則不滿足
for i in range(1, max_log): # 迴圈做log處理
ts = np.log(ts) # log處理
adf, pvalue1, usedlag, nobs, critical_values, icbest = adfuller(ts) # 穩定性(ADF)檢驗
lbvalue, pvalue2 = acorr_ljungbox(ts, lags=1) # 白噪聲(隨機性)檢驗
rule_1 = (adf < critical_values['1%'] and adf < critical_values['5%'] and adf < critical_values[
'10%'] and pvalue1 < 0.01) # 穩定性(ADF)檢驗規則
rule_2 = (pvalue2 < 0.05) # 白噪聲(隨機性)規則
rule_3 = (i < 5)
if rule_1 and rule_2 and rule_3: # 如果同時滿足條件
print ('The best log n is: {0}'.format(i)) # 列印輸出最佳次數
return i, ts # 返回最佳次數和處理後的時間序列
# 還原經過平穩處理的資料
def recover_log(ts, log_n):
'''
:param ts: 經過log方法平穩處理的時間序列,Series型別
:param log_n: log方法處理的次數,int型
:return: 還原後的時間序列
'''
for i in range(1, log_n + 1): # 迴圈多次
ts = np.exp(ts) # log方法還原
return ts # 返回時間序列
#### 對時間序列做穩定性處理 #####
# 穩定性檢驗規則
rule1 = (adf < critical_values['1%'] and adf < critical_values['5%'] and adf < critical_values[
'10%'] and pvalue1 < 0.01)
# 白噪聲檢驗的規則
rule2 = (pvalue2[0,] < 0.05)
# 使用log進行穩定性處理
log_n, ts_data = get_best_log(ts_data, max_log=5, rule1=rule1, rule2=rule2)
#### 穩定後資料進行檢驗 ####
# 穩定性檢驗
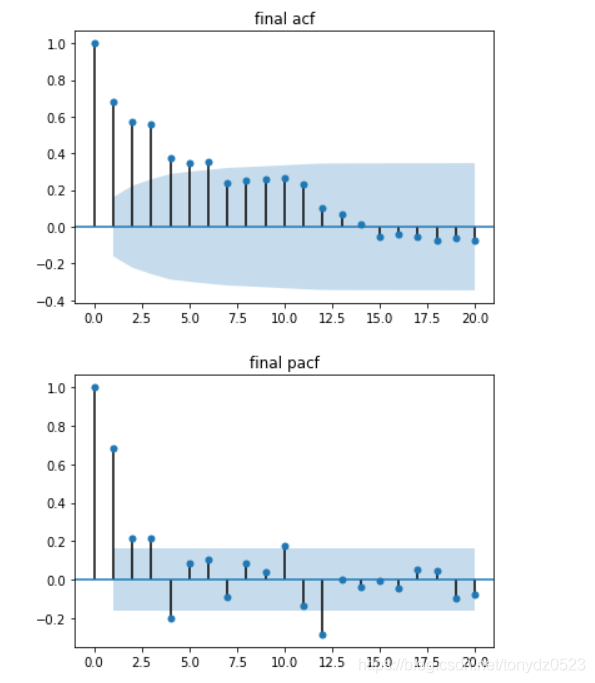
adf, pvalue1, critical_values = adf_val(ts_data, 'final time series', 'final acf', 'final pacf')
# 白噪聲檢驗
pvalue2 = acorr_val(ts_data)
穩定性符合要求
# arma最優模型訓練
def arma_fit(ts):
'''
:param ts: 時間序列資料,Series型別
:return: 最優狀態下的p值、q值、arma模型物件、pdq資料框和展示引數表格物件
'''
max_count = int(len(ts) / 10) # 最大迴圈次數最大定義為記錄數的10%
bic = float('inf') # 初始值為正無窮
tmp_score = [] # 臨時p、q、aic、bic和hqic的值的列表
print ('each p/q traning record') # 列印標題
print('p q aic bic hqic')
for tmp_p in range(max_count + 1): # p迴圈max_count+1次
for tmp_q in range(max_count + 1): # q迴圈max_count+1次
model = ARMA(ts, order=(tmp_p, tmp_q)) # 建立ARMA模型物件
try:
# ARMA模型訓練 disp不列印收斂資訊 method條件平方和似然度最大化
results_ARMA = model.fit(disp=-1, method='css')
except:
continue # 遇到報錯繼續
finally:
tmp_aic = results_ARMA.aic # 模型的獲得aic
tmp_bic = results_ARMA.bic # 模型的獲得bic
tmp_hqic = results_ARMA.hqic # 模型的獲得hqic
print('{:2d}|{:2d}|{:.8f}|{:.8f}|{:.8f}'.format(tmp_p, tmp_q, tmp_aic, tmp_bic, tmp_hqic))
tmp_score.append([tmp_p, tmp_q, tmp_aic, tmp_bic, tmp_hqic]) # 追加每個模型的訓練引數和結果
if tmp_bic < bic: # 如果模型bic小於最小值,那麼獲得最優模型ARMA的下列引數:
p = tmp_p # 最優模型ARMA的p值
q = tmp_q # 最優模型ARMA的q值
model_arma = results_ARMA # 最優模型ARMA的模型物件
aic = tmp_bic # 最優模型ARMA的aic
bic = tmp_bic # 最優模型ARMA的bic
hqic = tmp_bic # 最優模型ARMA的hqic
pdq_metrix = np.array(tmp_score) # 將巢狀列表轉換為矩陣
pdq_pd = pd.DataFrame(pdq_metrix, columns=['p', 'q', 'aic', 'bic', 'hqic']) # 基於矩陣建立資料框
table_name = ['p', 'q', 'aic', 'bic', 'hqic'] # 表格列名列表
table_rows = [[p, q, aic, bic, hqic]] # 表格行資料,巢狀列表
parameter_table = pre_table(table_name, table_rows) # 獲得最佳ARMA模型結果展示表格物件
# print ('each p/q traning record') # 列印標題
# print (pdq_pd) # 列印輸出每次ARMA擬合結果,包含p、d、q以及對應的AIC、BIC、HQIC
print ('best p and q') # 列印標題
print (parameter_table) # 輸出最佳ARMA模型結果展示表格物件
return model_arma # 最優狀態下的arma模型物件
# 模型訓練和效果評估
def train_test(model_arma, ts, log_n, rule1=True, rule2=True):
'''
:param model_arma: 最優ARMA模型物件
:param ts: 時間序列資料,Series型別
:param log_n: 平穩性處理的log的次數,int型
:param rule1: rule1規則布林值,布林型
:param rule2: rule2規則布林值,布林型
:return: 還原後的時間序列
'''
train_predict = model_arma.predict() # 得到訓練集的預測時間序列
if not (rule1 and rule2): # 如果兩個條件有任意一個不滿足
train_predict = recover_log(train_predict, log_n) # 恢復平穩性處理前的真實時間序列值
ts = recover_log(ts, log_n) # 時間序列還原處理
ts_data_new = ts[train_predict.index] # 將原始時間序列資料的長度與預測的週期對齊
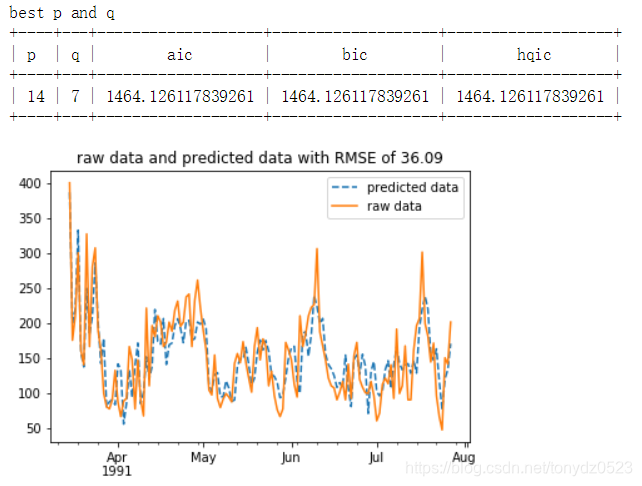
RMSE = np.sqrt(np.sum((train_predict - ts_data_new) ** 2) / ts_data_new.size) # 求RMSE
# 對比訓練集的預測和真實資料
plt.figure() # 建立畫布
train_predict.plot(label='predicted data', style='--') # 以虛線展示預測資料
ts_data_new.plot(label='raw data') # 以實線展示原始資料
plt.legend(loc='best') # 設定圖例位置
plt.title('raw data and predicted data with RMSE of %.2f' % RMSE) # 設定標題
plt.show() # 展示影象
return ts # 返回還原後的時間序列
# 訓練最佳ARMA模型並輸出相關引數和物件
model_arma = arma_fit(ts_data)
# 模型訓練和效果評估
ts_data = train_test(model_arma, ts_data, log_n, rule1=rule1, rule2=rule2)
# 預測未來指定時間項的資料
def predict_data(model_arma, ts, log_n, start, end, rule1=True, rule2=True):
'''
:param model_arma: 最優ARMA模型物件
:param ts: 時間序列資料,Series型別
:param log_n: 平穩性處理的log的次數,int型
:param start: 要預測資料的開始時間索引
:param end: 要預測資料的結束時間索引
:param rule1: rule1規則布林值,布林型
:param rule2: rule2規則布林值,布林型
:return: 無
'''
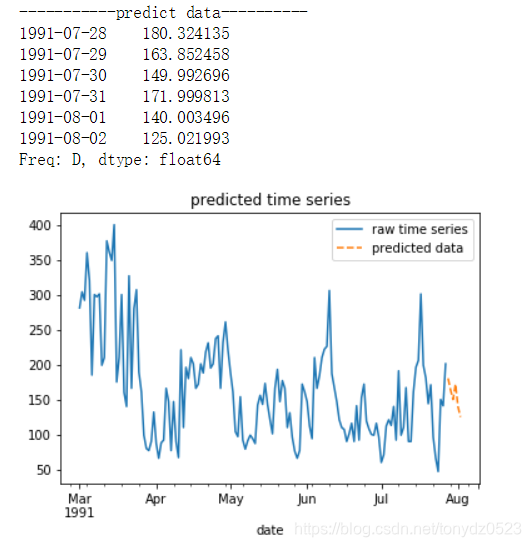
predict_ts = model_arma.predict(start=start, end=end) # 預測未來指定時間項的資料
print ('-----------predict data----------') # 列印標題
if not (rule1 and rule2): # 如果兩個條件有任意一個不滿足
predict_ts = recover_log(predict_ts, log_n) # 還原資料
print (predict_ts) # 展示預測資料
# 展示預測趨勢
plt.figure() # 建立畫布
ts.plot(label='raw time series') # 設定推向標籤
predict_ts.plot(label='predicted data', style='--') # 以虛線展示預測資料
plt.legend(loc='best') # 設定圖例位置
plt.title('predicted time series') # 設定標題
plt.show() # 展示影象
#### 模型預測應用 ####
# 設定時間
start = '1991-07-28'
end = '1991-08-02'
# 預測
predict_data(model_arma, ts_data, log_n, start, end, rule1=rule1, rule2=rule2)
補充:
statsmodels中的ARMA
statsmodels常用的時間序列模型包括AR、ARMA和ARIMA,並都集中在statsmodels. tsa.arima_model下面。ARMA(p, q)是AR§和MA(q)模型的組合,關於p和q的選擇,一種方法是觀察自相關圖ACF和偏相關圖PACF,通過截尾、拖尾等資訊分析應用的模型以及適應的p和q的階數;另一種方法是通過迴圈的方法,遍歷所有條件並通過AIC、BIC值自動確定階數。
ARMA(以及statsmodels中的其他演算法)跟sklearn中的演算法類似,也都有方法和屬性兩種應用方式。常用的ARMA方法:
- fit:使用卡爾曼濾波器的最大似然法擬合ARMA模型。
- from_formula:基於給定的公式和資料框建立模型。
- geterrors:基於給定的引數獲取ARMA程序的錯誤。
- hessian:基於給定的引數計算Hessian資訊。
- loglike:計算ARMA模型的對數似然。
- loglike_css:條件求和方差似然函式。
- predict:應用ARMA模型做預測。
- score:得分函式。
參考:
《python資料分析與資料化運營》 宋天龍