
推薦系統之資訊繭房問題
什麼是資訊繭房
資訊繭房其實是現在社會一個很可怕的現象,從字面意思來看的話其實比喻的是資訊被蟲繭一般封鎖住。這個問題反映了現在隨著個性化推薦的普及衍射的一個社會問題。
![]()

平時在瀏覽新聞或者淘寶的時候,平臺會自動根據使用者的瀏覽記錄獲取使用者的偏好,然後推送感興趣的文章。久而久之,比如使用者A是個體育迷,那麼A獲取的資訊大多是跟體育相關的,很難獲取音樂或者軍事等其它相關的資訊,因為平臺追求點選率,會一直推送A感興趣的內容以獲取高廣告瀏覽量。時間長了,因為資訊繭房的作用,因為資訊獲取單一,A的社交圈可能也會變的狹小。如果整個社會陷入了個性化推薦系統的資訊繭房效應,將是病態的。
所以,真正的個性化推薦絕對不等於只推薦歷史感興趣的內容,這樣其實不是一個長期可持續的推薦系統,如果陷入了資訊繭房,一定會有使用者覺得審美疲勞。那麼如何破解資訊繭房,因為從推薦模型角度分析,一旦獲取了使用者的畫像,就很難跳出使用者習慣的邏輯,比如昨天買個手機,第二天還推薦手機,這個時候可能比較好的一種方法是跨域推薦(cross-domain recommendation)。
跨域推薦的概念
跨域推薦做的事情就是跳出推薦的資訊繭房。不是一個新概念了,我上研究生的時候學校就有實驗室做相關的研究,今天主要講下思路。具體大家想了解的話可以看下這個Paper: 《Cross-Domain Recommendation: An Embedding and Mapping Approach》
有幾個關鍵詞我覺得可以充分體現跨域推薦的精髓:
“diversity” - “novelty” - “serendipity”
如果我們做一個推薦系統,說是“individuality”,其實我會覺得很normal,不夠高階,現在幾乎所有推薦系統都有個性化推薦,但是如果一個推薦系統標榜自己是“novelty”,那我就覺得很有意思了。下面聊聊怎麼實現novelty。
第一步:確定什麼是target & source
這裡以新聞推薦為例,如果一使用者A,經常瀏覽同一個型別的新聞,比如體育新聞,如何找到A喜歡的其他類別新聞呢?
![]()
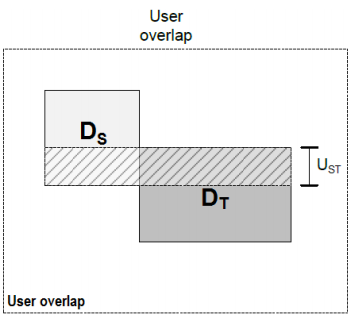
這其實是一個user overlap的場景,推薦系統的主體user不變,有個source源是體育新聞,要找到target是體育以外user感興趣的文章。這就建立了跨域推薦中的target和source關係。
第二步:確定推薦level
跨域推薦有多種level,要確定跨域的種類,大體可以分以下三種:![]()

其實跨域推薦確定了source和target後只要確定跨域的幅度即可。
-
Attribute level:挖掘target間的相似屬性,推薦同一類別的target。比如一個使用者很喜歡買紅色、大尺寸的諾基亞手機,attribute level推薦是要在推薦物屬性層面做跨域,可以試著給使用者推薦黑色、小尺寸的其它手機,這樣的跨屬性的相同物種推薦會在一定程度上給使用者新鮮感
-
Type level:挖掘target間的相似屬性,然後推薦相同大品類下不同小品類的物品。比如使用者喜歡紅色、大尺寸的諾基亞手機,手機和電腦都屬於電子產品,可以推薦紅色、大尺寸的電腦給使用者
-
Item level:挖掘target間的相似屬性,推薦不同大品類的物品。比如使用者喜歡紅色、大尺寸的諾基亞手機,直接推薦紅色大尺寸的馬桶
以上3個跨域level由輕到重,大家可以根據自己的需求選用。其實關鍵點是如何挖掘物品的屬性,因為無論是電腦、手機、馬桶,他們都有共通的屬性,比如大小、顏色、材質等,下面就介紹如何挖掘這些屬性。
第三步:挖掘target間的屬性
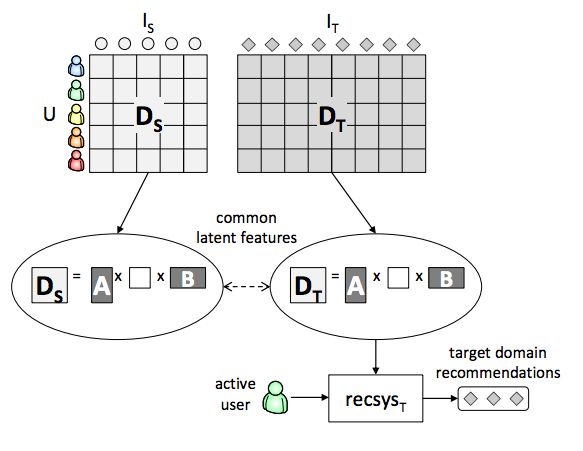
既然跨域推薦的關鍵是能挖掘出target間共有的屬性,那麼有什麼辦法可以做到這一點呢。首先要根據業務屬性人工挖掘出一些隱性特徵,比如電商平臺可以挖掘出顏色、材質、價格、使用頻率等隱性特徵,然後可以通過矩陣分解的方式獲取具體每個特徵的權重(下圖中矩陣A和B之間的矩陣)。
![]()
總結
資訊繭房效應是因為個性化推薦系統推薦資訊的不平衡性,導致使用者長期只能瀏覽限制領域的資訊,可以在推薦系統中加入跨域推薦的邏輯來規避資訊繭房的影響,具體流程包含確定推薦邏輯中的source和target,確定跨域的粒度,通過矩陣分解找出隱含的共性屬性。
參考:https://recsys.acm.org/wp-content/uploads/2014/10/recsys2014-tutorial-cross_domain.pdf