
海量資料探勘MMDS week4: 推薦系統之資料降維Dimensionality Reduction
海量資料探勘Mining Massive Datasets(MMDs) -Jure Leskovec courses學習筆記 推薦系統Recommendation System之降維Dimensionality Reduction
{部落格內容:推薦系統有一種推薦稱作隱語義模型(LFM, latent factor model)推薦,這種推薦將在下一篇部落格中講到。這篇部落格主要講隱語義模型的基礎:降維技術,包括SVD分解等等}
降維Dimensionality Reduction
降維介紹
資料的低維表示:空間中的點不是完全隨機分佈的,而是分佈lie in在它的一個子空間中。我們的目標就是找到這個可以有效表示所有資料的子空間。
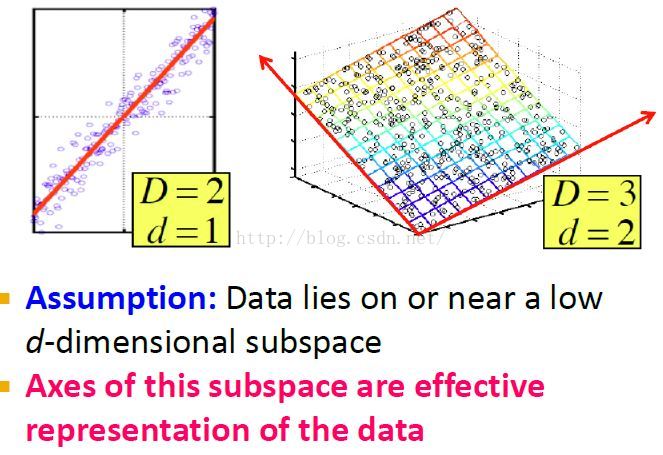
降維示例
customer-day矩陣中行表示data(也就是點),列代表資料屬性(也就是點的座標)。降維就是要減少屬性(列)。

這個矩陣實際只有2維,wc-th-fr和sa-su。
資料集的維度
矩陣的秩

矩陣A的秩就是A中列的無關最大組數目。下面的是座標重新定義後A矩陣的表示。
秩即維數
通過秩來進行座標重定義,用新座標重新表示A矩陣,達到降維目的。

降維的實質
實質是找到一個新的資料軸。

這個例子中,我們只考慮資料在紅線上的投影,而忽略與紅線的距離,存在一定的error。目標就是找到一個新座標軸讓error儘量小。
降維的目的

UV分解

UV分解示例

UV分解誤差度量RMSE
我們一般通過RMSE(Root-Mean-Square Error, 均方根誤差)度量UV和M的相近程度。

UV分解的增量式計算
{尋找具有最小RMSE的UV分解過程:初始任意選擇UV,然後反覆調整UV使得RMSE越來越小}

初始化

增量計算-對特定元素優化的示例




增量計算-對任意元素的優化。。。
完整UV分解演算法的構建

1. 預處理

2.初始化

3. 執行優化

4. 收斂到極小值

5. 避免過擬合

奇異值分解Singular Value Decomposition, SVD
{資料降維技術}
SVD定義

這裡假設奇異值對角矩陣中的奇異值是降序排列的。


[矩陣論]
SVD分解的性質

Note: U、V列向量是正交的orthogonal,也就是說向量間內積為0。
SVD分解例項
users-movies矩陣,其中行代表使用者,每列代表一部電影。

concepts就是SVD分解要告訴我們的,使用者是sci-fi lover和romance lover型別,電影是sci-fi和romance等型別。也就是不同的genres(流派), or topics。
SVD分解中各分解分量的實際意義解釋
下面是通過matlab或者python對矩陣A進行SVD分解得到的結果。下面分別講解U V矩陣代表的實際含義(注意這種解釋性也是人為解釋的,其實SVD分解的解釋性並沒有那麼強)。

我們可以將U的列看成concepts,如U的第一列對應Sci-Fi concept,第二列對應romance concept(第三列可能代表其它的什麼,其實不一定能用一個類別來描述和解釋,因為SVD其解釋性並不是那麼強)。我們從這裡可以看到,前4個使用者衷情於sic-fi,後3個使用者衷情於romance。
於是我們可以將U矩陣看成是user to concept matrix(user to concept similarity matrix)。其中元素代表某個使用者對某個concepts的感興趣程度。這裡是說第1個使用者很喜歡sci-fi concept(0.13),而第5個使用者很喜歡romance concept(-0.59)。至於-0.59代表最喜歡的concept,可能是要看它的絕對值?

Sigma矩陣中的值可看做是concepts的強度,如sci-fi concept強度(12.4)就比romance concept的強度(9.5)強。

同樣的,我們可以將V矩陣看成是movies to concept matrix(movies to concept similarity matrix)。注意這裡還有第三種concepts,但是其強度1.3太小,可以忽略。
從V矩陣第1列我們可以看到,第1部電影與第1個concept和第3個concept相關度高,然而第3個concept的強度過低,它對解釋資料並不重要。
使用concept space進行查詢
如果原始矩陣中沒有的一個新使用者Qurncy看了一部電影The Matrix,評分為4,則Qurncy的向量表示為q=[4,0,0,0,0]。
當然使用協同過濾,不過這裡可以通過qV將Qurncy map到concept space中,其中qV = [2.32, 0],說明Qurncy對scifi有很大興趣,對romance幾乎沒有興趣。
map回movie space,qVVT = [1.35, 1.35, 1.35, 0, 0],也就是說Qurncy會喜歡Alien and Star Wars, but not Casablanca or Titanic。
可以將所有使用者都map到concept space中,再計算他們的cosin相似度。
SVD分解的計算


Note: m*n矩陣A的奇異值是矩陣乘積AAH的特徵值(這些特徵值是非負的)的正平方根。


當然可以使用軟體來代替手動計算,如scipy中linalg.svd(A)
CUR分解
SVD分解的缺點在於:
計算比較耗時
儲存矩陣比較佔空間
CUR分解是另外一個選擇,其目標是:找到輸入矩陣的一個“儘可能好”的分解為三個矩陣的乘積,SVD分解是完美的分解(通過允許誤差來加速計算)。
U矩陣構造

C矩陣構造
計算M所有資料平方和f,取出的行數為r
計算選取列的縮放scale因子

R矩陣構造
同C,只是概率(縮放因子計算是對行來說的)
CUR分解示例
對下面矩陣進行CUR分解

假設選取列Matrix, Alien,和行Jim, John。
所有元素平方和為243
Matrix, Alien和Star Wars的squared Frobenius norm為1^2 + 3^2 + 4^2 + 5^2 = 51,故縮放因子即概率為51/243 = .210。其它兩列的概率為45/243 = .185。
7行的squared Frobenius norms分別為3, 27, 48, 75, 32,50, 8,相應的概率為.012, .111, .198,.309, .132, .206, .033.
C矩陣構造
C矩陣中選擇了Alien列和Matrix 列,則

R矩陣的構造
R矩陣選擇了行Jim, John。

U矩陣的構造
W矩陣為

W的SVD分解結果為:
u:
[[-0.6-0.8]
[-0.8 0.6]]
e:
[ 7.0711 0. ]
v:
[[-0.7071-0.7071]
[-0.7071 0.7071]]
1/e =
[[0.1414 0. ]
[ 0. 0. ]]

故M矩陣的CUR分解為:

[Anand.Rajaraman-Mining of Massive Datasets-mmds2014:CUR Decomposition]
。。。
Review複習
標準正交基

計算出各個選項的長度(2範數)和與[2/7...]的內積為:
0.771042151896
-0.125
1.00021697646
0.000142857142857
2.42383992871
-0.214285714286
1.00014298978
0.735
故選擇選項2
Code:
a = np.array([2 / 7, 3 / 7, 6 / 7]) B = [[.608, -.459, -.119], [.728, .485, -.485], [2.250, -.500, -.750], [.429, .857, .286]] for b in B: print(np.linalg.norm(b)) print(a.dot(b)) print()
PCA

ref: Anand.Rajaraman-大資料:網際網路大規模資料探勘與分散式處理