
利用htmlunit和jsoup來實現爬取js的動態網頁實踐(執行js)
更新,這就尷尬了,這篇文章部落格閱讀文章最多,但是被踩得也最多。
爬取思路:
所謂動態,就是通過請求後臺,可以動態的改變相應的html頁面,頁面並不是一開始就全部展現出來的。
大部分操作都是通過請求完成的,一次請求,一次返回。而在大多數網頁中請求往往都被開發者隱藏在了js程式碼中。
所以爬取動態網頁的思路就轉化為找出相應的js程式碼,並且執行相應的js程式碼,從而能夠通過java程式碼動態的改變頁面。
而當頁面能夠正確顯示出來,我們也就可以類似於爬取靜態網頁般去爬取資料啦!
首先,可以利用htmlunit來模擬滑鼠點選事件,這個容易實現:
/** * 通過htmlunit來獲得一些搜狗的網址。 * 通過模擬滑鼠點選事件來實現 * @param key * @return * @throws Exception */ public String getNextUrl(String key){ String page = new String(); try { WebClient webClient = new WebClient(); webClient.getOptions().setCssEnabled(false); webClient.getOptions().setJavaScriptEnabled(false); //去拿網頁 HtmlPage htmlPage = webClient.getPage("http://pic.sogou.com/"); //得到表單 HtmlForm form = htmlPage.getFormByName("searchForm"); //得到提交按鈕 HtmlSubmitInput button = form.getInputByValue("搜狗搜尋"); //得到輸入框 HtmlTextInput textField = form.getInputByName("query"); //輸入內容 textField.setValueAttribute(key); //點一下按鈕 HtmlPage nextPage = button.click(); String str = nextPage.toString(); page = cutString(str); webClient.close(); } catch (Exception e) { e.printStackTrace(); } return page; }
如上圖所示,我就是通過java程式碼,向搜尋礦中填入關鍵字,然後在通過getInputByValue方法獲得button控制元件,最後直接button.click(),
即可以模擬點選,並且把點選後的返回的http請求解析到htmlpage中。

接下來就是利用強大的htmlunit來執行js程式碼的過程了。
首先寫一個簡單的jsp頁面:
由上可知,jsp頁面很簡單,就一個函式change,用於給htmlUnit呼叫。<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>Insert title here</title> </head> <body id="body"> <label id="test">原數字</label> </body> <script type="text/javascript"> function change(value) { document.getElementById("test").innerHTML = value; return "hello htmlUnit"; } </script> </html>
再下來就是一個使用htmlunit的類。該類通過支援JavaScript直譯器,
然後在頁面中嵌入自己寫的JavaScript程式碼從而執行,並且獲得執行後的返回結果以及返回頁面。
在t.getNewPage()中有兩個屬性,一個是package com.blog.anla; import com.gargoylesoftware.htmlunit.ScriptResult; import com.gargoylesoftware.htmlunit.WebClient; import com.gargoylesoftware.htmlunit.html.HtmlPage; public class TestMyOwnPage { private void action() { WebClient webClient = new WebClient(); try { webClient.getOptions().setCssEnabled(false); webClient.getOptions().setJavaScriptEnabled(true); // 設定支援JavaScript。 // 去拿網頁 HtmlPage htmlPage = webClient .getPage("http://localhost:8989/testHtmlScrop/index.jsp"); String s = "更改後的數字"; ScriptResult t = htmlPage.executeJavaScript("change(\"" + s + "\");", "injected script", 500); // 這裡是在500行插入這一小行JavaScript程式碼段,因為如果在預設的1行,那不會有結果 // 因為js是順序執行的,當你執行第一行js程式碼時,可能還沒有渲染body裡面的標籤。 HtmlPage myPage = (HtmlPage) t.getNewPage(); String nextPage = myPage.asXml().toString(); String nextPage2 = myPage.asText().toString(); } catch (Exception e) { e.printStackTrace(); } finally { webClient.close(); } } public static void main(String[] args) { TestMyOwnPage tmop = new TestMyOwnPage(); tmop.action(); } }
javaScriptResult:執行該段程式碼後返回的結果,如果有(如上我寫的,就返回hello htmlunit),如果沒有(返回Undefined)。
newPage_:執行該段程式碼後返回的整個頁面。
結果如圖:
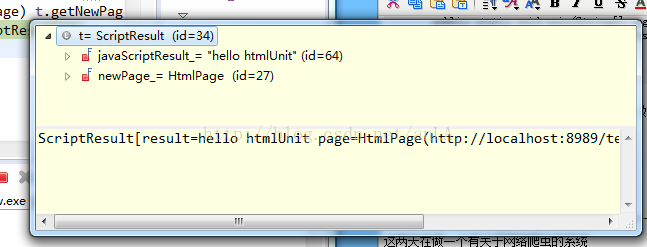
最終這段程式碼執行的結果如下:
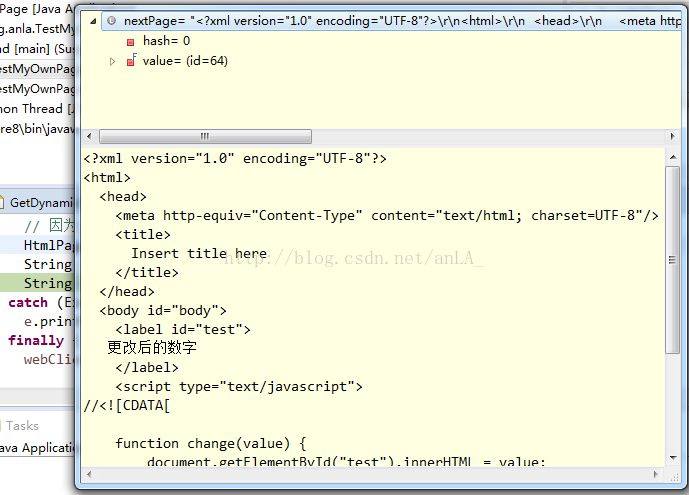
asXml():將整個頁面的html程式碼返回給我們:
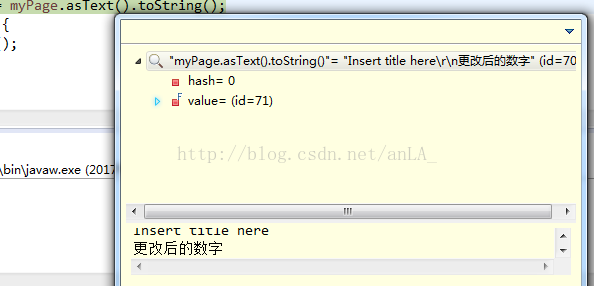
而asText()則僅僅返回頁面上能顯示的值,即head和label標籤:
這樣的執行思路也就能夠去動態的執行相應的js程式碼,從而爬取到需要的資料了。
----------------------------------------------------------------------------------------2017年7月更新--------------------------------------------------------------------------------------------------------
這兩天在做一個有關於網路爬蟲的系統
但是呢,一開始爬的時候就發現問題,js的動態頁面的爬不下來
網上找了好多方法,google也問了,主要還是提到htmlunit,以下是核心程式碼,
使用htmlunit主要就是為了模擬瀏覽器操作,因為有些連結點選無法直接通過src來獲得url,而通常使用JavaScript
進行簡單拼接後的網址,所以這樣一來,使用htmlunit直接來模擬瀏覽器點選,相比來說就更加的簡單了。
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //啟用JS直譯器,預設為true
webClient.getOptions().setCssEnabled(false); //禁用css支援
webClient.getOptions().setThrowExceptionOnScriptError(false); //js執行錯誤時,是否丟擲異常
webClient.getOptions().setTimeout(20000);
HtmlPage page = wc.getPage("http://www.hao123.com");
//我認為這個最重要
String pageXml = page.asXml(); //以xml的形式獲取響應文字
/**jsoup解析文件*/
Document doc = Jsoup.parse(pageXml, "http://cq.qq.com"); 這個時候,就可以得到jsoup中的document物件了,接下來就好寫了,就像爬普通靜態網頁一樣了。
不過,webclient解析是還是會出現一些問題,js的問題,
主要是由於目標url的js寫的有些問題,但在實際的瀏覽器中卻會忽略,eclipse中會報異常。
今天一看,好多人踩啊哈,可能當時並沒有認真的寫部落格吧,如果大家想找一個java爬蟲的專案,可以去我的專欄
圖片搜尋 包括使用jsoup來爬圖,以及lire來建立索引以及搜尋圖片。
贈人玫瑰手留餘香,有問題的大家可以多多討論呀!