
機器學習實戰——KNN演算法改進約會網站配對效果
阿新 • • 發佈:2018-12-26
背景:
將約會網站的人分為三種類型:不喜歡的,魅力一般的,極具魅力的,分別用數字1,2,3表示,這些是樣本的標籤。樣本特徵為,每年飛行里程,玩視訊遊戲佔百分比,每週消費冰淇淋公升數。
檔案格式如下:

首先要解析文字。程式碼如下:
def file2matrix(filename): fr=open(filename) arrayOLines=fr.readlines() numberOfLines=len(arrayOLines)#檔案的行數 returnMat=zeros((numberOfLines,3)) classLabelVector=[] index=0 for line in arrayOLines: line=line.strip()#截取回車字元 listFromLine=line.split('\t')#使用'\t'分割成元素列表 returnMat[index,:]=listFromLine[0:3] #第index行 為listfromline前3個元素 classLabelVector.append(int(listFromLine[-1])) #新增分類標籤 index+=1 return returnMat,classLabelVector
描繪散點圖
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
fig=plt.figure() #建立一個圖形示例
ax=fig.add_subplot(111)#將畫布分成1行1列,並且畫在從左往右從上往下的第一塊
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels)) #描繪散點圖
plt.show()

這麼看來關係好像不大。。。
歸一化
通過下表可以看出,飛行里程數對計算結果的影響遠大於其他兩個。但是我們認為這三個對結果的影響應該是一樣的,那麼就應該歸一化數值。即把每個特徵的最小值最大值求出,最小值賦值為0,最大的賦值為1,其他的按比例進行計算。

def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-tile(minVals,(m,1))
normDataSet=normDataSet/tile(ranges,(m,1))
return normDataSet,ranges,minVals歸一化以後就可以使用k近鄰演算法了。
不過我們得留10%的資料進行測試,這些測試資料得是隨機的。
def datingClassTest():
hoRatio=0.10 #10%測試
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt') #解析文字
normMat,ranges,minVals=autoNorm(datingDataMat)#歸一化
m=normMat.shape[0] #文字行數
numTestVecs=int(m*hoRatio) #測試集的數量
errorCount=0.0 #初始化錯誤的數量
for i in range(numTestVecs):
#訓練,四個引數分別為測試集,訓練集,標籤,k,第一個表示第i行全部資料,第二個為從測試集第一行到文字最後一行
#第三個為測試集的標籤,k選取3
classifierResult=classify0(normMat[i,:],normMat[numTestVecs:m,:],\
datingLabels[numTestVecs:m],3)
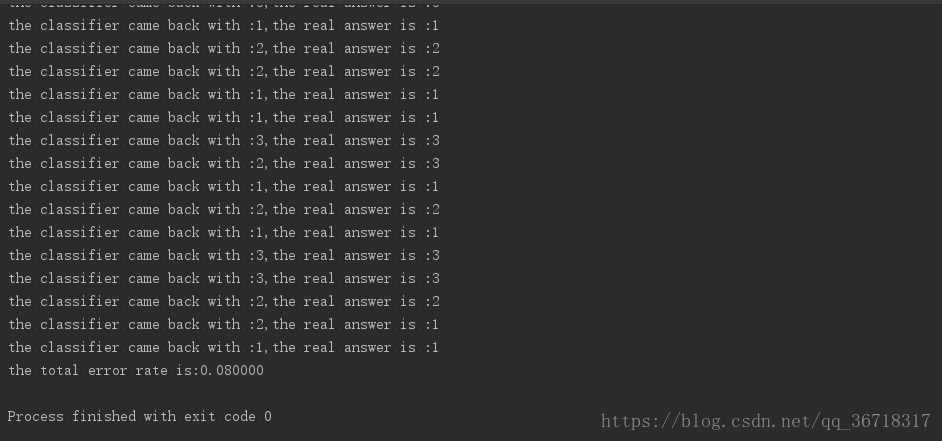
print("the classifier came back with :%d,the real answer is :%d"\
%(classifierResult,datingLabels[i])) #列印預測結果和真實值
if(classifierResult!=datingLabels[i]):errorCount+=1.0 #如果錯了,錯誤數量+1
print("the total error rate is:%f" %(errorCount/(float)(numTestVecs))) #計算錯誤率執行結果:
構建完整可用系統:
#構建完整可用系統
def classifyPerson():
resultList=['not at all','in small doses','in large doses'] #與1,2,3分別對應
#輸入三個引數
percentTats=float(input(\
"percentage of time spent playing video games?"))
ffMiles=float(input("frequent filer miles earned per year?"))
iceCream=float(input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat,ranges,minVals=autoNorm(datingDataMat)
inArr=array([ffMiles,percentTats,iceCream])
#測試集為輸入的,訓練集為整個文字
classifierResult=classify0((inArr-\
minVals)/ranges,normMat,datingLabels,3)
print("You will probably like this person:",\
resultList[classifierResult-1])執行結果:

總而言之感覺這個演算法好神奇的樣子,但是原理又並不是很難理解。