
Elasticsearch 通關教程(四): 分散式工作原理
前言
通過前面章節的瞭解,我們已經知道 Elasticsearch 是一個實時的分散式搜尋分析引擎,它能讓你以一個之前從未有過的速度和規模,去探索你的資料。它被用作全文檢索、結構化搜尋、分析以及這三個功能的組合。 Elasticsearch 可以橫向擴充套件至數百(甚至數千)的伺服器節點,同時可以處理PB級資料。
雖然說 Elasticsearch 是分散式的,但是對於我們開發者來說並未過多的參與其中,我們只需啟動對應數量的 ES 例項(即節點),並給它們分配相同的 cluster.name 讓它們歸屬於同一個叢集,建立索引的時候只需指定索引 分片數 和 副本數 即可,其他的都交給了 ES 內部自己去實現。
這和資料庫的分散式和 同源的 solr 實現分散式都是有區別的,資料庫分散式(分庫分表)需要我們指定路由規則和資料同步策略等,solr的分散式也需依賴 zookeeper,但是 Elasticsearch 完全遮蔽了這些。
所以我們說,Elasticsearch 天生就是分散式的,並且在設計時遮蔽了分散式的複雜性。Elasticsearch 在分散式方面幾乎是透明的。我們可以使用筆記本上的單節點輕鬆地執行Elasticsearch 的程式,但如果你想要在 100 個節點的叢集上執行程式,一切也依然順暢。
Elasticsearch 儘可能地遮蔽了分散式系統的複雜性。這裡列舉了一些在後臺自動執行的操作:
- 分配文件到不同的容器 或 分片 中,文件可以儲存在一個或多個節點中。
- 按叢集節點來均衡分配這些分片,從而對索引和搜尋過程進行負載均衡。
- 複製每個分片以支援資料冗餘,從而防止硬體故障導致的資料丟失。
- 將叢集中任一節點的請求路由到存有相關資料的節點。
- 叢集擴容時無縫整合新節點,重新分配分片以便從離群節點恢復。
雖然我們可以不瞭解 Elasticsearch 分散式內部實現機制也能將Elasticsearch使用的很好,但是瞭解它們將會從另一個角度幫助我們更完整的學習和理解 Elasticsearch 知識。接下里我們從以下幾個部分來詳細講解 Elasticsearch 分散式的內部實現機制。
叢集的原理
對於我們之前的分散式經驗,我們知道,提升分散式效能可以通過購買效能更強大( 垂直擴容 ,或 縱向擴容 ) 或者數量更多的伺服器( 水平擴容 ,或 橫向擴容 )來實現。
雖然Elasticsearch 可以獲益於更強大的硬體裝置,例如將儲存硬碟設為SSD,但是 垂直擴容 由於硬體裝置的技術和價格限制,垂直擴容 是有極限的。真正的擴容能力是來自於 水平擴容 --為叢集新增更多的節點,並且將負載壓力和穩定性分散到這些節點中。
對於大多數的資料庫而言,通常需要對應用程式進行非常大的改動,才能利用上橫向擴容的新增資源。 與之相反的是,ElastiSearch天生就是 分散式的 ,它知道如何通過管理多節點來提高擴容性和可用性。 這也意味著你的應用無需關注這個問題。那麼它是如何管理的呢?
主節點
啟動一個 ES 例項就是一個節點,節點加入叢集是通過配置檔案中設定相同的 cluste.name 而實現的。所以叢集是由一個或者多個擁有相同 cluster.name 配置的節點組成, 它們共同承擔資料和負載的壓力。當有節點加入叢集中或者從叢集中移除節點時,叢集將會重新平均分佈所有的資料。
與其他元件叢集(mysql,redis)的 master-slave模式一樣,ES叢集中也會選舉一個節點成為主節點,主節點它的職責是維護全域性叢集狀態,在節點加入或離開叢集的時候重新分配分片。具體關於主節點選舉的內容可以閱讀選舉主節點。
所有主要的文件級別API(索引,刪除,搜尋)都不與主節點通訊,主節點並不需要涉及到文件級別的變更和搜尋等操作,所以當叢集只擁有一個主節點的情況下,即使流量的增加它也不會成為瓶頸。 任何節點都可以成為主節點。如果叢集中就只有一個節點,那麼它同時也就是主節點。
所以如果我們使用 kibana 來作為檢視操作工具的話,我們只需在kibana.yml的配置檔案中,將elasticsearch.url: "http://localhost:9200"設定為主節點就可以了,通過主節點 ES 會自動關聯查詢所有節點和分片以及副本的資訊。所以 kibana 一般都和主節點在同一臺伺服器上。
作為使用者,我們可以將請求傳送到 叢集中的任何節點 ,包括主節點。 每個節點都知道任意文件所處的位置,並且能夠將我們的請求直接轉發到儲存我們所需文件的節點。 無論我們將請求傳送到哪個節點,它都能負責從各個包含我們所需文件的節點收集回資料,並將最終結果返回給客戶端。 Elasticsearch 對這一切的管理都是透明的。
發現機制
ES 是如何實現只需要配置相同的cluste.name就將節點加入同一叢集的呢?答案是發現機制(discovery module)。
發現機制 負責發現叢集中的節點,以及選擇主節點。每次叢集狀態發生更改時,叢集中的其他節點都會知道狀態(具體方式取決於使用的是哪一種發現機制)。
ES目前主要推薦的自動發現機制,有如下幾種:
- Azure classic discovery 外掛方式,多播
- EC2 discovery 外掛方式,多播
- Google Compute Engine (GCE) discovery 外掛方式,多播
- Zen discovery 預設實現,多播/單播
這裡額外介紹下單播,多播,廣播的定義和區別,方便我們更好的理解發現機制。
單播,多播,廣播的區別:
單播(unicast):網路節點之間的通訊就好像是人們之間的對話一樣。如果一個人對另外一個人說話,那麼用網路技術的術語來描述就是“單播”,此時資訊的接收和傳遞只在兩個節點之間進行。例如,你在收發電子郵件、瀏覽網頁時,必須與郵件伺服器、Web伺服器建立連線,此時使用的就是單播資料傳輸方式。
多播(multicast):“多播”也可以稱為“組播”,多播”可以理解為一個人向多個人(但不是在場的所有人)說話,這樣能夠提高通話的效率。因為如果採用單播方式,逐個節點傳輸,有多少個目標節點,就會有多少次傳送過程,這種方式顯然效率極低,是不可取的。如果你要通知特定的某些人同一件事情,但是又不想讓其他人知道,使用電話一個一個地通知就非常麻煩。多播方式,既可以實現一次傳送所有目標節點的資料,也可以達到只對特定物件傳送資料的目的。多播在網路技術的應用並不是很多,網上視訊會議、網上視訊點播特別適合採用多播方式。
廣播(broadcast):可以理解為一個人通過廣播喇叭對在場的全體說話,這樣做的好處是通話效率高,資訊一下子就可以傳遞到全體,廣播是不區分目標、全部發送的方式,一次可以傳送完資料,但是不區分特定資料接收物件。
上面列舉的發現機制中, Zen Discovery 是 ES 預設內建發現機制。它提供單播和多播的發現方式,並且可以擴充套件為通過外掛支援雲環境和其他形式的發現。所以我們接下來重點介紹下 Zen Discovery是如何在Elasticsearch中使用的。
叢集是由相同cluster.name的節點組成的。當你在同一臺機器上啟動了第二個節點時,只要它和第一個節點有同樣的 cluster.name 配置,它就會自動發現叢集並加入到其中。但是在不同機器上啟動節點的時候,為了加入到同一叢集,你需要配置一個可連線到的單播主機列表。
單播主機列表通過discovery.zen.ping.unicast.hosts來配置。這個配置在 elasticsearch.yml 檔案中:
discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]具體的值是一個主機陣列或逗號分隔的字串。每個值應採用host:port或host的形式(其中port預設為設定transport.profiles.default.port,如果未設定則返回transport.tcp.port)。請注意,必須將IPv6主機置於括號內。此設定的預設值為127.0.0.1,[:: 1]。
Elasticsearch 官方推薦我們使用 單播 代替 組播。而且 Elasticsearch 預設被配置為使用 單播 發現,以防止節點無意中加入叢集。只有在同一臺機器上執行的節點才會自動組成叢集。
雖然 組播 仍然作為外掛提供, 但它應該永遠不被使用在生產環境了,否則你得到的結果就是一個節點意外的加入到了你的生產環境,僅僅是因為他們收到了一個錯誤的 組播 訊號。對於 組播 本身並沒有錯,組播會導致一些愚蠢的問題,並且導致叢集變的脆弱(比如,一個網路工程師正在搗鼓網路,而沒有告訴你,你會發現所有的節點突然發現不了對方了)。
使用單播,你可以為 Elasticsearch 提供一些它應該去嘗試連線的節點列表。當一個節點聯絡到單播列表中的成員時,它就會得到整個叢集所有節點的狀態,然後它會聯絡 master 節點,並加入叢集。
這意味著你的單播列表不需要包含你的叢集中的所有節點,它只是需要足夠的節點,當一個新節點聯絡上其中一個並且說上話就可以了。如果你使用 master 候選節點作為單播列表,你只要列出三個就可以了。
關於 Elasticsearch 節點發現的詳細資訊,請參閱 Zen Discovery。
應對故障
對於分散式系統的熟悉,我們應該知道分散式系統設計的目的是為了提高可用性和容錯性。在單點系統中的問題在 ES 中同樣也會存在。
單節點的問題
如果我們啟動了一個單獨的節點,裡面不包含任何的資料和索引,那我們的叢集就是一個包含空內容節點的叢集,簡稱空叢集。

當叢集中只有一個節點在執行時,意味著會有一個單點故障問題——沒有冗餘。單點的最大問題是系統容錯性不高,當單節點所在伺服器發生故障後,整個 ES 服務就會停止工作。
讓我們在包含一個空節點的叢集內建立名為 user 的索引。索引在預設情況下會被分配5個主分片和每個主分片的1個副本, 但是為了演示目的,我們將分配3個主分片和一份副本(每個主分片擁有一個副本分片):
PUT /user
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}我們的叢集現在是下圖所示情況,所有3個主分片都被分配在 Node 1 。

此時檢查叢集的健康狀況GET /_cluster/health,我們會發現:
{
"cluster_name": "elasticsearch",
"status": "yellow", # 1
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3, # 2
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}#1 叢集的狀態值是 yellow
#2 未分配的副本數是 3
叢集的健康狀況為 yellow 則表示全部 主 分片都正常執行(叢集可以正常服務所有請求),但是 副本 分片沒有全部處在正常狀態。 實際上,所有3個副本分片都是 unassigned —— 它們都沒有被分配到任何節點。 在同一個節點上既儲存原始資料又儲存副本是沒有意義的,因為一旦失去了那個節點,我們也將丟失該節點上的所有副本資料。
主分片和對應的副本分片是不會在同一個節點上的。所以副本分片數的最大值是 n -1(其中n 為節點數)。
雖然當前我們的叢集是正常執行的,但是在硬體故障時有丟失資料的風險。
水平擴容
既然單點是有問題的,那我們只需再啟動幾個節點並加入到當前叢集中,這樣就可以提高可用性並實現故障轉移,這種方式即 水平擴容。
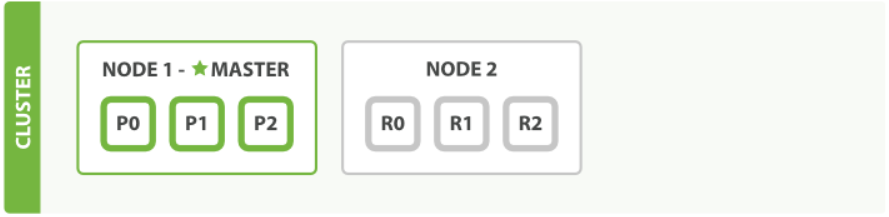
還以上面的 user 為例,我們新增一個節點後,新的叢集如上圖所示。
當第二個節點加入到集群后,3個 副本分片 將會分配到這個節點上——每個主分片對應一個副本分片。 這意味著當叢集內任何一個節點出現問題時,我們的資料都完好無損。
所有新近被索引的文件都將會儲存在主分片上,然後被並行的複製到對應的副本分片上。這就保證了我們既可以從主分片又可以從副本分片上獲得文件。
cluster-health現在展示的狀態為 green ,這表示所有6個分片(包括3個主分片和3個副本分片)都在正常執行。我們的叢集現在不僅僅是正常執行的,並且還處於 始終可用 的狀態。
動態擴容
產品不斷升級,業務不斷增長,使用者數也會不斷新增,也許我們之前設計的索引容量(3個主分片和3個副本分片)已經不夠使用了,使用者資料的不斷增加,每個主分片和副本分片的資料不斷累積,達到一定程度之後也會降低搜尋效能。那麼怎樣為我們的正在增長中的應用程式按需擴容呢?
我們將之前的兩個節點繼續水平擴容,再增加一個節點,此時叢集狀態如下圖所示:

為了分散負載,ES 會對分片進行重新分配。Node 1 和 Node 2 上各有一個分片被遷移到了新的 Node 3 節點,現在每個節點上都擁有2個分片,而不是之前的3個。 這表示每個節點的硬體資源(CPU, RAM, I/O)將被更少的分片所共享,每個分片的效能將會得到提升。
分片是一個功能完整的搜尋引擎,它擁有使用一個節點上的所有資源的能力。 我們這個擁有6個分片(3個主分片和3個副本分片)的索引可以最大擴容到6個節點,每個節點上存在一個分片,並且每個分片擁有所在節點的全部資源。
但是如果我們想要擴容超過6個節點怎麼辦呢?
主分片的數目在索引建立時 就已經確定了下來。實際上,這個數目定義了這個索引能夠 儲存 的最大資料量。(實際大小取決於你的資料、硬體和使用場景。) 但是,讀操作——搜尋和返回資料——可以同時被主分片 或 副本分片所處理,所以當你擁有越多的副本分片時,也將擁有越高的吞吐量。
索引的主分片數這個值在索引建立後就不能修改了(預設值是 5),但是每個主分片的副本數(預設值是 1 )對於活動的索引庫,這個值可以隨時修改的。至於索引的主分片數為什麼在索引建立之後就不能修改了,我們在下面的文件儲存原理章節中說明。
既然在執行中的叢集上是可以動態調整副本分片數目的 ,那麼我們可以按需伸縮叢集。讓我們把副本數從預設的 1 增加到 2 :
PUT /user/_settings
{
"number_of_replicas" : 2
}如下圖 所示, user 索引現在擁有9個分片:3個主分片和6個副本分片。 這意味著我們可以將叢集擴容到9個節點,每個節點上一個分片。相比原來3個節點時,叢集搜尋效能可以提升 3 倍。
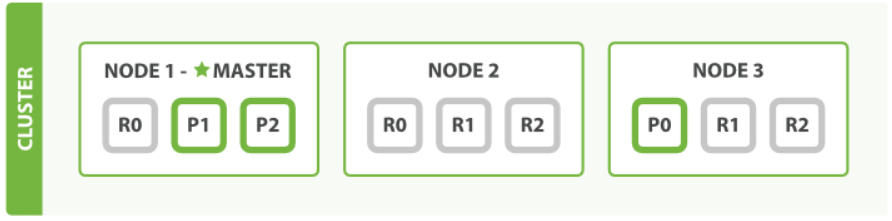
當然,如果只是在相同節點數目的叢集上增加更多的副本分片並不能提高效能,因為每個分片從節點上獲得的資源會變少。 你需要增加更多的硬體資源來提升吞吐量。
但是更多的副本分片數提高了資料冗餘量:按照上面的節點配置,我們可以在失去2個節點的情況下不丟失任何資料。
節點故障
如果我們某一個節點發生故障,節點伺服器宕機或網路不可用,這裡假設主節點1發生故障,這時叢集的狀態為:

此時我們檢查一下叢集的健康狀況,可以發現狀態為 red,表示不是所有主分片都在正常工作。
我們關閉的節點是一個主節點。而叢集必須擁有一個主節點來保證正常工作,所以發生的第一件事情就是選舉一個新的主節點: Node 2 。
在我們關閉 Node 1 的同時也失去了主分片 1 和 2 ,並且在缺失主分片的時候索引也不能正常工作。
幸運的是,在其它節點上存在著這兩個主分片的完整副本, 所以新的主節點立即將這些分片在 Node 2 和 Node 3 上對應的副本分片提升為主分片, 此時叢集的狀態將會為 yellow。 這個提升主分片的過程是瞬間發生的,如同按下一個開關一般。
為什麼我們叢集狀態是 yellow 而不是 green 呢? 雖然我們擁有所有的三個主分片,但是同時設定了每個主分片需要對應2份副本分片,而此時只存在一份副本分片。 所以叢集不能為 green 的狀態,不過我們不必過於擔心:如果我們同樣關閉了 Node 2 ,我們的程式 依然 可以保持在不丟任何資料的情況下執行,因為 Node 3 為每一個分片都保留著一份副本。
如果我們重新啟動 Node 1 ,叢集可以將缺失的副本分片再次進行分配,那麼叢集的狀態又將恢復到原來的正常狀態。 如果 Node 1 依然擁有著之前的分片,它將嘗試去重用它們,同時僅從主分片複製發生了修改的資料檔案。
處理併發衝突
分散式系統中最麻煩的就是併發衝突,既然 ES 也是分散式的那它是如何處理併發衝突的呢?
通常當我們使用 索引 API 更新文件時 ,可以一次性讀取原始文件,做我們的修改,然後重新索引 整個文件 。 最近的索引請求將獲勝:無論最後哪一個文件被索引,都將被唯一儲存在 Elasticsearch 中。如果其他人同時更改這個文件,他們的更改將丟失。
很多時候這是沒有問題的。也許我們的主資料儲存是一個關係型資料庫,我們只是將資料複製到 Elasticsearch 中並使其可被搜尋。也許兩個人同時更改相同的文件的機率很小。或者對於我們的業務來說偶爾丟失更改並不是很嚴重的問題。
但有時丟失了一個變更就是非常嚴重的 。試想我們使用 Elasticsearch 儲存我們網上商城商品庫存的數量, 每次我們賣一個商品的時候,我們在 Elasticsearch 中將庫存數量減少。
有一天,管理層決定做一次促銷。突然地,我們一秒要賣好幾個商品。 假設有兩個 web 程式並行執行,每一個都同時處理所有商品的銷售,那麼會造成庫存結果不一致的情況。
變更越頻繁,讀資料和更新資料的間隙越長,也就越可能丟失變更。
樂觀併發控制 - 版本號
在資料庫領域中,有兩種方法通常被用來確保併發更新時變更不會丟失:
悲觀鎖
這種方法被關係型資料庫廣泛使用,它假定有變更衝突可能發生,因此阻塞訪問資源以防止衝突。 一個典型的例子是讀取一行資料之前先將其鎖住,確保只有放置鎖的執行緒能夠對這行資料進行修改。樂觀鎖
Elasticsearch 中使用的這種方法假定衝突是不可能發生的,並且不會阻塞正在嘗試的操作。然而,如果源資料在讀寫當中被修改,更新將會失敗。應用程式接下來將決定該如何解決衝突。例如,可以重試更新、使用新的資料、或者將相關情況報告給使用者。
Elasticsearch 中對文件的 index , GET 和 delete 請求時,我們指出每個文件都有一個 _version (版本)號,當文件被修改時版本號遞增。
Elasticsearch 使用這個 _version 號來確保變更以正確順序得到執行。如果舊版本的文件在新版本之後到達,它可以被簡單的忽略。
我們可以利用 _version 號來確保應用中相互衝突的變更不會導致資料丟失。我們通過指定想要修改文件的 version 號來達到這個目的。 如果該版本不是當前版本號,我們的請求將會失敗。
所有文件的更新或刪除 API,都可以接受 version 引數,這允許你在程式碼中使用樂觀的併發控制,這是一種明智的做法。
樂觀併發控制 - 外部系統
版本號(version)只是其中一個實現方式,我們還可以藉助外部系統使用版本控制,一個常見的設定是使用其它資料庫作為主要的資料儲存,使用 Elasticsearch 做資料檢索, 這意味著主資料庫的所有更改發生時都需要被複制到 Elasticsearch ,如果多個程序負責這一資料同步,你可能遇到類似於之前描述的併發問題。
如果你的主資料庫已經有了版本號,或一個能作為版本號的欄位值比如 timestamp,那麼你就可以在 Elasticsearch 中通過增加 version_type=external到查詢字串的方式重用這些相同的版本號,版本號必須是大於零的整數, 且小於 9.2E+18(一個 Java 中 long 型別的正值)。
外部版本號的處理方式和我們之前討論的內部版本號的處理方式有些不同, Elasticsearch 不是檢查當前 _version 和請求中指定的版本號是否相同,而是檢查當前_version 是否小於指定的版本號。如果請求成功,外部的版本號作為文件的新_version 進行儲存。
外部版本號不僅在索引和刪除請求是可以指定,而且在建立新文件時也可以指定。
例如,要建立一個新的具有外部版本號 5 的部落格文章,我們可以按以下方法進行:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}在響應中,我們能看到當前的 _version 版本號是 5 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}現在我們更新這個文件,指定一個新的 version 號是 10 :
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}請求成功並將當前 _version 設為 10 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}如果你要重新執行此請求時,它將會失敗,並返回像我們之前看到的同樣的衝突錯誤,因為指定的外部版本號不大於 Elasticsearch 的當前版本號。
文件儲存原理
建立索引的時候我們只需要指定分片數和副本數,ES 就會自動將文件資料分發到對應的分片和副本中。那麼檔案究竟是如何分佈到叢集的,又是如何從叢集中獲取的呢? Elasticsearch 雖然隱藏這些底層細節,讓我們好專注在業務開發中,但是我們深入探索這些核心的技術細節,這能幫助你更好地理解資料如何被儲存到這個分散式系統中。
文件是如何路由到分片中的
當索引一個文件的時候,文件會被儲存到一個主分片中。 Elasticsearch 如何知道一個文件應該存放到哪個分片中呢?當我們建立文件時,它如何決定這個文件應當被儲存在分片 1 還是分片 2 中呢?
首先這肯定不會是隨機的,否則將來要獲取文件的時候我們就不知道從何處尋找了。實際上,這個過程是根據下面這個公式決定的:
shard = hash(routing) % number_of_primary_shardsrouting 是一個可變值,預設是文件的 _id ,也可以設定成一個自定義的值。 routing 通過 hash 函式生成一個數字,然後這個數字再除以 number_of_primary_shards (主分片的數量)後得到 餘數 。這個分佈在 0 到 number_of_primary_shards-1 之間的餘數,就是我們所尋求的文件所在分片的位置。
這就解釋了為什麼我們要在建立索引的時候就確定好主分片的數量 並且永遠不會改變這個數量:因為如果數量變化了,那麼所有之前路由的值都會無效,文件也再也找不到了。
你可能覺得由於 Elasticsearch 主分片數量是固定的會使索引難以進行擴容,所以在建立索引的時候合理的預分配分片數是很重要的。
所有的文件 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一個叫做 routing 的路由引數 ,通過這個引數我們可以自定義文件到分片的對映。一個自定義的路由引數可以用來確保所有相關的文件——例如所有屬於同一個使用者的文件——都被儲存到同一個分片中。更多路由相關的內容可以訪問這裡。
主分片和副本分片如何互動
上面介紹了一個文件是如何路由到一個分片中的,那麼主分片是如何和副本分片互動的呢?
假設有個叢集由三個節點組成, 它包含一個叫 user 的索引,有兩個主分片,每個主分片有兩個副本分片。相同分片的副本不會放在同一節點,所以我們的叢集看起來如下圖所示:

我們可以傳送請求到叢集中的任一節點。每個節點都有能力處理任意請求。每個節點都知道叢集中任一文件位置,所以可以直接將請求轉發到需要的節點上。 在下面的例子中,將所有的請求傳送到 Node 1 ,我們將其稱為 協調節點(coordinating node)。
當傳送請求的時候,為了擴充套件負載,更好的做法是輪詢叢集中所有的節點。
對文件的新建、索引和刪除請求都是寫操作,必須在主分片上面完成之後才能被複制到相關的副本分片。
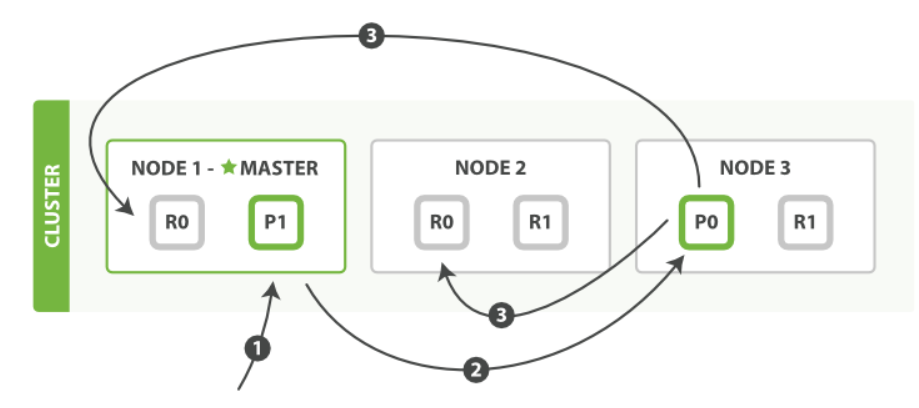
以下是在主副分片和任何副本分片上面 成功新建,索引和刪除文件所需要的步驟順序:
- 客戶端向 Node 1 傳送新建、索引或者刪除請求。
- 節點使用文件的 _id 確定文件屬於分片 0 。請求會被轉發到 Node 3,因為分片 0 的主分片目前被分配在 Node 3 上。
- Node 3 在主分片上面執行請求。如果成功了,它將請求並行轉發到 Node1 和 Node2 的副本分片上。一旦所有的副本分片都報告成功,Node 3 將向協調節點報告成功,協調節點向客戶端報告成功。
在客戶端收到成功響應時,文件變更已經在主分片和所有副本分片執行完成,變更是安全的。
在處理讀取請求時,協調結點在每次請求的時候都會通過輪詢所有的副本分片來達到負載均衡。
在文件被檢索時,已經被索引的文件可能已經存在於主分片上但是還沒有複製到副本分片。在這種情況下,副本分片可能會報告文件不存在,但是主分片可能成功返回文件。一旦索引請求成功返回給使用者,文件在主分片和副本分片都是可用的。