用C++實現檔案壓縮
乍一聽,這個檔案壓縮的名字貌似是很高大上的,其實,在資料結構中學完Huffman樹之後,就可以理解這個東西其實不是那麼的高不可攀。
檔案壓縮
所謂檔案壓縮,其實就是將對應的字元編碼轉換為另一種佔據位元組數較少的編碼來進行儲存。
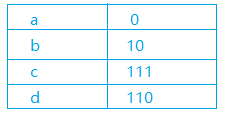
舉個栗子:有一串文字:aaaabbbccd,其中單獨將這串字元存放在檔案中,它所佔據的將會是至少10個位元組(為什麼說是至少,因為還有一些必要的檔案資訊要儲存的說)。由此就有人嘗試著要以重新編碼,然後再儲存的方式來節約我們寶貴的磁碟空間以及傳輸時間。還是這個字串,其中a出現了4次,b出現3次,c出現2次,d只出現了一次。由此我們可以重新編碼:
什麼意思呢?我們按表這個來編碼,a對應0,b對應10,依此類推,可以將原字串轉換為00001010 10111111 110,用二進位制位來代替原有的字元,這樣將出現次數較多的字元替換為較短的編碼,便實現了對字串的壓縮。字串中字元的出現次數可以遍歷一遍統計出來,那麼現在的問題就是如何得到這樣的編碼了!
Huffman樹
Huffman的定義:假設給定一個有n個權值的集合{w1,w2,w3,…,wn},其中wi>0(1<=i<=n)。若T是一棵有n個 葉結點的二叉樹,而且將權值w1,w2,w3…wn分別賦值給T的n個葉結點,則稱T是權值為 w1,w2,w3…wn的擴充二叉樹。帶有權值的葉節點叫著擴充二叉樹的外結點,其餘不帶權值 的分支結點叫做內結點。外結點的帶權路徑長度為T的根節點到該結點的路徑長度與該結點上的權值的乘積。
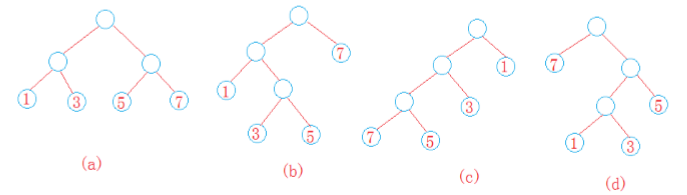
說的有些偏理論,看個圖:
如上,所有的葉子節點處有所謂的權值,從根結點到某一葉子節點的分支個數為對應的路徑長度,如(a)中的權重為1的結點,它的路徑長度為2,路徑和權值的乘積為2,這顆樹的帶權路徑長度為 1*2 + 3*2 + 5*2 + 7*2 = 32;(b)(c)就不計算了,(d)為7*1 + 1*3 + 3*3 + 5*2 = 29.像(d)這樣的帶權路徑長度最短的樹就叫做Huffman樹,也叫做最優二叉樹。
Huffman樹的建立
- 、由給定的n個權值{w1,w2,w3,…,wn}構造n棵只有根節點的擴充二叉樹森林F= {T1,T2,T3,…,Tn},其中每棵擴充二叉樹Ti只有一個帶權值wi的根節點,左右孩子均為 空。
- 、重複以下步驟,直到F中只剩下一棵樹為止:
a、在F中選取兩棵根節點的權值最小的擴充二叉樹,作為左右子樹構造一棵新的二叉樹。將新二叉樹的根節點的權值為其左 右子樹上根節點的權值之和。
b、在F中刪除這兩棵二叉樹;
c、把新的二叉樹加入到F中;
最後得到的就是Huffman樹。
Huffman編碼
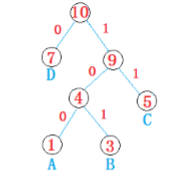
再建立好的Huffman樹的分支上標記,左分支標記0,右分支標記1,這樣,有根結點到某個葉子節點路徑上的01序列即為要求得Huffman編碼。如圖:
7的編碼為0, 1的編碼為100,3的編碼為101, 5的編碼為11. (Huffman樹不是唯一的,編碼也不是唯一的)
由這種方法得到的編碼是字首編碼:任何一個字元的編碼不是另一個字元編碼的字首。 這樣才能保證譯碼的唯一性。
理清了所有思路,實現起來就不難了!
實現
大概的說一下是怎麼實現的:
壓縮:
- 遍歷一次檔案,統計對應字元出現次數
- 建立Huffman樹
- 得到Huffman編碼
- 將解壓縮必要資訊儲存到目標檔案首部(我的實現:原副檔名,後續字元行數,字元與對應次數,資料部分)(以‘\n’分隔)
- 按編碼將對應字元轉換(位運算)
- 儲存
解壓:
- 取出檔案頭部資訊
- 設定字元與對應出現次數
- 以同種演算法建立Huffman樹
- 解碼(編碼對應的原字元可由從根結點開始,0走左,1走右,直到遇到葉子節點,則為對應字元)
- 儲存
效果
嘗試著將其中的某個原始檔進行壓縮,原大小8位元組,壓縮後變為6位元組,節省了2位元組的儲存空間。(ps:gl是我瞎編的副檔名)
具體能縮減多少空間就還要看具體字元出現的頻率了。解壓後所有字元均與原檔案相同。當然也可以壓圖片:
壓縮前(左)與壓縮後(再解壓後)(右)對比:

a: 看起來沒什麼不同嘛!=_=||
b: 沒什麼不同才叫解壓哈! =_=||
遇到的問題
1.問題:個別字元處理解析錯誤。原因分析:GetLine函式沒有考慮到‘\n’的特殊性,混淆可分隔用的‘\n’與行結束標誌‘\n’。解決方法:重新考慮遇到‘\n’的特殊情況,修正GetLine函式。
2.問題:解壓後文件不全,體現為無後半部分。原因分析:從檔案中讀取字元時,遇到了假的EOF標誌(某字元為有意義的字元,卻和EOF有著相同的位)。解決方法:檔案操作時均採用二進位制方式讀寫。
3.問題:解壓後的檔案每個1024個字元就出現亂碼。原因分析:檔案解壓縮時每次讀取1024個位元組到ReadBuf裡,然後對讀進來的每個位元組(放在char變數裡)進行位操作,用pos標誌來標記當前處理到的位,解碼後的字元放在WriteBuf裡。但是ReadBuf中一輪資料處理完成後讀取後1024個位元組,這時重新清零了pos標誌,導致當前char變數中剩餘的位沒有處理。解決方法:將pos的位置移到讀操作迴圈的外部。(ps:就這個小bug著實耗費了我很長時間=_=||)
其它的都是一些小問題,就不一一羅列了。
GitHub連結
最後,本著資源共享,共同學習的精神,放上專案的開源連結(原始碼有詳細註釋):