
核心資源之Pod_Kubernetes中文社群
1、Pod概述
在Kubernetes叢集中,Pod是所有業務型別的基礎,它是一個或多個容器的組合。這些容器共享儲存、網路和名稱空間,以及如何執行的規範。在Pod中,所有容器都被同一安排和排程,並執行在共享的上下文中。對於具體應用而言,Pod是它們的邏輯主機,Pod包含業務相關的多個應用容器。Kubernetes不只是支援Docker容器,它也支援其他容器。Pod 的上下文可以理解成多個linux名稱空間的聯合:
- PID 名稱空間(同一個Pod中應用可以看到其它程序)
- 網路 名稱空間(同一個Pod的中的應用對相同的IP地址和埠有許可權)
- IPC 名稱空間(同一個Pod中的應用可以通過VPC或者POSIX進行通訊)
- UTS 名稱空間(同一個Pod中的應用共享一個主機名稱)
一個Pod的共享上下文是Linux名稱空間、cgroups和其它潛在隔離內容的集合。 在Pod中,容器共享一個IP地址和埠空間,它們可以通過localhost發現彼此。在同一個Pod中的容器,可以使用System V 或POSIX訊號進行標準的程序間通訊和共享記憶體。在不同Pod中的容器,擁有不同的IP地址,因此不能夠直接在程序間進行通訊。容器間通常使用Pod IP地址進行通訊。在一個Pod中的應用於口訪問共享的儲存卷,它被定為為Pod的一部分,可以被掛接至每一個應用檔案系統。與獨立的應用容器一樣,Pod是一個臨時的實體,它有著自己的生命週期。在Pod被建立時,會被指派一個唯一的ID,並被排程到Node中,直到Pod被終止或刪除。如果Pod所在的Node宕機,給定的Pod(即通過UID定義)不會被重新排程。相反,它將被完全相同的Pod所替代。這所說的具有和Pod相關生命週期的情況,例如儲存卷,是說和Pod存在的時間一樣長。如果Pod被刪除,即使完全相同的副本被建立,則相關儲存卷等也會被刪除,並會Pod建立一個新的儲存卷等。Pod本身就沒有打算作為持久化的實體,在排程失敗、Node失敗和獲取其它退出(缺少資源或者Node在維護)情況下,Pod都會被刪除。一般來說,使用者不應該直接建立Pod,即是建立單個的Pod也應該通過控制器建立。在叢集範圍內,控制器為Pod提供自愈能力,以及副本和部署管理。
一個多容器的Pod會包含一個檔案拉取器和一個web伺服器,此web伺服器使用一個持久化儲存捲來在容器中共享儲存。
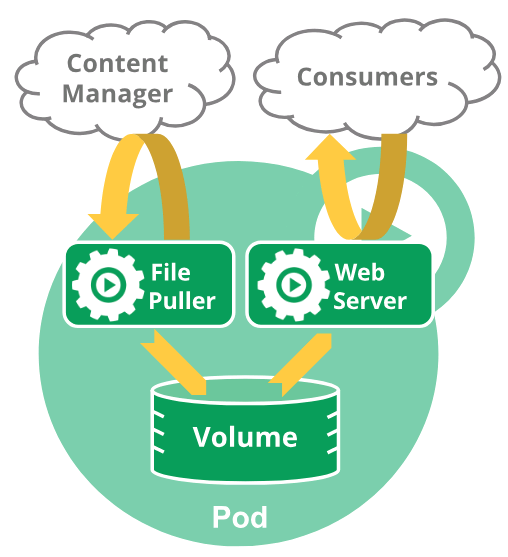
網路:每一個Pod都會被指派一個唯一的Ip地址,在Pod中的每一個容器共享網路名稱空間,包括Ip地址和網路埠。在同一個Pod中的容器可以同locahost進行互相通訊。當Pod中的容器需要與Pod外的實體進行通訊時,則需要通過埠等共享的網路資源。
儲存:Pod能夠被指定共享儲存卷的集合,在Pod中所有的容器能夠訪問共享儲存卷,允許這些容器共享資料。儲存卷也允許在一個Pod持久化資料,以防止其中的容器需要被重啟。
2、Pod的工作方式
在Kubernetes中一般不會直接建立一個獨立的Pod,這是因為Pod是臨時存在的一個實體。當直接建立一個獨立的Pod時,如果缺少資源或者所被排程到的Node失敗,則Pod會直接被刪除。這裡需要注意的是,重起Pod和重起Pod中的容器不是一個概念,Pod自身不會執行,它只是容器所執行的一個環境。Pod本身沒有自愈能力,如果Pod所在的Node失敗,或者如果排程操作本身失敗,則Pod將會被刪除;同樣的,如果缺少資源,Pod也會失敗。Kubernetes使用高層次的抽象,即控制器來管理臨時的Pod。通過控制器能夠建立和管理多個Pod,並在叢集範圍內處理副本、部署和提供自愈能力。例如,如果一個Node失敗,控制器可以自動的在另外一個節點上部署一個完全一樣的副本。控制器是Pod模板來建立Pod,Pod的控制器包括:
Pod模板是一個被包含在其它物件(例如:Deployment、StatefuleSet、DaemonSet等)中的Pod規格。控制使用Pod模板建立實際的Pod,下面是Pod模板的一個示例:

2.1 重啟策略
在Pod中的容器可能會由於異常等原因導致其終止退出,Kubernetes提供了重啟策略以重啟容器。重啟策略對同一個Pod的所有容器起作用,容器的重啟由Node上的kubelet執行。Pod支援三種重啟策略,在配置檔案中通過restartPolicy欄位設定重啟策略:
- Always:只要退出就會重啟。
- OnFailure:只有在失敗退出(exit code不等於0)時,才會重啟。
- Never:只要退出,就不再重啟
注意,這裡的重啟是指在Pod的宿主Node上進行本地重啟,而不是排程到其它Node上。
2.2 映象拉取策略
在Kubernetes中,容器的執行是基於容器映象的。Pod支援三種映象拉取策略,在配置檔案中通過imagePullPolicy字型設定映象的拉取策略:
- Always:不管本地是否存在映象都會進行一次拉取。
- Never:不管本地是否存在映象都不會進行拉取。
- IfNotPresent:僅在本地映象不存在時,才會進行映象拉取。
注意:
- 映象拉取策略的預設值為IfNotPresent,但:latest標籤的映象預設為Always。
- 拉取映象時docker會進行校驗,如果映象中的MD5碼沒有變,則不會拉取映象資料。
- 生產環境中應該儘量避免使用:latest標籤,而開發環境中可以藉助:latest標籤自動拉取最新的映象。
2.3 使用私鑰映象倉庫
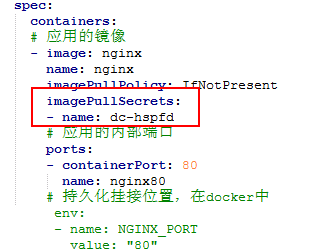
在Kubernetes中執行容器時,需要為容器獲取映象。Pod中容器的映象有三個來源,即Docker公共映象倉庫、私有映象倉庫和本地映象。當在內網使用的Kubernetes場景下,就需要搭建和使用私有映象倉庫。在使用私有映象拉取映象時,需要為私有映象倉庫建立一個docker registry secret,並在建立容器中進行引用。
通過kubectl create secret docker-registry命令建立docker registry secret:
$ kubectl create secret docker-registry regsecret --docker-server=<your-registry-server> \ --docker-username=<your-name> --docker-password=<your-pword> --docker-email=<your-email>
在容器中通過imagePullSecrets欄位指定該secret:
2.4 資源限制
Kubernetes通過cgroups來限制容器的CPU和記憶體等計算資源,在建立Pod時,可以為Pod中的每個容器設定資源請求(request)和資源限制(limit),資源請求是容器需要的最小資源要求,資源限制為容器所能使用的資源上限。CPU的單位是核(core),記憶體(Memory)的單位是位元組(byte)。在Pod中,容器的資源限制通過resources.limits進行設定:
- spec.containers[].resources.limits.cpu:容器的CPU資源上限,可以短暫超過,容器也不會被停止;
- spec.containers[].resources.limits.memory:容器的記憶體資源上限,不可以超過;如果超過,容器可能會被停止或排程到其它資源充足的Node上。
資源請求通過resources.requests進行設定,
- spec.containers[].resources.requests.cpu:容器的CPU資源請求,可以超過;
- spec.containers[].resources.requests.memory:容器的記憶體資源請求,可以超過;但如果超過,容器可能會在Node記憶體不足時清理。
Kubernetes在進行Pod排程時,Pod的資源請求是最重要的一個指標。Kubernetes Schedule會檢查Node是否存在足夠的資源,判斷是否能夠滿足Pod的資源請求,從而決定是否可以執行Pod。
2.5 健康檢查
在Pod部署到Kubernetes叢集中以後,為了確保Pod處於健康正常的執行狀態,Kubernetes提供了兩種探針,用於檢測容器的狀態:
- Liveness Probe :檢查容器是否處於執行狀態。如果檢測失敗,kubelet將會殺掉掉容器,並根據重啟策略進行下一步的操作。如果容器沒有提供Liveness Probe,則預設狀態為Success;
- ReadinessProbe :檢查容器是否已經處於可接受服務請求的狀態。如果Readiness Probe失敗,端點控制器將會從服務端點(與Pod匹配的)中移除容器的IP地址。Readiness的預設值為Failure,如果一個容器未提供Readiness,則預設是Success。
kubelet在容器上週期性的執行探針以檢測容器的健康狀態,kubelet通過呼叫被容器實現的處理器來實現檢測,在Kubernetes中有三類處理器:
- ExecAction :在容器中執行一個指定的命令。如果命令的退出狀態為0,則判斷認為是成功的;
- TCPSocketAction :在容器IP地址的特定埠上執行一個TCP檢查,如果埠處於開啟狀態,則視為成功;
- HTTPGetAcction :在容器IP地址的特定埠和路徑上執行一個HTTP Get請求使用container的IP地址和指定的埠以及請求的路徑作為url,使用者可以通過host引數設定請求的地址,通過scheme引數設定協議型別(HTTP、HTTPS)如果其響應程式碼在200~400之間,設為成功。
健康檢測的結果為下面三種情況:
- Success :表示容器通過檢測
- Failure :表示容器沒有通過檢測
- Unknown :表示容器容器失敗
2.6 初始化容器
在一個POD中,可以執行多個容器,同時它也可以擁有有一個或多個初始化容器,初始化容器在應用程式容器啟動之前執行。初始化容器與普通容器完全一樣,只是:
- 它們總是完全執行
- 每一個初始化容器都必須在下一個初始化開始之前成功完成
如果Pod中的初始化容器失敗,Kubernetes將會重複重啟Pod,直到初始化容器成功執行。然而,如果Pod的重啟策略為Never,則Pod不會重啟。初始化容器支援應用程式容器的所有欄位和特性,包括資源限制、儲存卷和安全設定等。初始化容器不支援健康檢測探針,因為,它們必須在POD準備好之前完成執行。如果為Pod指定了多個初始化容器,則這些初始化容器將會按順序依次執行。每一個都必須在下一個執行之前成功執行。當所有的初始化容器都執行完成時,Kubernetes完成Pod的初始化,並像通常的方式一樣執行應用程式容器。
2.7 容器排程
Kubernetes Scheduler負責根據排程策略自動將Pod部署到合適Node中,排程策略分為預選策略和優選策略,Pod的整個排程過程分為兩步:
1)預選Node:遍歷叢集中所有的Node,按照具體的預選策略篩選出符合要求的Node列表。如沒有Node符合預選策略規則,該Pod就會被掛起,直到叢集中出現符合要求的Node。
2)優選Node:預選Node列表的基礎上,按照優選策略為待選的Node進行打分和排序,從中獲取最優Node。
2.7.1 預選策略
隨著版本的發展,Kunbernetes提供了大量的預選策略,通過預選策略能夠篩選出符合條件的Node列表。預選策略是強制性規則,用來檢測Node是否匹配Pod所需要的資源。如果沒有任何Node能夠滿足預選策略, 該Pod就會被掛起,直到出現能夠能夠滿足要求的Node。
| Position | 預選策略 | 策略說明 |
| 1 | CheckNodeConditionPredicate | 檢查是否可以將Pod排程到磁碟不足、網路不可用和未準備就緒的Node。 |
| 2 | PodFitsHost | 檢查叢集Node中是否存在與Pod配置檔案中指定的Node名稱相匹配。 |
| 3 | PodFitsHostPorts | 檢查Node是否存在空閒可用的埠。 |
| 4 | PodMatchNodeSelector | 檢查Pod上的Node選擇器是否匹配Node的標籤。 |
| 5 | PodFitsResources | 檢查Node上的cpu、記憶體、gpu等資源是否滿足Pod的需求,來決定是否排程Pod到Node上。 |
| 6 | NoDiskConflict | 根據Pod請求的儲存捲進行評估,如果在這個Node已經掛載了儲存卷,則其它同樣請求這個儲存卷的Pod將不能排程到這個Nods上。 |
| 7 | PodToleratesNodeTaints | 檢查pod的能否容忍Node上的汙點。 |
| 8 | PodToleratesNodeNoExecuteTaints | 檢查Pod是否能容忍Node上未執行的汙染。 |
| 9 | CheckNodeLabelPresence | 檢查所有指定的標籤是否存在於Node上,而不考慮它們的值。 |
| 10 | checkServiceAffinity | 檢查服務的親和性,確定是否在Node部署Pod。 |
| 11 | MaxPDVolumeCountPredicate | 檢查Pod所需要的儲存卷的數量,確定在哪個Node上部署Pod。 |
| 12 | VolumeZonePredicate | 根據volumes需求來評估Node是否滿足條件。 |
| 13 | CheckNodeMemoryPressurePredicate | 檢查Node記憶體的壓力情況 |
| 14 | CheckNodeDiskPressurePredicate | 根據Node磁碟的壓力情況,確定是否排程Pod到Node上。 |
| 15 | InterPodAffinityMatches | 根據Pod的親和和反親和的配置,檢查是否能夠將Pod排程到指定的Node上。 |
2.7.2 優選策略
通過預選策略對Node過濾後,獲得預選的Node列表。在預選Node列表的基礎上,對這些預選的Node進行打分,從而為Pod選擇一個分值最高的Node。Kubernetes通過一系列的優選策略對預選Node進行打分。每一個優選函式都會為Node給出一個0-10的分數,分數越高表示節點越優;同時,每個優選函式也會有一個對應的權重值。那個Node的最終得分是每個優選函式給出的得分的加權分數之和,因此每個Node的最終主機的得分如以下公式計算:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + … + (weightn * priorityFuncn)
| 序號 | 優選策略 | 優選說明 |
| 1 | BalancedResourceAllocation | 根據Node上各項資源(CPU、記憶體)使用率均衡情況進行打分。 |
| 2 | ImageLocalityPriority | 基於Pod所需映象的總體大小,根據Node上存在Pod所需映象的大小從0到10進行打分。 |
| 3 | InterPodAffinityPriority | 基於Pod親和情況打分。 |
| 4 | LeastRequestedPriority | 計算Pod需要的CPU和記憶體資源與在Node可用資源的百分比,具有最小百分比的節點就是最優。 |
| 5 | PriorityMetadata | 根據元素進行打分。 |
| 6 | MostRequestedPriority | 根據Node上所提供的資源進行打分。 |
| 7 | NodeAffinityPriority | 根據親和情況進行打分。 |
| 8 | NodeLabelPriority | 根據Node上是否存在特殊的標籤進行打分。 |
| 9 | NodePreferAvoidPodsPriority | 根據Node上的註釋進行打分。 |
| 10 | ResourceAllocationPriority | 根據在Node上的分配的資源進行打分。 |
| 11 | ResourceLimitsPriority | 根據Pod的資源限制進行打分。 |
| 12 | SelectorSpreadPriority | 按service,RC,RS or StatefulSet歸屬
計算Node上分佈最少的同類Pod數量,得分計算,數量越少得分越高。 |
| 13 | TaintTolerationPriority | 基於Node上不可容忍的汙點數進行打分。 |
2.7.3 將Pod分配給Node
您可以約束一個POD,以便只能在特定節點上執行,或者更喜歡在特定節點上執行。有幾種方法可以做到這一點,它們都使用標籤選擇器來進行選擇。一般來說,這樣的約束是不必要的,因為排程器將自動地進行合理的放置(例如,將您的莢散佈在節點上,而不是將POD放置在自由資源不足的節點上),但是在某些情況下,您可能希望在POD L的節點上進行更多的控制。ODS,例如,確保POD在帶有SSD的機器上結束,或者將兩個不同服務的POD定位到相同的可用性區域中。
2.7.3.1 nodeSelector
nodeSelector是最簡單一種約束形式,nodeSelector是PodSpec的一個欄位。為了使Pod能夠在Node上執行,Node必須具有所指示的鍵值對作為標籤(它也可以有附加的標籤)。nodeSeletor的用法如下:
1)為Node打上標籤
$ kubectl label nodes <node-name> <label-key>=<label-value>
2)在Pod配置檔案中新增nodeSelector欄位
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disktype: ssd
3)建立Pod,並將Pod排程到Node上
通過執行如下命令,在叢集中將會建立Pod,並在後臺會將其排程到打上了鍵值對的Node上。
$ kubectl create -f nginx.yaml
通過下面的命令,可以檢視Pod排程的情況
$ kubectl get pods -o wide
2.7.3.2 nodeName
1)在Pod的配置檔案中新增nodeName欄位
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeName: <NodeName>
2)建立Pod,並將Pod排程到Node上
通過執行如下命令,在叢集中將會建立Pod,並在後臺會將其排程到所指定的Node上。
$ kubectl create -f nginx.yaml
通過下面的命令,可以檢視Pod排程的情況
$ kubectl get pods -o wide
2.8 環境變數
在建立Pod時,可以為在Pod中執行的容器設定環境變數。在Kubernetes中,通過env或envFrom欄位進行設定。使用env或envFrom欄位設定的環境變數將會覆蓋容器映象中指定的環境變數。在下面的YAML檔案中,設定了名稱為DEMO_GREETING和DEMO_FAREWELL的兩個環境變數。
apiVersion: v1
kind: Pod
metadata:
name: envar-demo
labels: purpose: demonstrate-envars
spec:
containers:
- name: envar-demo-container
image: gcr.io/google-samples/node-hello:1.0
env:
- name: DEMO_GREETING
value: "Hello from the environment"
- name: DEMO_FAREWELL
value: "Such a sweet sorrow"
2.9 啟動命令
在建立Pod時,也能夠為Pod中的容器定義命令和引數。在配置檔案通過設定command欄位來定義命令,通過設定args欄位來定義引數。在Pod被建立後,定義的命令和引數將不能被修改。在配置檔案中定義的命令和引數會覆蓋在容器映象中定義的命令和引數。下面的YAML配置檔案中,設定了printenv命令,以及設定了HOSTNAME和KUBERNETES_PORT兩個引數。
apiVersion: v1
kind: Pod
metadata:
name: command-demo
labels:
purpose: demonstrate-command
spec:
containers:
- name: command-demo-container
image: debian
command: ["printenv"]
args: ["HOSTNAME", "KUBERNETES_PORT"]
restartPolicy: OnFailure
1)通過上述YAML配置檔案參加Pod:
2)以列表的形式展示正在執行的Pod:
$ kubectl get pods
3)可以通過Pod的日誌資訊,參看命令的輸出結果:
$ kubectl logs command-demo
輸出結果顯示了HOSTNAME和KUBERNETES_PORT環境變數的值:
command-demo tcp://10.3.240.1:443
在前面的例子中,通過提供字串直接定義了引數,在引數中也可以使用環境變數來定義引數:
env: - name: MESSAGE value: "hello world" command: ["/bin/echo"]args: ["$(MESSAGE)"]
這意味可以使用所有任意的技術變數(用於定義環境變數的)來定義Pod的引數,包括ConfigMaps和Secrets。在引數中,環境變數以”$(VAR)“的格式出現。
3、Pod的基本操作
3.1 建立Pod
按照Kubernetes的設計,Pod一般不獨立進行建立,這是因為獨立建立的Pod沒有自愈能力,也就說在Pod異常終止後,無法進行自動重啟和重新排程。
1) 通過執行kubectl create -f命令建立名為nginx的部署和Pod:
$ kubectl create -f nginx.yml
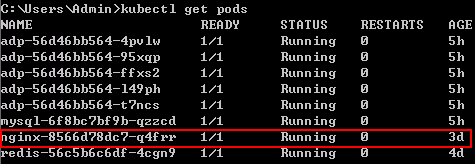
2)通過執行kubectl get pods命令,可以看到在Kubernetes中運行了的nginx的Pod:
$ kubectl get pods
3.2 檢視Pod資訊
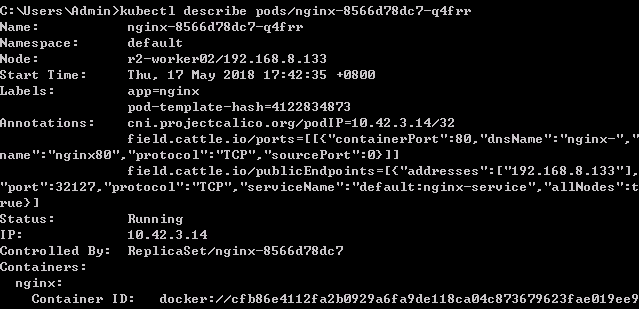
在Pod被創建出來以後,可以通過如下的命令檢視特定Pod的資訊:
$ kubectl describe pods/nginx-8566d78dc7-q4frr
3.3 終止Pod
在叢集中,Pod代表著執行的程序,但不再需要這些程序時,如何優雅的終止這些程序是非常重要。以防止在Pod被暴力刪除時,沒有對Pod相關的資訊進行必要的清除。當用戶請求刪除一個Pod時,Kubernetes將會發送一個終止(TERM)訊號給每個容器,一旦過了優雅期,殺掉(KILL)訊號將會被髮送,並通過API server刪除Pod。可以通過kubectl delete pod/{Pod名稱} -n {名稱空間名稱}刪除特定的Pod,一個終止Pod的流程如下:
1) 使用者可以通過kubectl、dashboard等傳送一個刪除Pod的命令,預設優雅的退出時間為30秒;
2)更新API server中Pod的優雅時間,超過該時間的Pod會被認為死亡;
3)在客戶端命令列中,此Pod的狀態顯示為”Terminating(退出中)”;
4)(與第3步同時)當Kubelet檢查到Pod的狀態退出中的時候,它將開始關閉Pod的流程:
-
- 如果該Pod定義了一個停止前的鉤子(preStop hook),其會在Pod內部被呼叫。如果超出優雅退出時間,鉤子仍然還在執行,就會對第2步的優雅時間進行一個小的延長(一般為2秒)
- 傳送TERM的訊號給Pod中的程序
5)(與第3步同時進行)從服務的端點列表中刪除Pod,對於副本控制器來說,此Pod將不再被認為是執行著的Pod的一部分。緩慢關閉的pod可以繼續對外服務,直到負載均衡器將其移除。
6.)當超過優雅的退出時間,在Pod中任何正在執行的程序都會被髮送被殺死。
7)Kubelet完成Pod的刪除,並將優雅的退出時間設定為0。此時會將Pod刪除,在客戶端將不可見。
在預設情況下,Kubernetes叢集所有的刪除操作的優雅退出時間都為30秒。kubectl delete命令支援–graceperiod=的選項,以支援使用者來設定優雅退出的時間。0表示刪除立即執行,即立即從API中刪除現有的pod,同時一個新的pod會被建立。實際上,就算是被設定了立即結束的的Pod,Kubernetes仍然會給一個很短的優雅退出時間段,才會開始強制將其殺死。
4、Pod的生命週期
Pod的生命週期包括:從Pod被建立、並排程到Node中、以及Pod成功或失敗的終止。Pod的階段是一個簡單的、高層次的Pod所處在生命週期的概述。在Pod的生命週期中,有如下的幾個狀態:
- Pending: Pod已經被Kubernetes系統接受,但是還有一個或者多個容器映象未被建立。這包括Pod正在被排程和從網路上下載映象的時間。
- Running: Pod已經被繫結到了一個Node,所有的容器也已經被建立。至少有一個容器已經在執行,或者在啟動或者重新啟動的過程中。
- Succeeded: 在Pod中的所有的容器都已經被成功的終止,並且不會再重啟。
- Failed: 在Pod中所有容器都已經被終止,並且至少有一個容器是非正常終止的。即,容器以非零狀態退出或者被系統強行終止的。
- Unknown: 由於某些原因,Pod不能被獲取,典型的情況是在與Pod的主機進行通訊中發生了失敗。
在Pod的規格中有一個restartPolicy屬性,它的值包括:Always, OnFailure和Never。
- Always:當容器終止退出後,總是會重啟容器,這是預設值;
- OnFailure:只有在容器非正常退出時,才會重啟容器。
- Never:不管容器是否正常退出,都不再重啟容器。
5、參考材料
作者簡介:
季向遠,北京神舟航天軟體技術有限公司產品經理。本文版權歸原作者所有。