
storm acker 機制詳解
阿新 • • 發佈:2018-12-27
首先來看一下什麼叫做記錄級容錯?storm允許使用者在spout中發射一個新的源tuple時為其指定一個message id, 這個message id可以是任意的object物件。多個源tuple可以共用一個message id,表示這多個源 tuple對使用者來說是同一個訊息單元。storm中記錄級容錯的意思是說,storm會告知使用者每一個訊息單元是否在指定時間內被完全處理了。那什麼叫做完全處理呢,就是該message id繫結的源tuple及由該源tuple後續生成的tuple經過了topology中每一個應該到達的bolt的處理。舉個例子。在圖4-1中,在spout由message 1繫結的tuple1和tuple2經過了bolt1和bolt2的處理生成兩個新的tuple,並最終都流向了bolt3。當這個過程完成處理完時,稱message 1被完全處理了。
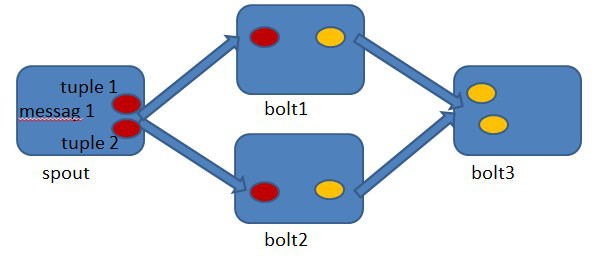
圖4-1
在storm的topology中有一個系統級元件,叫做acker。這個acker的任務就是追蹤從spout中流出來的每一個message id繫結的若干tuple的處理路徑,如果在使用者設定的最大超時時間內這些tuple沒有被完全處理,那麼acker就會告知spout該訊息處理失敗了,相反則會告知spout該訊息處理成功了。在剛才的描述中,我們提到了”記錄tuple的處理路徑”,如果曾經嘗試過這麼做的同學可以仔細地思考一下這件事的複雜程度。但是storm中卻是使用了一種非常巧妙的方法做到了。在說明這個方法之前,我們來複習一個數學定理。
A xor A = 0.
A xor B…xor B xor A = 0,其中每一個操作數出現且僅出現兩次。
storm中使用的巧妙方法就是基於這個定理。具體過程是這樣的:在spout中系統會為使用者指定的message id生成一個對應的64位整數,作為一個root id。root id會傳遞給acker及後續的bolt作為該訊息單元的唯一標識。同時無論是spout還是bolt每次新生成一個tuple的時候,都會賦予該tuple一個64位的整數的id。Spout發射完某個message id對應的源tuple之後,會告知acker自己發射的root id及生成的那些源tuple的id。而bolt呢,每次接受到一個輸入tuple處理完之後,也會告知acker自己處理的輸入tuple的id及新生成的那些tuple的id。Acker只需要對這些id做一個簡單的異或運算,就能判斷出該root id對應的訊息單元是否處理完成了。下面通過一個圖示來說明這個過程。
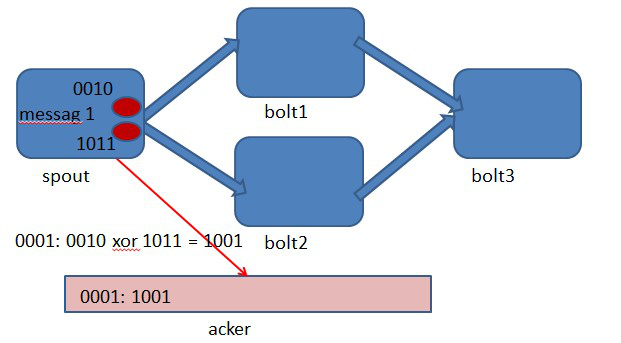
圖4-2 spout中繫結message 1生成了兩個源tuple,id分別是0010和1011.
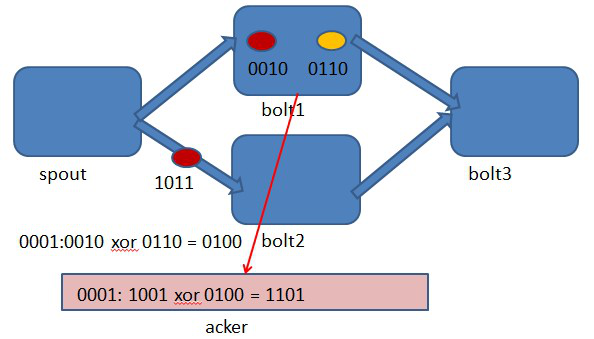
圖4-3 bolt1處理tuple 0010時生成了一個新的tuple,id為0110.
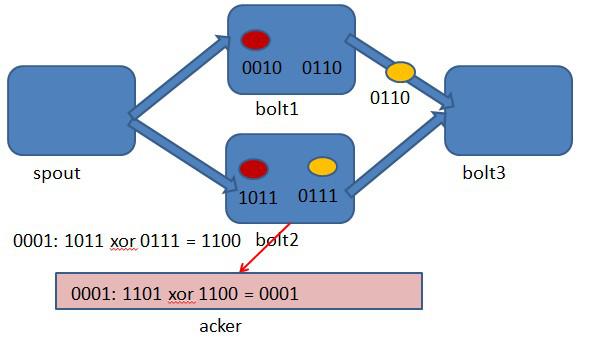
圖4-4 bolt2處理tuple 1011時生成了一個新的tuple,id為0111.
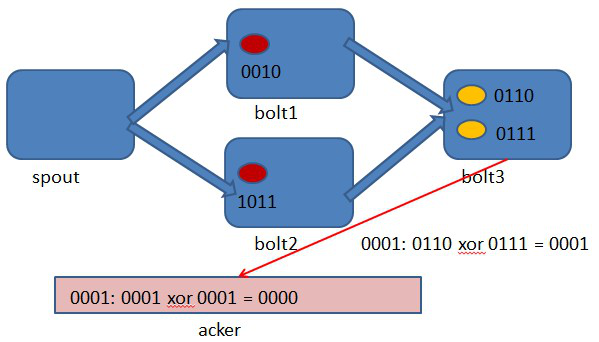
圖4-5 bolt3中接收到tuple 0110和tuple 0111,沒有生成新的tuple.
可能有些細心的同學會發現,容錯過程存在一個可能出錯的地方,那就是,如果生成的tuple id並不是完全各異的,acker可能會在訊息單元完全處理完成之前就錯誤的計算為0。這個錯誤在理論上的確是存在的,但是在實際中其概率是極低極低的,完全可以忽略。