
[K8s 1.9實踐]Kubeadm 1.9 HA 高可用 叢集 本地離線映象部署_Kubernetes中文社群
阿新 • • 發佈:2018-12-27
Kubeadm HA 1.9 高可用 叢集 本地離線部署

k8s介紹
- k8s 發展速度很快,目前很多大的公司容器叢集都基於該專案,如京東,騰訊,滴滴,瓜子二手車,北森等等。

- kubernetes1.9版本釋出2017年12月15日,每是那三個月一個迭代, Workloads API成為穩定版本,這消除了很多潛在使用者對於該功能穩定性的擔憂。還有一個重大更新,就是測試支援了Windows了,這打開了在kubernetes中執行Windows工作負載的大門。
- CoreDNS alpha可以使用標準工具來安裝CoreDNS
- kube-proxy的IPVS模式進入beta版,為大型叢集提供更好的可擴充套件性和效能。
- kube-router的網路外掛支援,更方便進行路由控制,釋出,和安全策略管理
k8s 核心架構

如架構圖
- k8s 高可用2個核心 ==apiserver master== and ==etcd==
- ==apiserver master==:(需高可用)叢集核心,叢集API介面、叢集各個元件通訊的中樞;叢集安全控制;
- ==etcd== :(需高可用)叢集的資料中心,用於存放叢集的配置以及狀態資訊,非常重要,如果資料丟失那麼叢集將無法恢復;因此高可用叢集部署首先就是etcd是高可用叢集;
- kube-scheduler:排程器 (內部自選舉)叢集Pod的排程中心;預設kubeadm安裝情況下–leader-elect引數已經設定為true,保證master叢集中只有一個kube-scheduler處於活躍狀態;
- kube-controller-manager: 控制器 (內部自選舉)叢集狀態管理器,當叢集狀態與期望不同時,kcm會努力讓叢集恢復期望狀態,比如:當一個pod死掉,kcm會努力新建一個pod來恢復對應replicas set期望的狀態;預設kubeadm安裝情況下–leader-elect引數已經設定為true,保證master叢集中只有一個kube-controller-manager處於活躍狀態;
- kubelet: agent node註冊apiserver
- kube-proxy: 每個node上一個,負責service vip到endpoint pod的流量轉發,老版本主要通過設定iptables規則實現,新版1.9基於kube-proxy-lvs 實現
部署示意圖
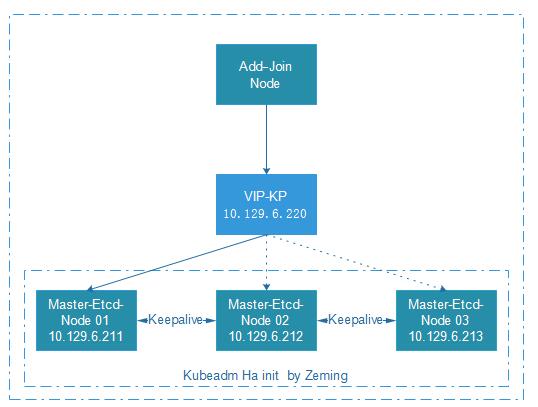
- 叢集ha方案,我們力求簡單,使用keepalive 監聽一個vip來實現,(當節點不可以後,會有vip漂移的切換時長,取決於我們設定timeout切換時長,測試會有10s空檔期,如果對高可用更高要求 可以用lvs或者nginx做 4層lb負載 更佳完美,我們力求簡單夠用,可接受10s的api不可用)
部署環境
最近在部署k8s 1.9叢集遇到一些問題,整理記錄,或許有助需要的朋友。
因為kubeadm 簡單便捷,所以叢集基於該專案部署,目前bete版本不支援ha部署,github說2018年預計釋出ha 版本,可我們等不及了 呼之慾來。。。| 環境 | 版本 |
|---|---|
| Centos | CentOS Linux release 7.3.1611 (Core) |
| Kernel | Linux etcd-host1 3.10.0-514.el7.x86_64 |
| kubectl | v1.9.0 |
| kubeadmin | v1.9.0 |
| docker | 1.12.6 |
| docker localre | devhub.beisencorp.com |
| 主機名稱 | 相關資訊 | 備註 |
|---|---|---|
| etcd-host1 | 10.129.6.211 | master和etcd |
| etcd-host2 | 10.129.6.212 | master和etcd |
| etcd-host3 | 10.129.6.213 | master和etcd |
| Vip-keepalive | 10.129.6.220 | vip用於高可用 |
環境部署 (我們使用本地離線映象)
環境預初始化
- Centos Mini安裝 每臺機器root
- 設定機器名
hostnamectl set-hostname etcd-host1- 停防火牆
systemctl stop firewalld
systemctl disable firewalld
systemctl disable firewalld- 關閉Swap
swapoff -a
sed 's/.*swap.*/#&/' /etc/fstab- 關閉防火牆
systemctl disable firewalld && systemctl stop firewalld && systemctl status firewalld
- 關閉Selinux
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config
getenforce- 增加DNS
echo nameserver 114.114.114.114>>/etc/resolv.conf- 設定核心
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl -p /etc/sysctl.conf
#若問題
執行sysctl -p 時出現:
sysctl -p
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-ip6tables: No such file or directory
sysctl: cannot stat /proc/sys/net/bridge/bridge-nf-call-iptables: No such file or directory
解決方法:
modprobe br_netfilter
ls /proc/sys/net/bridge配置keepalived
- VIP Master 通過控制VIP 來HA高可用(常規方案)
- 到目前為止,三個master節點 相互獨立執行,互補干擾. kube-apiserver作為核心入口, 可以使用keepalived 實現高可用, kubeadm join暫時不支援負載均衡的方式,所以我們
- 安裝
yum install -y keepalived- 配置keepalived.conf
cat >/etc/keepalived/keepalived.conf <<EOL
global_defs {
router_id LVS_k8s
}
vrrp_script CheckK8sMaster {
script "curl -k https://10.129.6.220:6443"
interval 3
timeout 9
fall 2
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens32
virtual_router_id 61
# 主節點權重最高 依次減少
priority 120
advert_int 1
#修改為本地IP
mcast_src_ip 10.129.6.211
nopreempt
authentication {
auth_type PASS
auth_pass sqP05dQgMSlzrxHj
}
unicast_peer {
#註釋掉本地IP
#10.129.6.211
10.129.6.212
10.129.6.213
}
virtual_ipaddress {
10.129.6.220/24
}
track_script {
CheckK8sMaster
}
}
EOL- 啟動
systemctl enable keepalived && systemctl restart keepalived
- 結果
[[email protected] k8s]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availabilitymonitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Fri 2018-01-19 10:27:58 CST; 8h ago
Main PID: 1158 (keepalived)
CGroup: /system.slice/keepalived.service
├─1158 /usr/sbin/keepalived -D
├─1159 /usr/sbin/keepalived -D
└─1161 /usr/sbin/keepalived -D
Jan 19 10:28:00 etcd-host1 Keepalived_vrrp[1161]: Sending gratuitous ARP on ens32 for 10.129.6.220
Jan 19 10:28:05 etcd-host1 Keepalived_vrrp[1161]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens32 for 10.129.6.220- 依次配置 其他2臺從節點master 配置 修改對應節點 ip
- master01 priority 120
- master02 priority 110
- master03 priority 100
Etcd https 叢集部署
Etcd 環境準備
#機器名稱
etcd-host1:10.129.6.211
etcd-host2:10.129.6.212
etcd-host3:10.129.6.213
#部署環境變數
export NODE_NAME=etcd-host3 #當前部署的機器名稱(隨便定義,只要能區分不同機器即可)
export NODE_IP=10.129.6.213 # 當前部署的機器 IP
export NODE_IPS="10.129.6.211 10.129.6.212 10.129.6.213" # etcd 叢集所有機器 IP
# etcd 叢集間通訊的IP和埠
export ETCD_NODES=etcd-host1=https://10.129.6.211:2380,etcd-host2=https://10.129.6.212:2380,etcd-host3=https://10.129.6.213:2380
Etcd 證書建立(我們使用https方式)
建立 CA 證書和祕鑰
- 安裝cfssl, CloudFlare 的 PKI 工具集 cfssl 來生成 Certificate Authority (CA) 證書和祕鑰檔案
- 如果不希望將cfssl工具安裝到部署主機上,可以在其他的主機上進行該步驟,生成以後將證書拷貝到部署etcd的主機上即可。本教程就是採取這種方法,在一臺測試機上執行下面操作。
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
chmod +x cfssl_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
chmod +x cfssljson_linux-amd64
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl-certinfo_linux-amd64
mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo生成ETCD的TLS 祕鑰和證書
- 為了保證通訊安全,客戶端(如 etcdctl) 與 etcd 叢集、etcd 叢集之間的通訊需要使用 TLS 加密,本節建立 etcd TLS 加密所需的證書和私鑰。
- 建立 CA 配置檔案:
cat > ca-config.json <<EOF { "signing": { "default": { "expiry": "8760h" }, "profiles": { "kubernetes": { "usages": [ "signing", "key encipherment", "server auth", "client auth" ], "expiry": "8760h" } } } } EOF - ==ca-config.json==:可以定義多個 profiles,分別指定不同的過期時間、使用場景等引數;後續在簽名證書時使用某個 profile;
- ==signing==:表示該證書可用於簽名其它證書;生成的 ca.pem 證書中 CA=TRUE;
- ==server auth==:表示 client 可以用該 CA 對 server 提供的證書進行驗證;
- ==client auth==:表示 server 可以用該 CA 對 client 提供的證書進行驗證;
cat > ca-csr.json <<EOF { "CN": "kubernetes", "key": { "algo": "rsa", "size": 2048 }, "names": [ { "C": "CN", "ST": "BeiJing", "L": "BeiJing", "O": "k8s", "OU": "System" } ] } EOF - “CN”:Common Name,kube-apiserver 從證書中提取該欄位作為請求的使用者名稱 (User Name);瀏覽器使用該欄位驗證網站是否合法;
- “O”:Organization,kube-apiserver 從證書中提取該欄位作為請求使用者所屬的組 (Group);
- ==生成 CA 證書和私鑰==:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
ls ca*
==建立 etcd 證書籤名請求:==
cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"10.129.6.211",
"10.129.6.212",
"10.129.6.213"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF- hosts 欄位指定授權使用該證書的 etcd 節點 IP;
- 每個節點IP 都要在裡面 或者 每個機器申請一個對應IP的證書
生成 etcd 證書和私鑰:
cfssl gencert -ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
ls etcd*
mkdir -p /etc/etcd/ssl
cp etcd.pem etcd-key.pem ca.pem /etc/etcd/ssl/
#
#其他node
rm -rf /etc/etcd/ssl/*
scp -r /etc/etcd/ssl [email protected]:/etc/etcd/
scp -r [email protected]10.129.6.211:/root/k8s/etcd/etcd-v3.3.0-rc.1-linux-amd64.tar.gz /root
將生成好的etcd.pem和etcd-key.pem以及ca.pem三個檔案拷貝到目標主機的/etc/etcd/ssl目錄下。
下載二進位制安裝檔案
wget http://github.com/coreos/etcd/releases/download/v3.1.10/etcd-v3.1.10-linux-amd64.tar.gz
tar -xvf etcd-v3.1.10-linux-amd64.tar.gz
mv etcd-v3.1.10-linux-amd64/etcd* /usr/local/bin建立 etcd 的 systemd unit 檔案
mkdir -p /var/lib/etcd # 必須先建立工作目錄
cat > etcd.service <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/local/bin/etcd \\
--name=${NODE_NAME} \\
--cert-file=/etc/etcd/ssl/etcd.pem \\
--key-file=/etc/etcd/ssl/etcd-key.pem \\
--peer-cert-file=/etc/etcd/ssl/etcd.pem \\
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \\
--trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--peer-trusted-ca-file=/etc/etcd/ssl/ca.pem \\
--initial-advertise-peer-urls=https://${NODE_IP}:2380 \\
--listen-peer-urls=https://${NODE_IP}:2380 \\
--listen-client-urls=https://${NODE_IP}:2379,http://127.0.0.1:2379 \\
--advertise-client-urls=https://${NODE_IP}:2379 \\
--initial-cluster-token=etcd-cluster-0 \\
--initial-cluster=${ETCD_NODES} \\
--initial-cluster-state=new \\
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF- 指定 etcd 的工作目錄和資料目錄為 /var/lib/etcd,需在啟動服務前建立這個目錄;
- 為了保證通訊安全,需要指定 etcd 的公私鑰(cert-file和key-file)、Peers 通訊的公私鑰和 CA 證書(peer-cert-file、peer-key-file、peer-trusted-ca-file)、客戶端的CA證書(trusted-ca-file);
- –initial-cluster-state 值為 new 時,–name 的引數值必須位於 –initial-cluster 列表中;
啟動 etcd 服務
mv etcd.service /etc/systemd/system/
systemctl daemon-reload
systemctl enable etcd
systemctl start etcd
systemctl status etcd驗證服務
etcdctl \
--endpoints=https://${NODE_IP}:2379 \
--ca-file=/etc/etcd/ssl/ca.pem \
--cert-file=/etc/etcd/ssl/etcd.pem \
--key-file=/etc/etcd/ssl/etcd-key.pem \
cluster-health預期結果:
[[email protected] ~]# etcdctl --endpoints=https://${NODE_IP}:2379 --ca-file=/etc/etcd/ssl/ca.pem --cert-file=/etc/etcd/ssl/etcd.pem --key-file=/etc/etcd/ssl/etcd-key.pem cluster-health
member 18699a64c36a7e7b is healthy: got healthy result from https://10.129.6.213:2379
member 5dbd6a0b2678c36d is healthy: got healthy result from https://10.129.6.211:2379
member 6b1bf02f85a9e68f is healthy: got healthy result from https://10.129.6.212:2379
cluster is healthy若有失敗 或 重新配置
systemctl stop etcd
rm -Rf /var/lib/etcd
rm -Rf /var/lib/etcd-cluster
mkdir -p /var/lib/etcd
systemctl start etcdk8s 安裝
提取k8s rpm 包
- 預設由於某某出海問題
- 我們離線匯入下rpm 倉庫
- 安裝官方YUM 倉庫
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://yum.kubernetes.io/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=0
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF安裝kubeadm kubectl cni
- 下載映象(自行搬梯子先獲取rpm)
mkdir -p /root/k8s/rpm
cd /root/k8s/rpm
#安裝同步工具
yum install -y yum-utils
#同步本地映象
yumdownloader kubelet kubeadm kubectl kubernetes-cni docker
scp [email protected]129.6.224:/root/k8s/rpm/* /root/k8s/rpm
- 離線安裝
mkdir -p /root/k8s/rpm
scp [email protected]129.6.211:/root/k8s/rpm/* /root/k8s/rpm
yum install /root/k8s/rpm/*.rpm -y
- 啟動k8s
#restart
systemctl enable docker && systemctl restart docker
systemctl enable kubelet && systemctl restart kubelet映象獲取方法
- 加速器獲取 gcr.io k8s映象 ,匯出,匯入映象 或 上傳本地倉庫
#國內可以使用daocloud加速器下載相關映象,然後通過docker save、docker load把本地下載的映象放到kubernetes叢集的所在機器上,daocloud加速器連結如下:
https://www.daocloud.io/mirror#accelerator-doc
#pull 獲取
docker pull gcr.io/google_containers/kube-proxy-amd64:v1.9.0
#匯出
mkdir -p docker-images
docker save -o docker-images/kube-proxy-amd64 gcr.io/google_containers/kube-proxy-amd64:v1.9.0
#匯入
docker load -i /root/kubeadm-ha/docker-images/kube-proxy-amd64- 代理或vpn獲取 gcr.io k8s鏡 ,匯出,匯入映象 或 上傳本地倉庫
自謀生路,天機屋漏kubelet 指定本地映象
kubelet 修改 配置以使用本地自定義pause映象
devhub.beisencorp.com/google_containers/pause-amd64:3.0 替換你的環境映象
cat > /etc/systemd/system/kubelet.service.d/20-pod-infra-image.conf <<EOF
[Service]
Environment="KUBELET_EXTRA_ARGS=--pod-infra-container-image=devhub.beisencorp.com/google_containers/pause-amd64:3.0"
EOF
systemctl daemon-reload
systemctl restart kubeletKubeadm Init 初始化
- 我們使用config 模板方式來初始化叢集,便於我們指定etcd 叢集
- devhub.beisencorp.com 使我們的 測試映象倉庫 可以改成自己或者手動匯入每個機器映象
cat <<EOF > config.yaml
apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
etcd:
endpoints:
- https://10.129.6.211:2379
- https://10.129.6.212:2379
- https://10.129.6.213:2379
caFile: /etc/etcd/ssl/ca.pem
certFile: /etc/etcd/ssl/etcd.pem
keyFile: /etc/etcd/ssl/etcd-key.pem
dataDir: /var/lib/etcd
networking:
podSubnet: 10.244.0.0/16
kubernetesVersion: 1.9.0
api:
advertiseAddress: "10.129.6.220"
token: "b99a00.a144ef80536d4344"
tokenTTL: "0s"
apiServerCertSANs:
- etcd-host1
- etcd-host2
- etcd-host3
- 10.129.6.211
- 10.129.6.212
- 10.129.6.213
- 10.129.6.220
featureGates:
CoreDNS: true
imageRepository: "devhub.beisencorp.com/google_containers"
EOF- 初始化叢集
kubeadm init --config config.yaml - 結果
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
as root:
kubeadm join --token b99a00.a144ef80536d4344 10.129.6.220:6443 --discovery-token-ca-cert-hash sha256:ebc2f64e9bcb14639f26db90288b988c90efc43828829c557b6b66bbe6d68dfa- 檢視node
[[email protected] k8s]# kubectl get node
NAME STATUS ROLES AGE VERSION
etcd-host1 noReady master 5h v1.9.0
[[email protected] k8s]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"} - 問題記錄
如果使用kubeadm初始化叢集,啟動過程可能會卡在以下位置,那麼可能是因為cgroup-driver引數與docker的不一致引起
[apiclient] Created API client, waiting for the control plane to become ready
journalctl -t kubelet -S '2017-06-08'檢視日誌,發現如下錯誤
error: failed to run Kubelet: failed to create kubelet: misconfiguration: kubelet cgroup driver: "systemd"
需要修改KUBELET_CGROUP_ARGS=--cgroup-driver=systemd為KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
#Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=systemd"
Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"
systemctl daemon-reload && systemctl restart kubelet安裝網路元件 podnetwork
- 我們選用kube-router
wget https://github.com/cloudnativelabs/kube-router/blob/master/daemonset/kubeadm-kuberouter.yaml
kubectl apply -f kubeadm-kuberouter.yaml- 結果
[[email protected] k8s]# kubectl get po --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-546545bc84-zc5dx 1/1 Running 0 6h
kube-system kube-apiserver-etcd-host1 1/1 Running 0 6h
kube-system kube-controller-manager-etcd-host1 1/1 Running 0 6h
kube-system kube-proxy-pfj7x 1/1 Running 0 6h
kube-system kube-router-858b7 1/1 Running 0 37m
kube-system kube-scheduler-etcd-host1 1/1 Running 0 6h
[[email protected] k8s]# 部署其他Master 節點
- 拷貝master01 配置 master02 master03
#拷貝pki 證書
mkdir -p /etc/kubernetes/pki
scp -r [email protected]129.6.211:/etc/kubernetes/pki /etc/kubernetes
#拷貝初始化配置
scp -r [email protected]129.6.211://root/k8s/config.yaml /etc/kubernetes/config.yaml- 初始化 master02 master03
#初始化
kubeadm init --config /etc/kubernetes/config.yaml 部署成功 驗證結果
為了測試我們把master 設定為 可部署role
預設情況下,為了保證master的安全,master是不會被排程到app的。你可以取消這個限制通過輸入:
kubectl taint nodes --all node-role.kubernetes.io/master-錄製終端驗證 結果

-驗證
[[email protected] k8s]$ kubectl get node
NAME STATUS ROLES AGE VERSION
etcd-host1 Ready master 6h v1.9.0
etcd-host2 Ready master 5m v1.9.0
etcd-host3 Ready master 49s v1.9.0
[[email protected] k8s]$ kubectl get po --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default nginx01-d87b4fd74-2445l 1/1 Running 0 1h
default nginx01-d87b4fd74-7966r 1/1 Running 0 1h
default nginx01-d87b4fd74-rcbhw 1/1 Running 0 1h
kube-system coredns-546545bc84-zc5dx 1/1 Running 0 3d
kube-system kube-apiserver-etcd-host1 1/1 Running 0 3d
kube-system kube-apiserver-etcd-host2 1/1 Running 0 3d
kube-system kube-apiserver-etcd-host3 1/1 Running 0 3d
kube-system kube-controller-manager-etcd-host1 1/1 Running 0 3d
kube-system kube-controller-manager-etcd-host2 1/1 Running 0 3d
kube-system kube-controller-manager-etcd-host3 1/1 Running 0 3d
kube-system kube-proxy-gk95d 1/1 Running 0 3d
kube-system kube-proxy-mrzbq 1/1 Running 0 3d
kube-system kube-proxy-pfj7x 1/1 Running 0 3d
kube-system kube-router-bbgpq 1/1 Running 0 3h
kube-system kube-router-v2jbh 1/1 Running 0 3h
kube-system kube-router-w4cbb 1/1 Running 0 3h
kube-system kube-scheduler-etcd-host1 1/1 Running 0 3d
kube-system kube-scheduler-etcd-host2 1/1 Running 0 3d
kube-system kube-scheduler-etcd-host3 1/1 Running 0 3d
[[email protected] k8s]$主備測試
- 關閉 主節點 master01 觀察切換到 master02 機器
- master03 一直不管獲取node資訊 測試高可用
while true; do sleep 1; kubectl get node;date; done觀察主備VIP切換過程
#觀察當Master01主節點關閉後,被節點VIP狀態 BACKUP 切換到 MASTER
[[email protected] net.d]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2018-01-22 13:54:17 CST; 21s ago
Jan 22 13:54:17 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Transition to MASTER STATE
Jan 22 13:54:17 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Received advert with higher priority 120, ours 110
Jan 22 13:54:17 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Entering BACKUP STATE
#切換到 MASTER
[[email protected] net.d]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2018-01-22 13:54:17 CST; 4min 6s ago
Jan 22 14:03:02 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Transition to MASTER STATE
Jan 22 14:03:03 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) Entering MASTER STATE
Jan 22 14:03:03 etcd-host2 Keepalived_vrrp[15908]: VRRP_Instance(VI_1) setting protocol VIPs.
Jan 22 14:03:03 etcd-host2 Keepalived_vrrp[15908]: Sending gratuitous ARP on ens32 for 10.129.6.220
驗證叢集高可用
#觀察 master01 關機後狀態變成NotReady
[[email protected] ~]# while true; do sleep 1; kubectl get node;date; done
Tue Jan 22 14:03:16 CST 2018
NAME STATUS ROLES AGE VERSION
etcd-host1 Ready master 19m v1.9.0
etcd-host2 Ready master 3d v1.9.0
etcd-host3 Ready master 3d v1.9.0
Tue Jan 22 14:03:17 CST 2018
NAME STATUS ROLES AGE VERSION
etcd-host1 NotReady master 19m v1.9.0
etcd-host2 Ready master 3d v1.9.0
etcd-host3 Ready master 3d v1.9.0參觀文件
#k8s 官方文件
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-init/
# kubeadm ha 專案文件
https://github.com/indiketa/kubeadm-ha
# kubespray 之前的kargo ansible專案
https://github.com/kubernetes-incubator/kubespray/blob/master/docs/ha-mode.md
# 若轉載請註明出處 By Zeming 若有描述不清楚 請留言指出
http://xuzeming.top/2018/01/19/K8s-1-9%E5%AE%9E%E8%B7%B5-Kubeadm-HA-1-9-%E9%AB%98%E5%8F%AF%E7%94%A8-%E9%9B%86%E7%BE%A4-%E6%9C%AC%E5%9C%B0%E7%A6%BB%E7%BA%BF%E9%83%A8%E7%BD%B2/