
當深度學習遇到K8s_Kubernetes中文社群
編者注:本文由來自百度深度學習團隊和CoreOS的Etcd團隊共同編寫

PaddlePaddle是什麼
PaddlePaddle是一款由百度原生打造的易用、高效、靈活、可擴充套件的深度學習平臺,從2014年開始應用在百度各個涉及深度學習的產品上。
PaddlePaddle支援了百度搜索引擎、線上廣告、問答(Q&A)以及系統安全等15個產品,創造了超過50項革新。
2016年9月,百度開源了PaddlePaddle,它很快就吸引了百度以外的很多貢獻者。
為什麼選擇K8s
PaddlePaddle的設計思路是獨立於計算基礎設施的平臺。使用者可以在Hadoop、Spark、Mesos、Kubernetes等各個基礎設施上執行它。其中靈活、高效、且擁有豐富特性的Kubernetes深深地吸引了我們。
當我們在百度各個產品上應用PaddlePaddle時,我們注意到兩種使用場景——科研和產品。科研資料不常改變,聚焦在快速地進行實驗以達到期望的科學計量。產品資料則會頻繁變動,它通常是來自Web服務的日誌訊息。
一個成功的深度學習專案包含了科研和資料處理管道(data processing pipeline),並且有許多需要調整的引數。很多工程師同時在這個專案的各個部分上工作。
為了保證這個專案易於管理,並且有效地利用了硬體資源,我們希望它的每個部分都執行在同一個基礎設施平臺上。
這個平臺應該提供:
- 容錯。它應該把管道的每個階段都抽象為服務,這需要冗餘的大量程序提供高吞吐和健壯性。
- 自動擴容。在白天有許多活躍的使用者,平臺應該擴充套件線上服務,而到了晚上,平臺擁有更多資源,正好進行深度學習實驗。
- 任務打包和隔離。它可以分配PaddlePaddle訓練程序所需的GPU、一個需要大量記憶體的Web後端以及為了提高硬體資源利用率,需要對同一個節點進行磁碟IO的CephFS程序。
我們需要的是一個可以執行深度學習系統、Web伺服器(例如: nginx)、日誌採集器(例如: fluentd)的平臺、分散式佇列服務(例如: Kafka)、日誌聚合以及其他在同個叢集上利用Storm、Spark、Hadoop、MapReduce等資料處理器的平臺。我們想把所有的任務(job)——線上的和離線的,生產的和實驗的———執行在同一個叢集上。所以當不同的任務需要不同的硬體資源時,我們會最大化利用整個叢集資源。
由於虛擬機器(VMs)帶來的負載跟我們的效率和資源目標背道而馳,所以我們選擇基於容器的解決方案。
在對不同容器解決方案的研究基礎上,Kubernetes是最符合預期的方案。
K8s上的分散式訓練
PaddlePaddle支援分散式本地訓練。在PaddlePaddle叢集裡有兩種角色:Parameter Server和Trainer。每個paramenter server程序擁有全域性模型的一個分片(shard)。每個trainer擁有該模型的本地拷貝,並且使用本地資料來更新這個模型。在訓練過程中,trainers會把模型的更新發送至parameter server,然後由parameter server對這些更新進行聚合,由此實現trainers本地拷貝和全域性模型的同步。
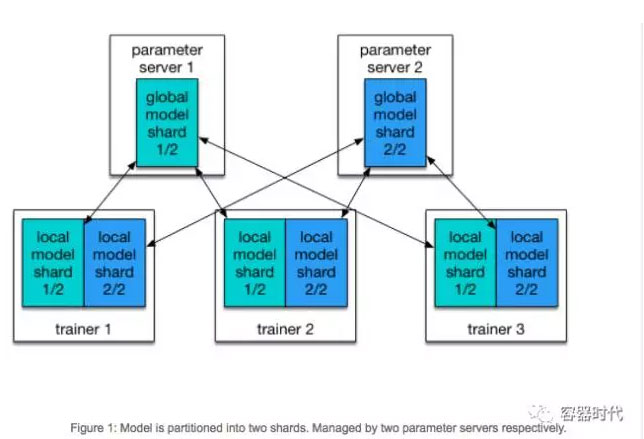
另外一些方法使用一組parameter server在多個節點上佔用大量的CPU和記憶體來維持大型模型。但實踐中,我們通常沒有這麼大的模型,因為鑑於GPU記憶體的限制,處理特大型模型是非常低效的。在我們的配置裡,多個parameter server是主要是為了快速地通訊。假定只有一個parameter server在處理所有的trainer,parameter server會聚合所有trainer的資料併到達瓶頸。在我們的實驗裡,一個實驗性的有效配置包含了相同數量的trainer和parameter server。並且我們通常在同一個節點上執行一對trainer和parameter server。按照下列的Kubernetes任務配置,我們啟動了N個Pods的任務,每個Pod裡都有一對parameter server和trainer程序。
name: PaddlePaddle-cluster-job spec: parallelism: 3 completions: 3 template: metadata: name: PaddlePaddle-cluster-job spec: volumes: - name: jobpath hostPath: path: /home/admin/efs containers: - name: trainer image: your_repo/paddle:mypaddle command: ["bin/bash", "-c", "/root/start.sh"] env: - name: JOB_NAME value: paddle-cluster-job - name: JOB_PATH value: /home/jobpath - name: JOB_NAMESPACE value: default volumeMounts: - name: jobpath mountPath: /home/jobpath restartPolicy: Never
我們可以看到配置裡parallelism和completions都設定為3。那麼這個任務將會同時啟動3個PaddlePaddle Pods,這個任務隨著這3個Pods結束而結束。
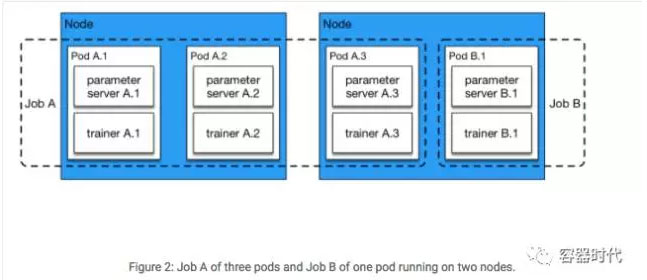
每個Pod的入口(entrypoint)是start.sh。它會從儲存服務上下載資料,所以trainer可以快速地從Pod本地磁碟空間讀到資料。當下載完成後,它執行一個Python指令碼,start_paddle.py,這會啟動parameter server,直到所有Pod的parameter server都可以進行服務時,再啟動每個Pod裡的trainer程序。
這個等待是很有必要的,因為每個trainer都需要與parameter server進行通訊,如圖1所示。Kubernetes API使得每個trainer都可以檢查Pod的狀態,所有Python指令碼可以一直等待,直到所有的parameter server狀態變為”Running”,再觸發訓練過程。
現在,從資料分片到pods/trainers的對映還是靜態的。如果我們運行了N個trainer,我們需要將資料分為N片,並且靜態地把每個分片分配給trainer。我們再一次依賴於Kubernetes API來得到任務裡的Pod列表,這樣我們就可以從1到N實現對pods/trainers的索引了,第i個trainer會讀取第i個數據分片。
訓練資料存放在分散式檔案系統上。在實踐中我們採用了CephFS作為我們叢集上的檔案系統,在AWS上我們使用的是Amazon Elastic File System。如果你對使用Kubernetes叢集執行分散式PaddlePaddle訓練任務感興趣的話,請參考這個教程。
接下來
我們正致力於讓PaddlePaddle可以在Kubernetes上更平滑地執行。
正如你可能注意到的,當前的trainer排程完全依賴於Kubernetes的靜態劃分對映(static partition map)。這個方法非常簡單,但可能會造成一些效率問題。
首先,過慢的或者死亡的trainer會阻塞整個任務。在初始部署之後沒有相應的控制原語或重排程策略。第二,靜態的資源分配。如果Kubernetes擁有比我們使用的還多的資源,我們需要手動改變資源需求。這是一項枯燥的工作,並且跟我們關於效率和利用率的目標也不夠契合。
為了解決上面提到的這些問題,我們添加了一個瞭解Kubernetes API的PaddlePaddle主(master),它可以動態地新增/移除資源容量,並且以一種更加動態的方式向各個trainer分發資料分片。PaddlePaddle使用Etcd作為資料分片和trainer動態對映的容錯儲存。這樣,即使master掛掉了,這個對映也不會丟失。Kubernetes會重啟這個master並且繼續執行任務。
另外一個潛在的提升是更好的PaddlePaddle任務配置。我們的體驗是擁有相同數量的trainer和parameter server這個配置主要來自於特定目的的叢集。這個策略在僅執行PaddlePaddle任務的叢集上高效。然而,這個策略可能在執行多個任務的通用叢集上並不是最優的。
PaddlePaddle trainers可以利用多個GPU來加速計算。GPU在Kubernetes裡目前還不是一級資源(first-class resource)。我們需要半手動地管理GPU。我們樂意與Kubernetes社群一同工作來提高對GPU的支援,讓PaddlePaddle在Kubernetes表現最優。
原文連結
原文作者: Yi Wang, Baidu Research and Xiang Li, CoreOS
原文連結: http://blog.kubernetes.io/2017/02/run-deep-learning-with-paddlepaddle-on-kubernetes.html