
SVM人臉樣本訓練檢測流程
=++++++++++++++++++++++提取 HOG 特徵+++++++++++++++++++++++++=
//樣本矩陣,nImgNum:橫座標是樣本數量。 列數是該 樣本對應的 特徵維數。ex: 樣本是學生,其樣本特徵可以由 身高,體重,年齡 組成,那麼 第二個引數就是 3 啦。
CvMat *data_mat = cvCreateMat( nImgNum, 1764, CV_32FC1 );
1764 是如何計算出來的。
1. 先確定 你 要訓練 以及 檢測 的圖片 的 大小 IplImage* trainImg=cvCreateImage(cvSize(64,64),8,3);
ok 這裡是 64 x 64
2. 確定 HOGDescriptor *hog=new HOGDescriptor(cvSize(64,64),cvSize(16,16),cvSize(8,8),cvSize(8,8),9);
第一個 視窗 大小 設定 為 上面的圖片大小 64 x 64 。
第二個 塊大小 是 16 x 16 的話 [ 額 這個腫麼確定?與前面的 視窗大小有關係 麼? 這是opencv中預設的大小]
第三個 塊block的步進 stride 8 x 8
第四個是 胞元cell大小 8 x 8
第五個是 cell的直方圖的 bin = 9
梯度方向數 nbins
nBins表示在一個胞元(cell)中統計梯度的方向數目,例如nBins=9時,在一個胞元內統計9個方向的梯度直方圖,每個方向為180/9=20度。
每個 cell 有 9 個向量
每個block 有 (16 / 8 ) * (16 / 8) = 2 * 2 = 4 個 cell, 那麼現在就有 4 * 9 = 36 個向量啦
每個 視窗 有多少個 block 呢?
利用公式 (window_size - block_size)/block_stride + 1 對兩個方向進行計算:
( 64 - 16) / 8 + 1 = 7
兩個方向 7 * 7 = 49
so 共有 49* 36 = 1764
//型別矩陣,儲存每個樣本的型別標誌 , 一維,只需要儲存該樣本屬於哪一類即可(只有兩類)
CvMat * res_mat = cvCreateMat( nImgNum, 1, CV_32FC1 );
HOGDescriptor *hog=new HOGDescriptor(cvSize(64,64),cvSize(16,16),cvSize(8,8),cvSize(8,8),9);
// 計算hog特徵
// trainImg是讀入的需要計算特徵的影象,IplImage* trainImg=cvCreateImage(cvSize(64,64),8,3);
//descriptors 是結果陣列 vector<float> descriptors; HOG特徵的維數就是 = descriptors.size 啦,上例中,就是 那個3 啦。
hog->compute(trainImg, descriptors,Size(1,1), Size(0,0));
//計算完成後,把hog特徵儲存到 上面宣告的那個 樣本 矩陣中
// i 是當前處理的第 i 張 圖片, n 從 0 開始 ++ ,從第 0 列 開始儲存。 *iter 是 (vector<float>::iterator iter=descriptors.begin();iter!=descriptors.end();iter++)
cvmSet(data_mat, i, n,*iter);
// 訓練讀入的圖片是有 標籤 的( 知道已知屬於哪一類), 將標籤存入 標籤 矩陣 。i 是當前處理的 圖片 的 編號。 img_catg[i] 是 讀入 的已知的 資料。
cvmSet( res_mat, i, 0, img_catg[i] );
++++++++++++++++++++++++++++++++++開始訓練+++++++++++++++++++++++++++
首先要/新建一個SVM
CvSVM svm = CvSVM();
// 開始訓練~
svm.train( data_mat, res_mat, NULL, NULL, param ); //data_mat 是 上面提取 到的 HOG特徵,儲存 m 個樣本的 n 個特徵, res_mat 是標籤矩陣,m個樣本屬於哪一類,已// 知的。 param 的定義如下:
CvSVMParams param = CvSVMParams( CvSVM::C_SVC, CvSVM::RBF, 10.0, 0.09, 1.0, 10.0, 0.5, 1.0, NULL, criteria );
CvTermCriteria criteria = cvTermCriteria( CV_TERMCRIT_EPS, 1000, FLT_EPSILON );
// 將訓練結果儲存在 xml檔案中
svm.save( "SVM_DATA.xml" );
此階段生成檔案:
SVM_DATA.xml
訓練完成之後,就開始 對 你所需要 的 資料 進行 預測。 這裡預測 當前 圖片 屬於 那一類別。
++++++++++++++++++++++++++++++++++檢測樣本+++++++++++++++++++++++++++
讀入當前要預測的圖片 testImg
將testImg 縮放 至 與 訓練圖片 一樣大小 ,直接存放到 trainImg中
計算讀入的圖片的Hog特徵,
hog->compute(trainImg, descriptors,Size(1,1), Size(0,0)); //呼叫計算函式開始計算
仍用 vector<float> descriptors; 存放結果
建立一個 一行 n 列 的向量。 n 是 特徵的個數 。 就是上面的 3 啊, descriptors.size() 啊。 用來存放 當前要預測的圖片的 特徵
CvMat* SVMtrainMat=cvCreateMat(1,descriptors.size(),CV_32FC1);
// 開始預測
int ret = svm.predict(SVMtrainMat);
ret 返回的是 當前 預測 的 圖片 的 類別。 就是 一開始 讀到 標籤 矩陣 中的 資料。 一般 用 0 or 1 來標示 兩大類別。
可將結果檔案儲存在:
SVM_PREDICT.txt
************************************************Hog詳解********************************************************************
HOG基本概念
在建構函式中,有幾個引數非常重要,分別為winSize(64,128), blockSize(16,16), blockStride(8,8), cellSize(8,8), nbins(9)。在此,用幾個示意圖來表示。
a) 視窗大小winSize
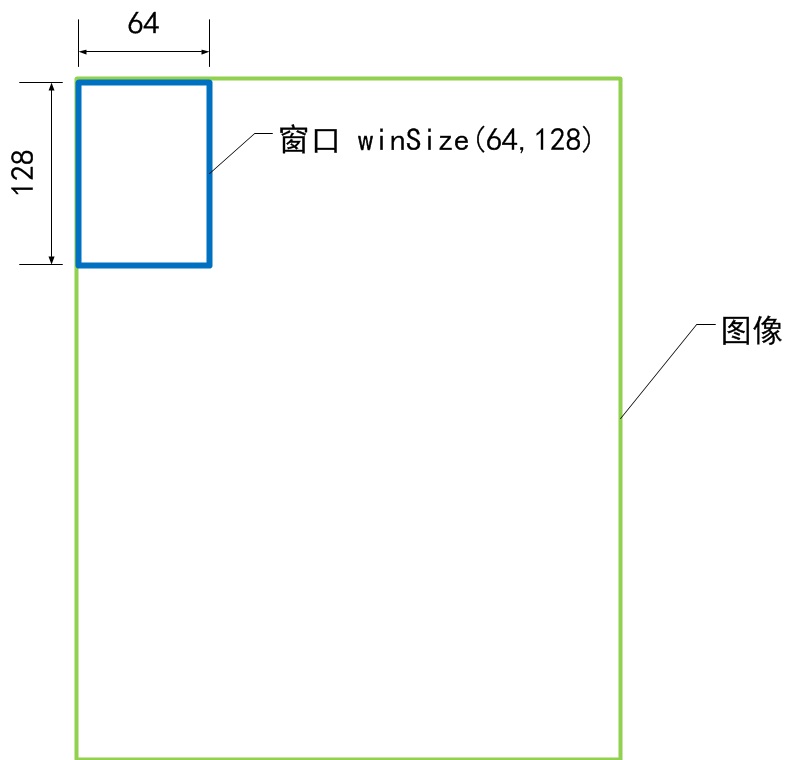
b) 塊大小blockSize

c) 胞元大小cellSize
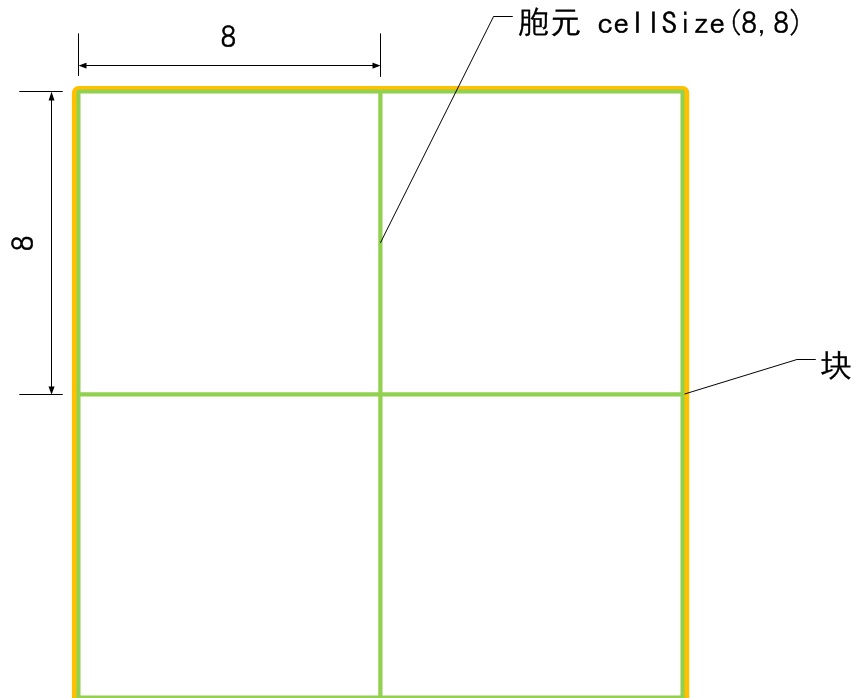
d) 梯度方向數
nbins代表在一個胞元中統計梯度的方向數目。如:nbins=9表示一個胞元內統計9個方向的梯度直方圖。
Hog特徵維數的計算
首先給出一個hog
HOGDescriptor* hog = newHOGDescriptor(cvSize(64, 48), cvSize(8, 6), cvSize(8, 6), cvSize(4, 3), 9);
根據上面的概念可知,cvSize(64,48)表示視窗的大小,cvSize(8, 6)表示塊(block)大小,cvSize(8,6)表示塊滑動增量(blockStride)大小,cvSize(4, 3)表示胞元(cell)大小,9表示每個胞單元中梯度直方圖的數量。
注:輸入的圖片尺寸為640×480。
據此,可知:
一個塊(block)包含A=(blockSize.width/cellSize.width)*(blockSize.height / cellSize.height)個胞元(cell),所以一個塊(block)含有9A個梯度直方圖。按照所給出的資料,可得結果為36。
一個視窗包含B=((windowSize.width-blockSize.width)/(blockStrideSize.width)+1)* ((windowSize.height-blockSize.height)/(blockStrideSize.height)+1)個塊(block),所以一個視窗包含9AB個梯度直方圖。
按照所給出的資料,可得結果為2304。
其次,計算特徵向量hog->compute(trainImg,descriptors, Size(64, 48), Size(0, 0))
此處,trainImg代表輸入的圖片(此處尺寸為640×480),descriptors表示儲存特徵結果的Vector,Size(64,48)表示windows的步進,第四個為padding,用於填充圖片以適應大小。
當padding以預設狀態Size(0,0)出現,滑動視窗window來計算圖片時,
結果不一定為整數。
此時,檢視compute()函式發現,其中有一段程式碼如下:
padding.width = (int)alignSize(std::max(padding.width,0), cacheStride.width);
padding.height = (int)alignSize(std::max(padding.height,0), cacheStride.height);
這段程式碼就是用來將padding的大小來適應stride的大小。
在我的例項中,由於取得數都事先設計好,都是整數。而當若結果不為整數時,則將其取值為比其大的最小整數。如若padding.width計算為7.8時,就取8.
所以一幅640×480的圖片,按照前面的引數,則可以取的特徵數為230400維。